
一、什么是机器学习
二、机器学习的主要流程
以芝麻信用为例
步骤1:明确问题
找出个人信用的影响因素,从逻辑上讲一个人的体重跟他的信用应该没有关系,比如我们身边很讲信用的人,有胖子也有瘦子。而财富总额貌似跟信用有关,因为马云不讲信用的损失是非常巨大的,所以大家从来没有听说马云会不还信用卡!而一个乞丐不讲信用的损失是很小的,这条街混不下去了换一条街继续。所以根据判断,找出了下面5个影响因素:
付款记录;账户总金额;信用记录跨度(自开户以来的信用记录、特定类型账户开户以来的信用记录…);新账户(近期开户数目、特定类型账户的开户比例…);信用类别(各种账户的数目);由此可构建了一个简单的模型,理解为一个特定的公式,这个公式可以将5个因素跟个人信用分形成关联。
目标就是:得到 f 这个公式具体是什么,这样我们只要有了一个人的这5种数据,就可以得到一个人的信用分数了。
步骤2:收集数据
收集大量的已知数据,这些数据必须包含一个人的5种数据和他/她的信用状态(把信用状态转化为分数)
步骤3:准备数据
除了清洗数据之外,还将数据分成几个部分,一部分用来训练,一部分用来测试和验证。

步骤4:训练模型
将5种数据套入公式,计算出信用分,然后用计算出来的信用分跟这个人实际的信用分(预先准备好的)进行比较。最后,评估公式的准确度,如果问题很大再进行调整优化
步骤5:模型应用
当我们想知道一个新用户的信用状况时,只需要收集到他的这5种数据,套进公式 f 计算一遍就知道结果了!
三、机器学习的主要分类
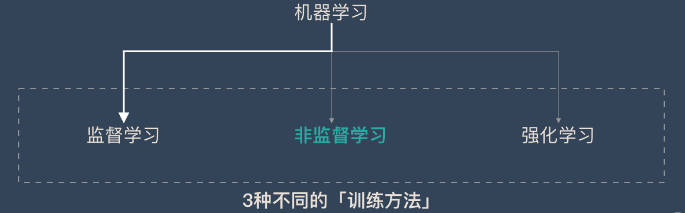
1、监督学习
在监督学习中,算法从有标记数据中学习。在理解数据之后,该算法通过将模式与未标记的新数据关联来确定应该给新数据赋哪种标签。
监督学习的主要流程如下:

监督学习可以分为两类:分类和回归。

分类问题预测数据所属的类别;分类的例子包括垃圾邮件检测、客户流失预测、情感分析、犬种检测等。
回归问题根据先前观察到的数据预测数值;回归的例子包括房价预测、股价预测、身高-体重预测等。
2、无监督学习
现实生活中常常会有这样的问题:缺乏足够的先验知识,因此难以人工标注类别或进行人工类别标注的成本太高。很自然地,我们希望计算机能代我们完成这些工作,或至少提供一些帮助。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。

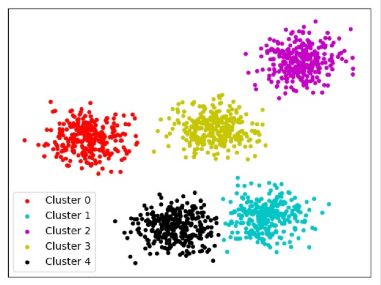
无监督学习可以分为两种主要的类别:聚类和降维。
无监督学习的特点:
(1)无监督学习没有明确的目的;(2)无监督学习不需要给数据打标签;(3)无监督学习无法量化效果;
无监督学习的应用:
(1)发现异常
有很多违法行为都需要"洗钱",这些洗钱行为跟普通用户的行为是不一样的,到底哪里不一样?如果通过人为去分析是一件成本很高很复杂的事情,我们可以通过这些行为的特征对用户进行分类,就更容易找到那些行为异常的用户,然后再深入分析他们的行为到底哪里不一样,是否属于违法洗钱的范畴。通过无监督学习,我们可以快速把行为进行分类,虽然我们不知道这些分类意味着什么,但是通过这种分类,可以快速排出正常的用户,更有针对性的对异常行为进行深入分析。
通过无监督学习,我们可以快速把行为进行分类,虽然我们不知道这些分类意味着什么,但是通过这种分类,可以快速排出正常的用户,更有针对性的对异常行为进行深入分析。
(2)用户细分
(3)推荐系统
大家在淘宝、天猫、京东上逛的时候,总会根据你的浏览行为推荐一些相关的商品,有些商品就是无监督学习通过聚类来推荐出来的。系统会发现一些购买行为相似的用户,推荐这类用户最"喜欢"的商品。
3、强化学习
强化学习并不是某一种特定的算法,而是一类算法的统称。强化学习算法的思路非常简单,以游戏为例,如果在游戏中采取某种策略可以取得较高的得分,那么就进一步「强化」这种策略,以期继续取得较好的结果。
如: Flappy bird 游戏
 、
、
强化学习目前还不够成熟,应用场景也比较局限。最大的应用场景就是游戏了。


