
任务简介
上一节
下一节
机器学习中常用的分类算法主要有:项目五中涉及到的逻辑回归(Logistic Regression)、朴素贝叶斯(Naive Bayes)、决策树、支持向量机(Support Vector Machine,SVM)外,还有K近邻(K-NearestNeighbor,KNN)、集成学习(如随机森林)、神经网络、深度学习等方法。前一章对前四种方法有了一个初步的认识,本章主要了解KNN、随机森林、神经网络方法的使用。
下面就以经典的鸢尾花分类为例,对以上三个方法进行讲解和说明。
如下表所示,鸢尾花数据集iris.csv以鸢尾花的特征作为数据源,包含150个数据集根据鸢尾花4个不同的特征将数据集分为3个品种,分别是山鸢尾(setosa)、变色鸢尾(versicolor)和维吉尼亚鸢尾(virginica)。每个品种均有50个数据,每一朵鸢尾花的4个独立的属性,分别为花萼长度(spepal length)、花萼宽度(spepal width)、花瓣长度(petal length)和花瓣宽度(petal width)。
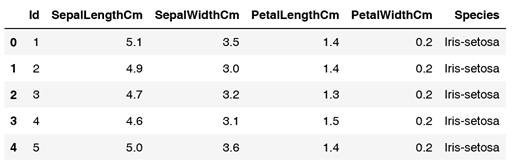
要求以iris数据集为分析对象,根据已知的花萼长度、花萼宽度、花瓣长度和花瓣宽度,使用不同的机器学习方法来预测对应的鸢尾花品种。
任务概要
具体实现过程可参考PPT及后续讲解内容,即3.2
下载并完成实验报告,找到发布的作业并上传至平台:
word版
ipynb版
本次实验用到的数字资源

