什么是随机森林
传统的分类的机器学习算法有很多,比如决策树、支持向量机等。这些算法都是单个分类器,他们有性能提升的瓶颈以及过拟合的问题;因此,集成多个分类器来提高预测性能的方法应运而生,这就是集成学习算法(Ensemble Learning)。
集成学习是将多个模型进行组合来解决单一的预测问题。它的原理是生成多个分类器模型,各自独立地学习并做出预测。这些预测最后结合起来得到预测结果,因此和单独分类器的结果相比,结果一样或更好。
Bagging(并行)和Boosting(串行)是两种常见的集成学习方法,这两者的区别在于集成的方式是并行还是串行。随机森林算法(Random Forests)是并行集成方法里最具有代表性的一个算法。
一般而言,决策树的建树最常见的是自下而上的方式。一个给定的数据集被分裂特征分成左和右子集,然后通过一个评价标准来选择使平均不确定性降低最高的分裂方式,将数据集相应地划分为两个子节点,并通过使该节点成为两个新创建的子节点的父节点来建树。整个建树过程是递归迭代进行的,直到达到停止条件。例如,达到最大树深度或最小叶尺寸。
随机森林是基于决策树的一种集成学习算法。决策树是广泛应用的一种树状分类器,在树的每个节点通过选择最优的分裂特征不停地进行分类,直到达到建树的停止条件,比如叶节点里的数据都是同一个类别的。当输入待分类样本时,决策树确定一条由根节点到叶节点的唯一路径,该路径叶节点的类别就是待分类样本的所属类别。决策树是一种简单且快速的非参数分类方法,一般情况下,它有很好的准确率,然而当数据复杂时,决策树有性能提升的瓶颈。随机森林是2001年由LeoBreiman将并行集成学习理论与随机子空间方法相结合,提出的一种机器学习算法。随机森林是以决策树为基分类器的一个集成学习模型,它包含多个由并行集成学习技术训练得到的决策树,当输入待分类的样本时,最终的分类结果由单个决策树的输出结果投票决定。随机森林解决了决策树性能瓶颈的问题,对噪声和异常值有较好的容忍性,对高维数据分类问题具有良好的可扩展性和并行性。此外,随机森林是由数据驱动的一种非参数分类方法,只需通过对给定样本的学习训练分类规则,并不需要先验知识。
随机森林最好的用例之一是特征选择。尝试很多决策树变种的一个副产品就是你可以检测每棵树中哪个变量最合适/最糟糕。
随机森林也很善于分类。它可以被用于为多个可能目标类别做预测,它也可以被校正输出概率。你需要注意的一件事情是过拟合。随机森林容易产生过拟合,特别是在数据集相对小的时候。当你的模型对于测试集合做出“太好”的预测的时候就应该怀疑一下了。产生过拟合的一个原因是在模型中只使用相关特征。然而只使用相关特征并不总是事先准备好的,使用特征选择(就像前面提到的)可以使其更简单。
随机森林也可以用于回归。因此,在scikit-learn中,随机森林算法既有应用于分类的随机森林分类(RandomForestClassifier),又有可以用于回归问题的随机森林回归(RandomForestRegressor)。
任务2:下面以鸢尾花分类为例,说明RandomForestClassifier的使用。
随机森林对应的部分代码如下:
| from sklearn.ensemble import RandomForestClassifier |
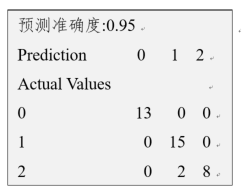
模型评估结果报告如图所示,你预测准确度为0.95。