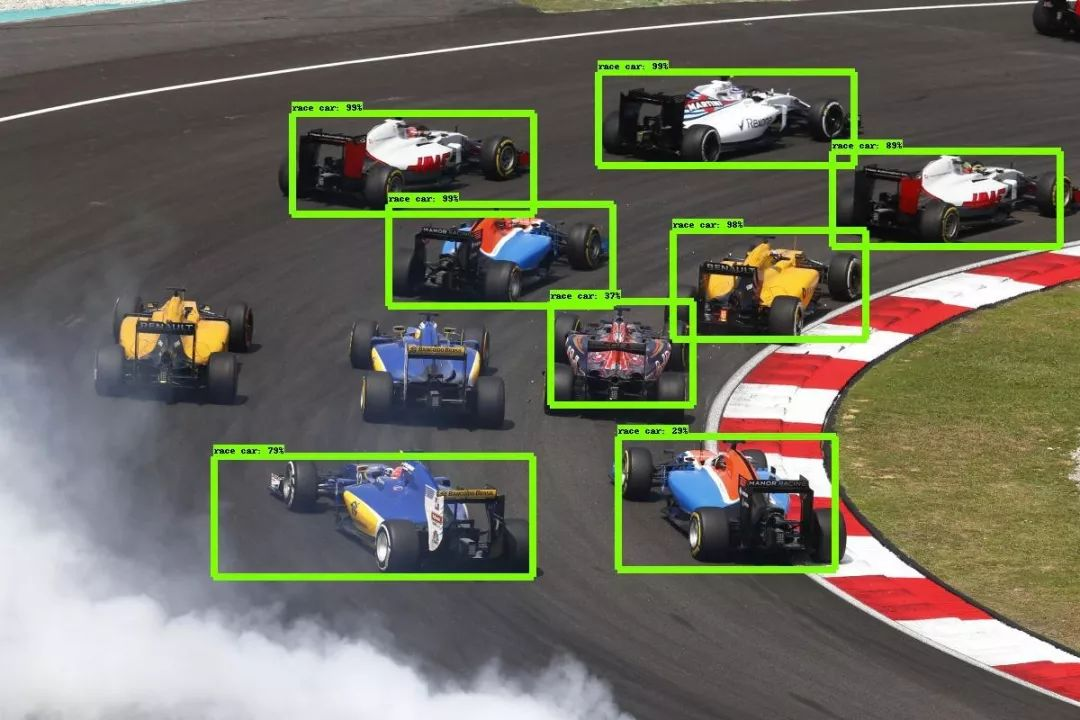
智能网联汽车领域图像处理方法
智能网联汽车中使用的图像处理方法算法主要来源于计算机视觉中的图像处理技术。传统的计算机视觉识别过程大致可分为图像输入、预处理、特征提取、特征分类、匹配和完全识别,包括各关键领域的技术研究,如∶输入图像噪声的平滑、对比度增强和边缘检测信号的预处理、分类识别结果的再处理等算法。在智能网联汽车应用领域中,图像识别主要用于车牌、道路边界、车道线、交通信号、交通标志、车辆/行人等交通参与者、自由行驶空间等对象的感知。 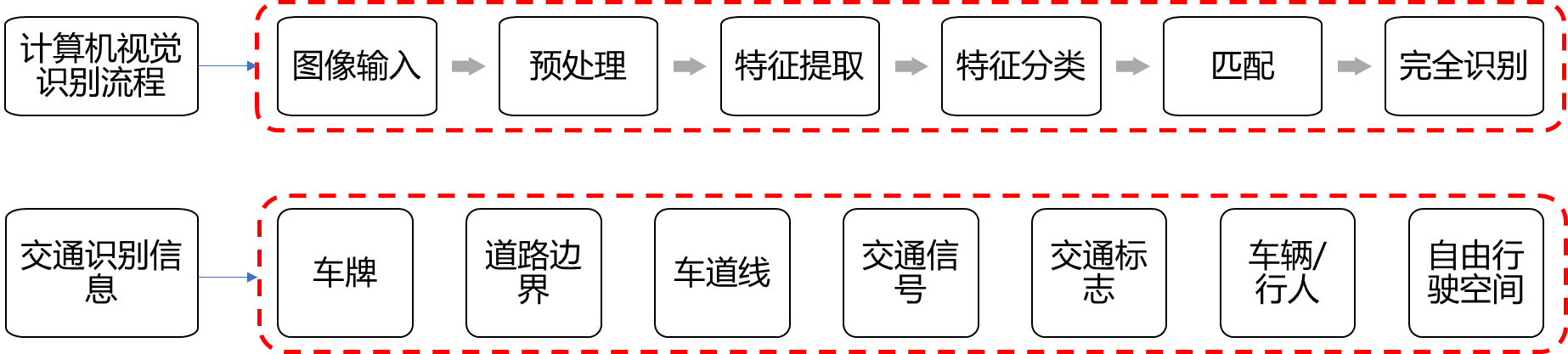
视觉传感器将通过数字化的图像对环境信息编码,编码的目的是使信息可以被计算机处理。典型的图像编码格式有灰度、RGB、CMYK等,根据颜色编码、图像属性、分辨率、压缩方式等特征,一些标准的图像格式如 BMP、JPG(JPEG)、PNG、TIF、GIF、 PCX、TGA、EXIF、FXP等被定义用于标准化和结构化图像的存储,以及在网络、各类操作系统和算法中的传播与使用图像。
以BMP位图为例简述图像的数字化编码过程,如图2-7所示。位图又称点阵图像、位映射图像,它是由一系列像素组成的可识别的图像。位图应用比较广泛,是一种与硬件设备无关的图像文件格式。位图的分辨率指图像矩阵中纵向和侧向像素点的数量乘积,在读取过程中,扫描方式是按从左到右、从下到上的顺序遍历每个像素点,像素点存储该点的颜色编码,位图中颜色编码通常采用RGB或CMYK方式,其中RGB多用于屏幕显示,CMYK多用于印刷。典型的BMP图像文件由头数据和信息数据构成,其中头数据包含图像文件的类型和显示内容等信息,信息数据包含有BMP图像的宽、高、压缩方法,以及定义颜色等信息。
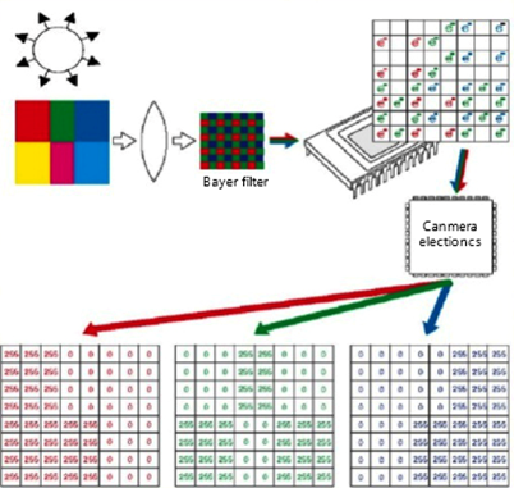
图2-7使用 RGB 编码格式实现图像采集和编码的过程
计算机视觉技术试图建立能够从图像中获取信息的人工智能系统。视觉传感器获取的编码后的数字图像,为视觉算法提供结构化的数据,智能网联汽车中涉及的图像处理算法,就是在结构化的图像信息提取其中包含的环境特征。机器视觉算法的基本步骤包含图像数据的解码、图像特征的提取、识别图像中的目标。图像处理算法包括传统的机器视觉,以及基于人工神经网络的深度学习等技术。
