
无监督学习
现实生活中常常会有这样的问题:分类过程中缺乏足够的先验知识,因此难以人工标注类别;又或者进行人工类别标注的成本太高。很自然地,我们会希望计算机能替代人工完成这些工作,或至少提供一些帮助。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习(Unsupervised Learning)。它是一种对不含标记的数据建立模型的机器学习范式。
到目前为止,项目中处理的分类数据都带有某种形式的标记,也就是说,学习算法可以根据标记好的标签对数据进行分类。但是,在无监督学习的世界中,没有了这样的条件。当我们需要用一些相似性指标对数据集进行分组时,就会用到这些无监督学习的方法了。
如上图所示,无监督学习主要有:聚类(clustering)和降维(dimensionality reduction)。如果给定一组样本特征,没有对应的属性值,而是想发掘这组样本在空间的分布, 比如分析哪些样本靠的更近,哪些样本之间离得很远, 这就是属于聚类问题。聚类就是将观察值聚成一个一个的组,每一个组都含有一个或者几个特征。比如一些推荐系统中需要确定用户类型,但定义用户类型却可能不太容易,此时往往可先对原有的用户数据进行聚类,根据聚类结果将每个簇定义为一个类,然后再基于这些类训练分类模型,用于判别新用户的类型。而降维是为了缓解维数灾难的一个重要方法,就是通过某种数学变换将原始高维属性空间转变成为一个低维“子空间”,如图所示。
无监督学习广泛应用于各种领域,如数据挖掘、医学影像、股票市场分析、计算机视觉、市场细分等,用于在大量无标签数据中发现些什么。它的训练数据是无标签的,训练目标是能对观察值进行分类或者区分等。
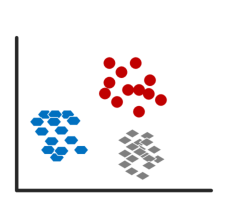
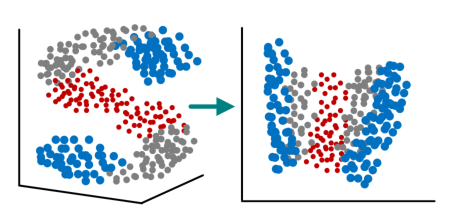 (a)聚类(形状、颜色区分类别) (b)降维(颜色、大小区分类别 )
(a)聚类(形状、颜色区分类别) (b)降维(颜色、大小区分类别 )
图7.2 聚类与降维
聚类分析
聚类就是将物理或抽象对象的集合分成由类似的对象组成的多个类的过程。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类具体是什么。可以想象,恰当地提取特征是无监督最为关键的环节。比如,在猫的聚类过程中提取猫的特征:皮毛、四肢、耳朵、眼睛、胡须、牙齿、舌头等等。通过对特征相同的动物的聚类,可以将猫或者猫科动物聚成一类。但是此时,我们不知道这群毛茸茸的东西是什么,我们只知道,这团东西属于一类,兔子不在这个类(耳朵不符合),飞机也不在这个类(有翅膀)。特征有效性直接决定着算法有效性。如果我们拿体重来聚类,而忽略体态特征,恐怕就很难区分出兔子和猫了。
一个聚类算法通常只需要知道如何计算特征的相似度就可以开始工作了。这些集群通常是根据某种相似度指标进行划分的,例如欧氏距离(Euclidean distance)。聚类算法一般有五种方法,(1)划分方法(partitioningmethods),主要有K-Means算法、K-MEDOIDS算法、CLARANS算法;(2)层次方法(hierarchical methods):BIRCH算法、CURE算法、CHAMELEON算法;(3)基于密度的方法(density-based methods):OPTICS算法、DENCLUE算法;(4)基于网格的方法(grid-based methods):STING算法、CLIQUE算法、WAVE-CLUSTER算法;(5)基于模型的方法(model-based methods):统计的方案和神经网络的方案。最主要的是划分方法和层次方法两种。
在商务上,聚类能帮助市场分析人员从客户基本库中发现不同的客户群,并且用购买模式来刻画不同的客户群的特征。传统的聚类已经比较成功的解决了低维数据的聚类问题。高维数据聚类分析在市场分析、信息安全、金融、娱乐、反恐等方面都有很广泛的应用。聚类的优点在于其对数据输入顺序不敏感。但是,该方法在数据分布稀疏时,分类不准确;当高维数据集中存在大量无关的属性时,使得在所有维中存在簇的可能性几乎为零;缺乏处理“噪声”数据的能力;有些算法还需要给出希望产生的簇的数目。比如,划分聚类算法通过优化评价函数把数据集分割为K个部分,它需要将K作为输入参数来完成聚类。典型的分割聚类算法有K-Means算法。
层次聚类由不同层次的分割聚类组成,层次之间的分割具有嵌套的关系。它不需要输入参数,这是它优于分割聚类算法的一个明显的优点,其缺点是终止条件必须具体指定。典型的分层聚类算法有BIRCH算法、CURE算法等。
任务概要
具体实现过程可参考PPT及后续讲解内容
下载并完成实验报告,找到发布的作业并上传至平台:
word版
ipynb版
本次实验用到的数字资源

