任务2:使用循环神经网络RNN进行行为识别。
| epochs = 30 # 训练次数
batch_size = 16 # 每个批次大小
n_hidden = 16 # 隐层单元个数
n_classes = 6 # 类别个数
timesteps = len(X_train[0])
input_dim = len(X_train[0][0]) |
| from keras.models import Sequential
from keras.layers import LSTM
from keras.layers.core import Dense, Dropout
model = Sequential()
model.add(LSTM(n_hidden, input_shape=(timesteps, input_dim)))
model.add(Dense(n_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy']) |
| model.fit(X_train,
Y_train,
batch_size=batch_size,
validation_data=(X_test, Y_test),
epochs=epochs) |
运行过程数据如下所示:

| scores = model.evaluate(X_test,Y_test)
print(scores[1]) |
结果显示:
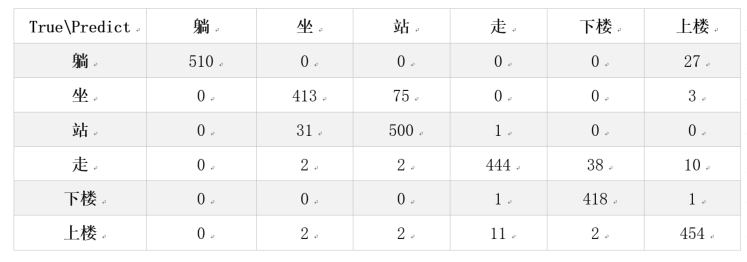
同样,我们也可以使用混淆矩阵来查看具体情况,参考代码如下:可以看到,模型的预测准确率约为89.89%左右,与CNN相差不多。通过设计不同的结构,可以得到更好的结果。尝试修改结构与参数设计,得到更好的结果。
| predicts = model.predict(X_test)
ACTIVITIES = {0: '走',1: '上楼',2: '下楼',3: '坐',4: '站',5: '躺'}
def confusion_matrix(Y_true, Y_pred):
Y_true = pd.Series([ACTIVITIES[y] for y in np.argmax(Y_true, axis=1)])
Y_pred = pd.Series([ACTIVITIES[y] for y in np.argmax(Y_pred, axis=1)])
return pd.crosstab(Y_true, Y_pred, rownames=['True'], colnames=['Pred'])
print(confusion_matrix(Y_test,predicts)) |
运行结果类似于下表所示的结果。