图像数据的解码是利用前文叙述的图像标准,将图像中的信息提取出来,从而进行后续的特征提取等。图像特征的提取是机器视觉中重要的环节,图像是一种矩阵式的点存储方式,通常由统计学等方法对图像矩阵进行转换,获取可用于计算机处理的特征信息。特征提取的过程在信息处理中是一种对数据进行降维的处理方式,目的是找出待识别的各类目标在图像中的典型特征,并通过计算机算法及数据结构描述图像中的特征点,进而就可以通过特征描述判断特征是否匹配,判断当前图像中是否存在待识别目标,以及待识别目标在图像中的位置。
在传统的图像处理算法中,需要人工设计图像中的典型特征,下面举例介绍几种典型的人工图像特征∶
(1)SIFT特征尺度不变特征变换(Scale-InvariantFeature Transform,SIFT)在不同的尺度空间搜索特征点及其方向,获取图像中的目标特征。SIFT所查找到的特征点是不因光照、仿射变换和噪声等因素而变化的突出点,如角点、边缘点、暗区的亮点及亮区的暗点等。
(2)HOG特征方向梯度直方图(Histogram ofOrientedGradient,HOG)特征通过计算和统计图像局部区域的梯度方向直方图来构成特征。HOG 特征被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功。
(3)Har-like特征 Haar-like特征由边缘特征、线性特征、中心特征和对角线特征构成,这三类特征组合成特征模板。特征模板内有白色和黑色两种矩形,并定义该模板的特征值为白色矩形像素和减去黑色矩形像素和。Haar-like特征值反映了图像的灰度变化情况。
人工特征有直观、可分析等优势,在图像识别领域得到了广泛的应用。在实际应用中,还需要考虑相关算法的计算效率和特征描述的普适性等,所以一些评价特征的性能指标被提出来,如∶特征对旋转、尺度缩放、亮度变化的不变性,特征对视角变化、仿射变换、噪声的稳定性。另外,在实际应用中,根据特征点提取方法和特征点描述方法的不同,又进行了满足各类不同功能、性能要求的特征提取方法的细分,如 SIFT、SURF、FAST、HOG、ORB、LBP 等。
人工特征的缺点在于需要对图像中的结构化信息有深入的理解,并能构建可直观区分又能通过数字处理方法提取的特征。但是,对于计算机算法来说,可以更好地被处理和计算的信息,以上特征包含的特点并非是必需的。
