什么是DBSCAN
使用K-Means算法时,必须把类别数量K值作为输入参数。在真实世界中,很多时候我们事先并不知道这个具体值。可以搜索类别数量的参数空间,通过轮廓系数得分找到最优的类别数量,但这是一个非常耗时的过程。DBSCAN(Density-BasedSpatial Clustering of Applications with Noise,带噪声的基于密度的聚类方法)顺势而生。
DBSCAN是一个比较有代表性的基于密度的聚类算法。它将数据点看成是紧密集群的若干组。如果某个点属于一个集群,那么就应该有许多点也属于同一个集群。DBSCAN算法需要首先确定两个参数:
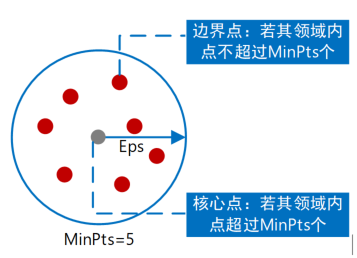
(1)epsilon:在一个样本点周围邻近区域的半径,即扫描半径;
(2)minPts:邻近区域内至少包含样本点的个数,即最小包含点数。
方法中epsilon参数可以控制这个点到其他点的最大距离。如果两个点的距离超过了参数epsilon的值,它们就不可能在一个集群中。这种方法的主要优点是它可以处理异常点。如果有一些点位于数据稀疏区域,DBSCAN就会把这些点作为异常点,而不会强制将它们放入一个集群中。对应地,样本点可以分为三种:
(1)核点(core point):在半径epsilon内含有超过minPts数目的点,则为核样本点;
(2)边缘点(border point):在半径epsilon内点的数目小于minPts,但是落在核心点的临域内,可由一些核点获得(density-reachable或者directly-reachable);
(3)离群点(Outlier):既不是核点也不是边缘点,则属于这一类。
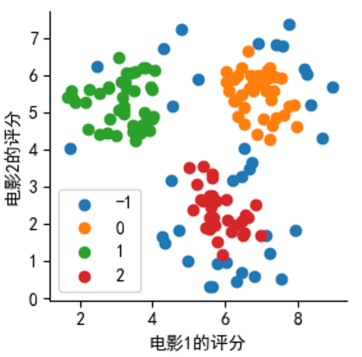
任务1:下面以观影评分数据为例说明方法的使用。数据文件中存储了两列数据,分别表示用户对两部电影的评分。根据评分值的相似性,我们对观影用户进行分类,分成不同的客户群。使用DBSCAN方法确定具体分为几类。
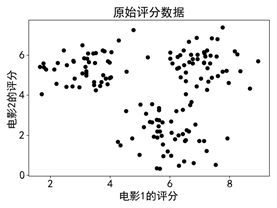
步骤一:从评分数据文件“filmScore.csv”中读入原始数据,并进行可视化。
|
原始数据的可视化结果如图所示。
步骤二:调用DBSCAN进行聚类分析,获得质心个数,参考代码如下:
#引入机器学习相关的类 from sklearn.cluster import DBSCAN |
步骤三:对聚类预测结果进行可视化,参考代码如下:
import matplotlib.pyplotas plt from pylabimport mpl |
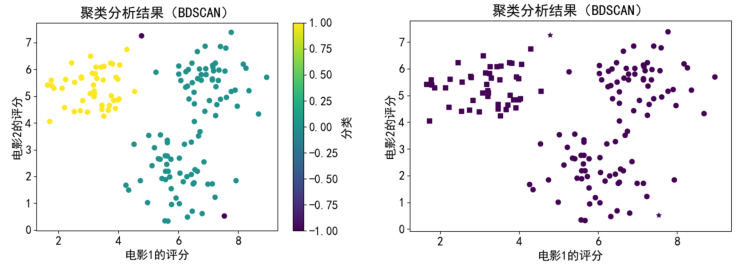
运行代码,结果如下图(a)所示。为区别不同类别,图(b)中用形状区分的方式做了分类结果的显示。
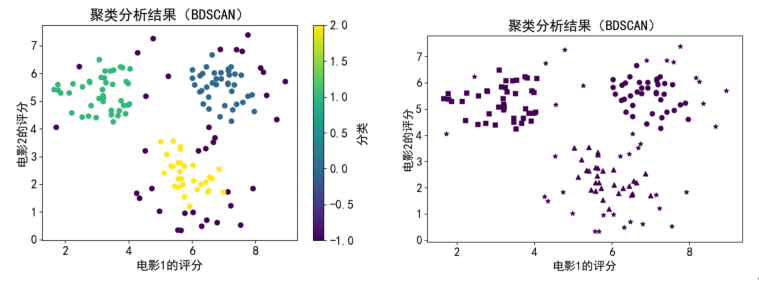
(a)颜色区分 (b)形状区分
步骤四:修改参数。方法对参数敏感,设置eps=1.3,min_samples=20,代码如下。
# 调用DBSCAN()确定质心个数 y_pred = DBSCAN(eps=1.3, min_samples=20).fit_predict(data) |
运行结果如图所示。
步骤五:可视化进阶。seaborn是一款非常方便的画图工具,安装seaborn库后,使用代码实现可视化。代码如下:
import seabornas sb # 调用DBSCAN()确定质心个数 |
上述代码运行结果如图所示,其中“-1”表示异常类。