
视频摘要技术详解:原理、类型与应用场景深度剖析
在信息爆炸的时代,视频内容呈指数级增长。面对海量的视频数据,如何快速提取关键信息,节省观看时间,成为了一个重要的课题。视频摘要技术应运而生,它通过提取视频中的关键帧或片段,生成一个简短的概括性版本,让用户能够迅速了解视频的主要内容。视频摘要不仅仅是简单的剪辑,更是一项融合了人工智能、图像处理和自然语言理解的复杂技术。从社交媒体的短视频精选,到安防监控的关键事件回放,再到数字图书馆的视频内容索引,视频摘要的应用场景十分广泛。它极大地提高了信息获取效率,节省了用户的时间和精力,对内容创作者、消费者以及信息管理人员来说,都具有重要价值。
本文将深入探讨视频摘要的定义、原理、类型、架构以及应用场景,帮助读者全面了解这一重要技术。我们将剖析关键帧提取和视频略读两种主要方法的优缺点,介绍不同的视频摘要架构,并探讨其在消费视频应用、数字视频图书馆和安防监控等领域的实际应用案例。通过阅读本文,您将对视频摘要技术有一个清晰而深刻的认识,并能够更好地利用它来提高信息获取效率。
视频摘要技术关键点
视频摘要旨在通过缩短视频长度,提供关键信息,从而提高观看效率。
关键帧提取和视频略读是两种主要的视频摘要方法。
视频摘要的架构通常包括帧/特征提取、帧选择和重构等步骤。
视频摘要技术在消费视频应用、数字视频图书馆和安防监控等领域有着广泛的应用。
自动编码器和生成对抗网络(GAN)等技术常被用于视频摘要的实现。
视频摘要技术基础
视频摘要的定义与核心思想
视频摘要是一种通过提取视频中的关键信息,生成简短概括性版本的技术。核心思想是在尽可能保留视频主要内容的前提下,大幅度缩减视频的长度,以便用户快速了解视频的核心内容。

视频摘要并非简单地删除部分帧或片段,而是通过复杂的算法,分析视频的内容,识别出最具代表性的帧或片段,并将它们组合成一个连贯的摘要。这种技术的目标是最大限度地提高信息传递效率,节省用户的时间,并方便用户进行视频内容的浏览和检索。简而言之,视频摘要旨在通过精简的方式,提供视频的精华。
视频摘要技术涉及多个学科的知识,包括:
图像处理: 用于分析视频帧的视觉特征,例如颜色、纹理和边缘等。
计算机视觉: 用于识别视频中的对象、场景和事件。
自然语言理解: 用于理解视频中的语音和文本信息,例如字幕和语音解说。
机器学习: 用于训练模型,自动提取视频的关键信息。
通过将这些技术融合在一起,视频摘要能够有效地从复杂的视频数据中提取出有价值的信息,并以简洁明了的方式呈现给用户。
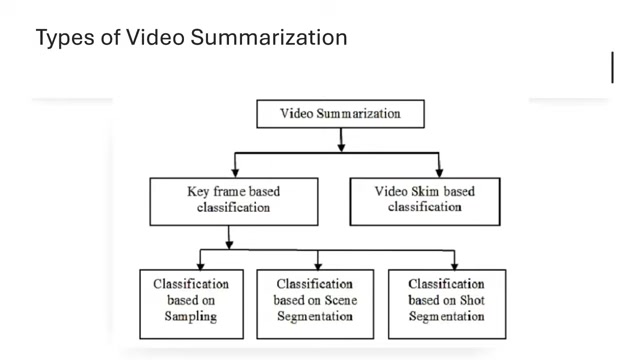
视频摘要的主要类型:关键帧提取与视频略读
视频摘要技术主要分为两大类型:关键帧提取(Key Frame Extraction)和视频略读(Video Skimming)。这两种方法各有优缺点,适用于不同的应用场景。
关键帧提取:
静态帧可能无法完整地表达视频中的动态信息。
关键帧的选择对摘要的质量影响很大,需要精巧的算法。
生成的摘要非常简洁,易于浏览。
计算复杂度较低,适用于大规模视频数据的处理。
原理: 从视频中选取最具代表性的静态帧,这些帧被称为关键帧。关键帧能够概括视频的主要内容,用户通过浏览关键帧,可以快速了解视频的核心信息。