随着人工神经网络的发展和图像识别等相关数据集容量的不断增加,以及 GPU 等并行数据处理芯片的广泛应用,使得多层神经网络训练并提取特征成为可能。神经网络逐层提取图像矩阵中的数学特征,层间递进地组合为全局特征,最终实现面向计算的特征提取。多层神经网络的机制与 SIFT和HOG 的图像梯度直方图等人工特征在直观描述上有很大不同。但是,通过一些研究过程的可视化显示,多层神经网络前端网络层本质上是计算边缘梯度和其他简单的操作,类似人工特征的设计,在后端网络层将局部模式组合成更全局的模式。最终结果是通过数据集训练后的神经网络,学习得到目标包含的典型特征,构成强大的特征提取器。
例如,比较典型的卷积神经网络(CNN),是一种根据脑科学对人类感知机理研究中探索出的计算机特征学习算法。在图2-8中显示了卷积神经网络提取图像特征实现视觉识别的过程。首先,通过对网络结构超参数的设计,确定网络的结构;然后,将样本图像提供给网络进行自学习,确定网络中各项参数;最后,就可以使用确定好各项参数的网络对实时获取的图像进行处理,从而获得已经训练后的环境/目标特征。这种特征是通过学习和训练人工神经网络获得的,与人工设计的特征有显著的区别。
目前,现有的基于人工神经网络的目标检测与识别算法大致有三类∶基于区域建议的目则和识别算法;基于回归的目标检测与识别算法;基于搜索的目标检测与识别算法。
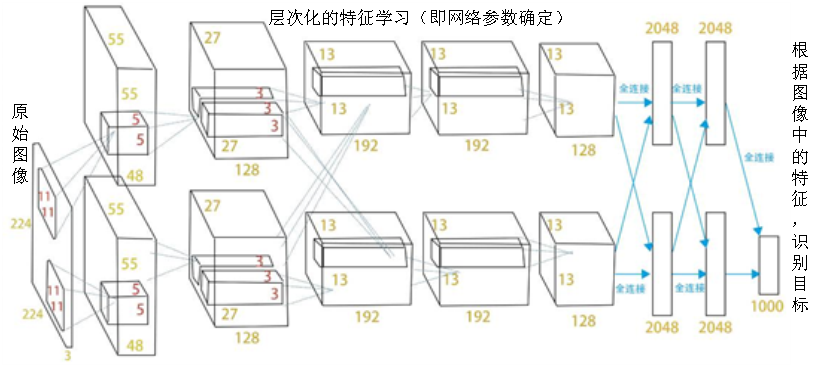
图2-8 卷积神经网络提取图像示意图
人工神经网络使计算机能够模拟人类思维,从而实现自行学习,这种识别方法可以消除图像处理过程中人工特征的设计、提取、预处理等步骤,将感知过程简化为输入图像-输出结果的两个步骤,使得视觉系统能够快速理解环境,并具有自适应、自学习的特点。
图像识别算法在智能网联汽车领域的典型应用如下。
车道检测
车道检测的目标主要是检测车道的形状和车辆在车道上的位置,车道的形状包括宽度和曲率等几何参数,车辆位置包括车辆和道路的横向偏移和偏航角。
在现代道路设计中,道路设计模式相对固定。因此,对于公路等道路类型,车道的几何模型可以用固定的形式表示。车道由圆弧、直线、与曲线构成,缓和曲线有不同曲率(例如螺旋曲线)的圆弧连接过渡段或直线连接过渡段,车道与路面车辆的几何模型元素包括车道曲率、弧长、偏航角等。基于视觉的车道检测的方法有霍夫变换、透视变换、边缘点拟合等。得到车道线原始特征的过程除了视觉图像外,还可以通过激光雷达扫描。
