标准体重是反映和衡量一个人健康状况的重要标志之一。过胖和过瘦都不利于健康,也不会给人以健美感。不同体型的大量统计材料表明,反映正常体重较理想和简单地指标,可用身高体重的关系来表示,也就是说,我们可以通过身高和体重数据,对人的肥胖程度进行分类。
任务2:使用支持向量机对人的肥胖程度进行分类(四类)。
如图所示的样本数据中,给定了肥胖程度(过轻、正常、过重、肥胖)的样本数据。根据结果训练模型,用来判定肥胖程度。
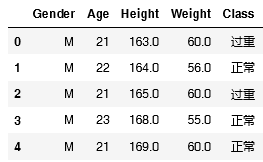
步骤一:数据准备,从文件中读取数据,并准备好训练的数据,代码如下:
| df= pd.read_csv('hw3.csv', delimiter=',') df['Weight'] = df['Weight'].astype(float64)
X = df[['Height', 'Weight']] |
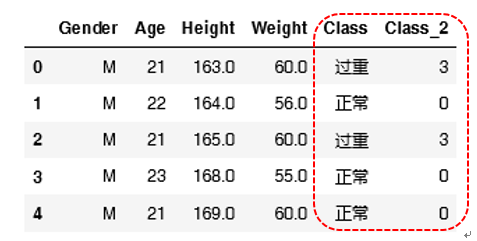
标签映射结果如图所示。
步骤二:使用SVM对模型进行训练,调用的代码如下:
| # 建立SVM分类器模型 params = {'kernel':'linear'} x_train, x_test,y_train, y_test=train_test_split(X,Y,train_size=0.7,test_size=0.3) |
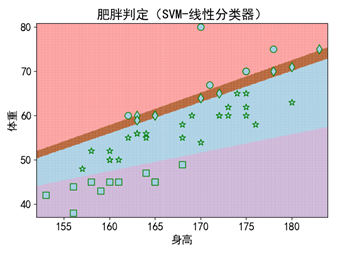
步骤三:使用模型进行预测,及模型好坏的分析报告。
| x_min, x_max = df[['Height']].values.min() - 1.0, df[['Height']].values.max() + 1.0 y_min, y_max = df[['Weight']].values.min() - 1.0, df[['Weight']].values.max() + 1.0 # 预测值 |
运行代码后,可视化结果如图所示
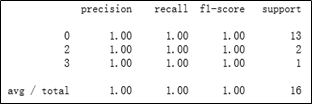
步骤四:对模型进行评估,报告产生代码参考如下:
| #10分析报告 from sklearn.metrics import classification_report |
得到的模型评估报告结果如图所示。