关键帧提取通常基于图像处理和计算机视觉技术,例如颜色直方图、边缘检测和对象识别等。
优点:
缺点:
视频略读:
生成的摘要长度通常比关键帧提取更长。
计算复杂度较高,对硬件资源的要求较高。
能够保留视频中的动态信息,更完整地表达视频的内容。
用户可以通过观看摘要,更直观地了解视频的情节。
原理: 从视频中选取最具代表性的短片段,并将它们拼接在一起,形成一个简短的视频摘要。视频略读能够保留视频中的动态信息,例如人物的动作和场景的变化等。视频略读通常基于视频分析和自然语言理解技术,例如镜头分割、语音识别和文本摘要等。
优点:
缺点:
选择哪种类型的视频摘要,取决于具体的应用场景和需求。例如,对于新闻视频,关键帧提取可能更适合快速了解事件的梗概;而对于电影预告片,视频略读则更适合展示电影的精彩片段。
视频摘要技术的架构与实现
视频摘要的典型架构
视频摘要的典型架构通常包括以下几个步骤:
帧/特征提取:
首先,需要将视频分解为一系列的帧,并提取每一帧的特征。这些特征可以是颜色直方图、纹理特征、边缘特征,也可以是基于深度学习的特征向量。特征提取的目的是将视频帧转换为计算机能够处理的数值表示,以便进行后续的分析和处理。常用的特征提取方法包括:
颜色直方图: 统计每一帧中不同颜色的像素数量,形成一个颜色分布的直方图。
纹理特征: 描述每一帧中纹理的粗细、方向和对比度等信息。
边缘特征: 检测每一帧中的边缘,并提取边缘的长度、方向和强度等信息。
深度学习特征: 使用预训练的深度学习模型(例如CNN),提取每一帧的特征向量。这些特征向量能够捕捉视频帧的语义信息,例如对象、场景和事件等。
帧选择: 在提取了视频帧的特征之后,需要选择出最具代表性的帧,作为关键帧。帧选择的目标是尽可能保留视频的主要内容,同时减少摘要的长度。常用的帧选择方法包括:
基于聚类的方法: 将视频帧的特征向量进行聚类,每一簇的中心帧作为关键帧。
基于信息熵的方法: 选择信息熵最大的帧作为关键帧。信息熵能够反映视频帧的信息量,信息熵越大,说明该帧包含的信息越多。
基于重要性的方法: 根据视频帧的重要性,选择出最重要的帧作为关键帧。视频帧的重要性可以通过多种方式来衡量,例如帧的显著性、帧的运动程度和帧的内容相关性等。
视频重构: 对于视频略读,需要将选择出来的片段拼接在一起,形成一个连贯的视频摘要。视频重构的目标是使摘要流畅自然,同时保留视频的主要内容。视频重构通常需要考虑以下几个因素:
片段的顺序: 片段的顺序应该与原始视频的顺序一致,以便用户更好地理解视频的情节。
片段的过渡: 片段之间的过渡应该平滑自然,避免出现突兀的跳跃。
片段的长度: 片段的长度应该根据视频的内容进行调整,重要的片段可以长一些,不重要的片段可以短一些。
通过以上步骤,就可以生成一个简洁而概括性的视频摘要。
视频摘要技术中的关键算法:自动编码器与生成对抗网络
在视频摘要的实现中,自动编码器(Autoencoder)和生成对抗网络(Generative Adversarial Network, GAN)是两种常用的算法。

它们能够有效地提取视频的关键特征,并生成高质量的摘要。
自动编码器:
原理: 自动编码器是一种神经网络,它能够将输入数据压缩到一个低维度的潜在空间(Latent Space),然后再从潜在空间中重构出原始数据。自动编码器的训练目标是最小化重构误差,使得重构后的数据尽可能接近原始数据。
在视频摘要中的应用: 自动编码器可以用于提取视频的关键特征。首先,将视频帧输入到编码器中,得到一个低维度的特征向量。然后,将这个特征向量输入到解码器中,重构出原始视频帧。通过训练自动编码器,可以学习到视频帧的关键特征,这些特征能够有效地概括视频的内容。在生成视频摘要时,可以选择潜在空间中具有代表性的特征向量,然后通过解码器生成对应的视频帧或片段,作为摘要的内容。
优势: 自动编码器能够自动学习视频的关键特征,无需人工设计特征提取器。
生成对抗网络:
原理: 生成对抗网络由两个神经网络组成:生成器(Generator)和判别器(Discriminator)。生成器的目标是生成尽可能逼真的数据,而判别器的目标是区分生成器生成的数据和真实数据。生成器和判别器相互对抗,不断提高各自的能力。当判别器无法区分生成器生成的数据和真实数据时,说明生成器已经能够生成非常逼真的数据。
在视频摘要中的应用: 生成对抗网络可以用于生成高质量的视频摘要。首先,将原始视频作为真实数据,训练生成器生成视频摘要。然后,训练判别器区分生成的摘要和原始视频。通过不断对抗,生成器能够生成越来越逼真的视频摘要。在生成视频摘要时,可以使用生成器生成多个候选摘要,然后选择其中质量最高的摘要作为最终结果。
优势: 生成对抗网络能够生成高质量的视频摘要,具有较强的鲁棒性和泛化能力。
自动编码器和生成对抗网络各有优缺点,可以根据具体的应用场景选择合适的算法。在实际应用中,可以将这两种算法结合在一起,以获得更好的效果。例如,可以使用自动编码器提取视频的关键特征,然后使用生成对抗网络生成高质量的视频摘要。
视频摘要技术应用场景
消费视频应用
在消费视频应用领域,视频摘要可以用于:
短视频精选: 从长视频中提取精彩片段,生成短视频,方便用户快速浏览和分享。
电影预告片: 从电影中提取精彩片段,生成预告片,吸引用户观看。
视频集锦: 将多个视频中的精彩片段组合在一起,生成一个视频集锦。
自动生成字幕: 自动识别视频中的语音,生成字幕,方便用户观看。
这些应用可以提高用户观看视频的效率,节省用户的时间,并提高用户对视频的兴趣。
数字视频图书馆
在数字视频图书馆领域,视频摘要可以用于:
视频内容索引: 为视频创建索引,方便用户快速检索到所需的内容。
视频内容浏览: 用户可以通过浏览视频摘要,快速了解视频的内容,决定是否观看完整视频。
视频内容推荐: 根据用户的兴趣,推荐相关的视频摘要,提高用户的满意度。
这些应用可以提高视频图书馆的管理效率,方便用户查找和利用视频资源。
安防监控
在安防监控领域,视频摘要可以用于:
关键事件回放: 从监控视频中提取关键事件,例如入侵、盗窃和火灾等,方便安全人员快速了解事件的经过。
异常行为检测: 检测监控视频中的异常行为,例如人群聚集、奔跑和打斗等,及时发出警报。
智能交通管理: 监控交通视频中的车辆和行人,分析交通流量和拥堵情况,提高交通管理效率。
这些应用可以提高安防监控的效率,及时发现和处理安全问题。

