
-
1 导读
-
2 视频讲解1
-
3 视频讲解2
-
4 课程素材
-
5 章节测试
Scrapy框架简介
摘要:框架 自动翻译 post请求
一、Scrapy简介
Scrapy是用Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的优势在于,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
二、安装Scrapy
1.通过pip 安装 Scrapy 框架(进入Python安装目录的Scripts目录,在地址栏输入cmd,进入命令行窗口),执行如下命令:
pip install Scrapy
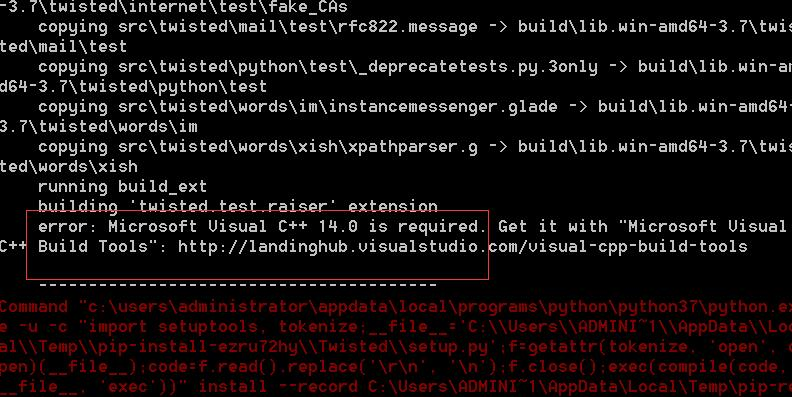
2.使用cmd安装scrapy的时候,如果出现上图的error:
Unable to find vcvarsall.bat 错误:安装vs;
error: Microsoft Visual C++ 14.0 is required错误:安装Visual C++
则需要先安装Microsoft Visual C++14.0.exe,软件的图标如下所示:

3.具体Scrapy安装流程参考(里面有各个平台的安装方法):
http://doc.scrapy.org/en/latest/intro/install.html#intro-install-platform-notes
三、Scrapy架构图
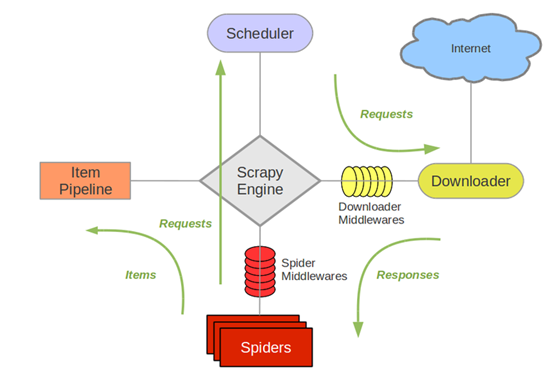
1. Scrapy Engine(引擎):
负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
2. Scheduler(调度器):
它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
3. Downloader(下载器):
负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
4.Spider(爬虫):
它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
5.Item Pipeline(管道):
它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
6.Downloader Middlewares(下载8):
你可以当作是一个可以自定义扩展下载功能的组件。
7.Spider Middlewares(Spider中间件):
你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
四、制作 Scrapy 爬虫
第1步骤:新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
scrapy startproject ScrapyEx
其中, mySpider 为项目名称,可以看到将会创建一个ScrapyEx文件夹.
第2步骤:明确目标 (编写items.py):明确你想要抓取的目标
该文件是由固定代码的(要爬取的页面匹配的字段)
import scrapy
class ScrapyexItem(scrapy.Item): # 要爬取的页面的字段名
字段名1 = scrapy.Field()
字段名2=scrapy.Field()
第3步骤:制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
在Scrapy项目的地址栏输入cmd--进入命令行窗口,输入:scrapy genspider 爬虫模块文件名 要爬取的URL地址
例如:进入ScrapyEx目录,进入命令行窗口,输入命令:
scrapy genspider musicSpider http://www.htqyy.com/
第4步骤:存储内容 (pipelines.py):设计管道存储爬取内容
每个管道代表一个类,管道文件,负责Item的后期处理或保存
class ScrapyexPipeline(object):
def __init__(self):#定义一些需要初始化的参数
self.file=open("music.txt","a") #多次写入,使用a方式写入
#管道每次接收到item后执行的方法
def process_item(self, item, spider):
content=str(item)+"\n"
self.file.write(content)
return item
#这个方法名称是固定的,当爬取结束时执行的方法,只执行一次
def close_spider(self,spider):
print("ending....")
self.spider.close()
第5步骤:编辑seetting.py模块文件
把下面的代码的注释去掉,只有设置了管道的优先级别后,在管道中的数据才会被写入到文件,设置管道的优先级0--1000,数字越小优先级越高。
ITEM_PIPELINES = {
'ScrapyEx.pipelines.ScrapyexPipeline': 300,
}
第6步骤:运行生成的爬虫模块文件
方法一:运行爬虫模块文件musicSpider.py文件,进入该项目的目录,进入命令行,执行如下命令:
scrapy crawl musicSpider
方法二:在该Scrapy项目文件夹下创建一个名为:main.py的文件,文件名字最好不要改。编辑该文件内容:
from scrapy import cmdline #帮助我们执行命令行命令
cmdline.execute("scrapy crawl musicSpider".split()) #不写就是用空格做分隔符
然后进入该项目的目录,进入命令行,执行main.py文件,即在命令行窗口输入:main.py ,回车。