(1)基于霍夫变换的车道线检测霍夫变换用图像空间的边缘数据点计算参数空间中的参考点的可能轨迹,并在累加器中统计轨迹上的参考点,最后选出参考点最多的轨迹。该轨迹表明在图像空间上有一共线点较多的线,即图像待识别中的车道线。霍夫变换检测方法准确简便,缺点是无法识别曲率半径大于100m的车道线,还需要融合仿射变换、边缘点拟合等其他检测方法进行深入学习和算法设计。
(2)基于仿射变换的车道线检测仿射变换方法是通过仿射变换将前方的路面图像转换为俯视图,并提取俯视图中的车道线。该方法的优点是能找到多车道线,实时性好,但应用于复杂道路的稳定性差,仿射变换时图像丢失较大,变换后的车道线在仿射图中有时检测不到,受周围物体遮挡的影响严重,不适用于路况复杂、摄像头视角小的前视野。
(3)基于边缘点拟合的车道线检测边缘点拟合的原理是∶车道线为白色,路面为灰色,车道线和路面之间有稳定的灰色差。通过合理的图像灰度阈值设定,可以提取车道线的边缘。该方法的优点是计算量小,能拟合出曲率较大的车道线;缺点是环境适应性差,易受光照干扰,稳定性差。
车道线在检测时很容易丢失,为了保证检测精度,使用跟踪算法可以提高检测速度和精度。车辆的行驶过程是处于连续位移过程,相应的车道变化也是连续变化的,图像中两帧前后车道线斜率相差不大,位置距离也不会太远,因此可以通过比较前后两帧来控制车道线的斜率,在先前检测到的车道线区域附近进行限定。
跟踪的作用是预测道路特征在下一帧图像中的位置,在较小的范围内检测道路特征,并提高效率。如图2-9所示,如果在预测范围内未检测到道路特征,则使用估计或参考上一帧特征的位置。如果连续帧未检测到道路特征,则启动全图像道路特征检测。车道状态需要考虑车道位置、速度、横摆角和车辆行驶角度之间的关系。跟踪算法一方面保证了为后续检测缩小了搜索范围,另一方面也保证了在摄像头遮挡、车道线不清晰时检测的连续性和稳定性。
图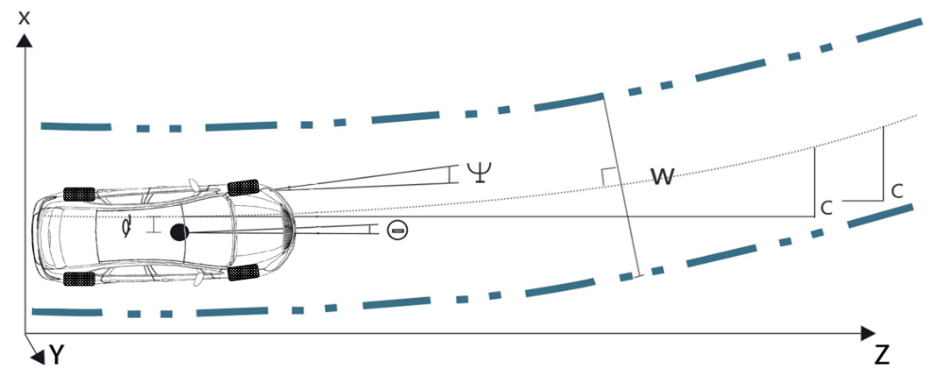
2-9 车道线检测中的跟踪
2.语义分割
计算机视觉的一种图像处理方式,是将整个图像分成多个像素组,然后对分割出来的图像进行标记和分类。语义分割是指图像处理算法试图从语义上理解图像中每个像素的角色,该物体是汽车还是其他分类的物体,除了识别人、路、车、树等,还必须确定每个物体的边缘,需要使用语义分割模型来对物体做出像素级的分割,并通过语义形式提供物体的特征和位置等信息。
