
1 MNIST数据集格式
很多的深度学习框架都有以MNIST为数据集的demo,MNIST是很好的手写数字数据集。在网上很容易找到资源,但是下载下来的文件并不是普通的图片格式。在MNIST数据集中,可以看到有如图所示的四个文件。这些文件都是二进制流格式。
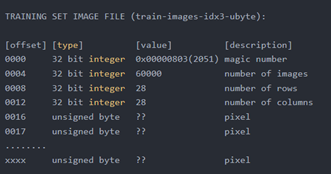
其中,train-images-idx3-ubyte.gz为训练数据集(Training set images),内容格式如图9.2所示。文件大小约为9.9 MB, 解压后 47 MB, 包含 60000 个样本。每个样本大小为28´28像素。
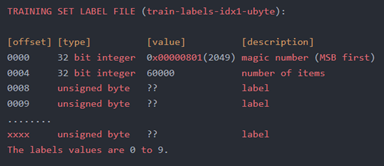
下图显示的是文件train-labels-idx1-ubyte.gz的信息。文件大小约为29 KB, 解压后 60 KB,包含 60000 个标签。每一个标签是32位,4个字节大小。
文件t10k-images-idx3-ubyte.gz 中是测试集图像(Test set images),大小为1.6 MB, 解压后 7.8 MB, 包含 10000 个样本;文件t10k-labels-idx1-ubyte.gz中是测试集数据对应的标签(Test set labels)。大小为5KB, 解压后 10 KB, 包含 10000 个标签。
上述文件不转换为图片格式也可以用。但有时,我们希望得到可视化的图片格式,方便我们了解其中的逻辑与对应操作。
2 MNIST数据集转换化为图像
根据上述对数据集的基本介绍,图像与标签是一一对应的。通过解读图像数据文件和标签数据文件,可以获得对应的图像。主要步骤有:
(1)读取二进制文件,参考代码如下:
| data_buf = open('train-images.idx3-ubyte', 'rb').read() |
(2)解析文件内容
Python中可以使用struct中unpack_from方法来获得相应的数据信息。参考代码如下:
| magic, numImages, numRows, numColumns = struct.unpack_from( '>IIII', data_buf, 0) datas = struct.unpack_from( '>' +'47040000B', data_buf, struct.calcsize('>IIII')) datas = np.array(datas).astype(np.uint8).reshape( numImages, 1, numRows, numColumns) |
(3)存储为图像文件
将第一个28´28像素大小的内容获取过来,并存储为“mnist_train_1.png”文件,参考代码如下:
| img = Image.fromarray(datas[1, 0, 0:28, 0:28]) img.save('mnist_train_1.png ') |
写出循环语句,对所有样本进行如上处理后,得到的部分结果如图所示。每一个训练样本为一个标准化的手写数字,大小为28´28像素。将这些图像作为输入,输出为其对应的标签“8”进行训练,得到模型。

测试数据集的处理同上,不再详述。

