什么是KNN
邻近或K最近邻(K-NearestNeighbor,KNN)分类算法是基于实例的分类(instance-based learning),属于惰性学习(lazy learning),是数据挖掘分类技术中最简单地方法之一。KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的K个最相似(即在特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN没有明显的训练学习过程,不同K值的选择都会对KNN算法的结果造成重大影响。KNN算法的结果很大程度取决于K的选择,其算法过程描述为:
(1)计算测试数据与各个训练数据之间的距离;
(2)按照距离的递增关系进行排序;
(3)选取距离最小的K个点;
(4)确定前K个点所在类别的出现频率;
(5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
KNN可以应用很多情境中,比如:如果要预测某一套房子的单价,就参考最相似的K个房子的价格,比如相似特征可以是距离最近、户型最相似等。
任务1:下面以鸢尾花的公开数据集为例,说明sklearn中KNN的使用。
要求以iris数据集为分析对象,根据已知的花萼长度、花萼宽度、花瓣长度和花瓣宽度,使用KNN来预测对应的鸢尾花品种。以下过程以数据读取、数据分析及可视化来说明sklearn中KNN的使用过程。
步骤一:读取数据,代码如下:
| #coding:utf-8 import pandas as pd |
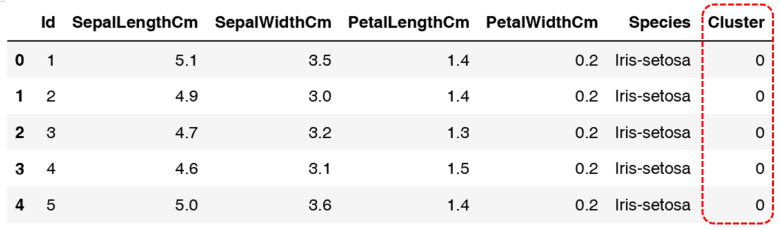
步骤二:读取准备(标签映射),代码如下:
| from sklearnimport preprocessing # 对类别进行数值化处理 |
数据预处理结果如图所示。
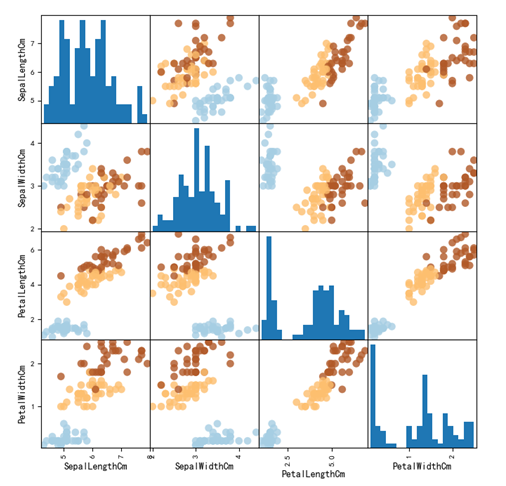
步骤三:原数据可视化展现,代码如下:
| import numpyas np import matplotlib.pyplotas plt |
可视化结果,如图所示。
步骤四:数据集切分,代码如下:
| from sklearn.model_selection import train_test_split |
步骤五:使用KNN建立模型并训练,代码如下:
| from sklearn.neighbors import KNeighborsClassifier # KNN近邻分类预测 |
步骤六:对模型进行评估,代码如下:
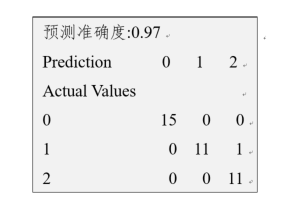
| y_pred=knn.predict(x_test) |
上述代码中对模型进行了简单评估,其预测准确度为0.97,具体显示结果如图所示。