语义分割是无人车驾驶的核心算法技术,车载摄像头,或者激光雷达探查到图像后输入到神经网络中,后台计算机可以自动将图像分割归类,以避让行人和车辆等障碍。

图2-10 图像语义分割
如图2-10所示的语义分割实现例子中,原始图像经过深度学习网络进行逐层特征提取、像素级分割、特征识别、语义标注等过程,实现对图像中各类目标的识别、分类、语义信息标注,为智能网联汽车更丰富功能的实现,提供更多、更全面的环境信息。
3.立体视觉与场景流
立体视觉是双眼观察景物能分辨物体远近形态的感觉。
立体视觉的目的在于重构场景的三维几何信息。
用作立体视觉研究的图像在时间、视点、方向上有很大的变动范围,直接受所应用领域的影响。立体视觉的研究主要集中在三个应用领域中,即自动测绘中的航空图片的解释,自主车的导引及避障,人类立体视觉的功能模拟。
在立体视觉的应用领域中,一般都需要一个稠密的深度图。
场景流是空间中场景运动形成的三维运动场。

立体视觉一般有以下三类实现方式∶
1)利用双目视觉传感器建立三维描述,直接获取距离信息的方法。这是一种主动模式立体视觉方法,深度图由双目摄像头获取。根据已知深度图,通过数值逼近重建地表信息,并根据模型建立场景中的物体描述,实现基于图像的环境理解功能。
2)利用一幅图像提供的信息来推断三维形状的方法。根据场景中的灰度变化结合光学成像的透视原理和统计假设导出物体的轮廓和表面推断出物体的形状。
3)利用两个或多个图像在不同视点或不同时间提供的信息,重建三维结构的方法。
4.视觉里程计算法
视觉里程计算法的一个非常重要的特点是它只关心局部运动,而且大部分时间是指两个时刻之间的运动。当以一定的时间间隔采样时,可以估计运动物体在每个时间间隔内的运动。由于这种估计值会受噪声的影响,故将前一时刻的估计误差加入后一时刻的运动,会产生误差累计。
5.目标跟踪
目标跟踪是指系统跟踪特定场景中感兴趣的一个或多个特定对象的过程,目标跟踪在无人驾驶领域很重要,一方面可以提高后续检测的准确性,另一方面能够对目标的运动状态进行跟踪。
根据观测模型,目标跟踪算法可分为两类∶生成算法和判别算法。生成算法利用生成模型来描述目标表面特征,并使重构误差最小化来搜索目标;判别算法又称检测跟踪算法,通过区分待识别目标和道路、天空等背景,将待识别目标提取并进行跟踪。