什么是K-Means
K-Means算法是最流行的聚类算法之一。其中,K表示类别数,Means表示均值。顾名思义K-Means是一种通过均值对数据点进行聚类的算法。K-Means算法通过预先设定的K值及每个类别的初始质心对相似的数据点进行划分,并通过划分后的均值迭代优化获得最优的聚类结果,即让各组内的数据点与该组中心点的距离平方和最小化。
K值是聚类结果中类别的数量。简单地说就是我们希望将数据划分的类别数。K值决定了初始质心的数量,K值为几则就表示有几个质心。如图7.3所示,其K值为3,质心数即为3。选择最优K值没有固定的公式或方法,需要人工来指定。一般,建议根据实际的业务需求,或通过层次聚类(Hierarchical Clustering)等方法获得数据的类别数量作为选择K值的参考。需要注意的是:选择较大的K值可降低数据的误差,但会增加过拟合的风险。
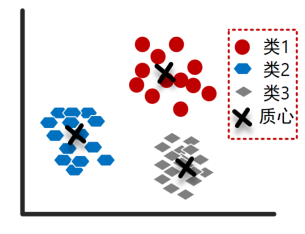
实现时,先随机选取K个对象作为初始的聚类中心。然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。一旦全部对象都被分配了,每个聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
在sklearn中,包括两个K-Means的算法,一个是传统的K-Means算法,对应的类是KMeans。另一个是基于采样的Mini Batch K-Means算法,对应的类是MiniBatchKMeans。使用K-Means算法调参相对简单,一般要特别注意的是K值的选择,即参数n_clusters。
任务2:在以上DBSCAN聚类分析结果的基础上,使用K-Means对相似数据进行聚类,并设置相应的K值(质心个数)为上一任务中得出的结果:4。
步骤一:读取数据,参考代码如下
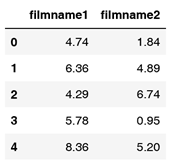
| #!/usr/bin/Python # -*- coding: utf-8 -*- data.head() X = data[['filmname1','filmname2']] |
读取的部分数据结果如图所示。
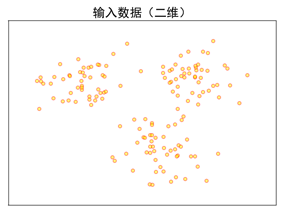
步骤二:展现并观察、分析原始数据的分布特征。
| import matplotlib.pyplotas plt from pylabimport mpl plt.figure() plt.show() |
原始数据的分布特征如图所示。
步骤三:确定K-means的质心个数,并进行模型训练,代码如下:
| from sklearnimport metrics from sklearn.cluster import KMeans # 训练 # 分类结果 step_size = 0.01 predicted_labels = kmeans.predict(np.c_[x_values.ravel(), y_values.ravel()]) |
步骤四:可视化展现分类结果,代码如下:
# 可视化 plt.figure() |
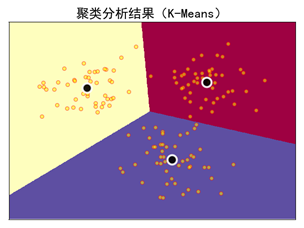
步骤四:分类结果如图所示。