
背景知识
1.1 机器学习
机器学习的方法主要有四种:监督、无监督、半监督和强化学习,如图所示。传统的机器学习中监督学习又分为分类和回归。分类和回归问题几乎涵盖了现实生活中所有的数据分析的情况,两者的区别主要在于我们关心的预测值是离散的还是连续的。分类是针对离散的数据,而回归是针对连续的数据。
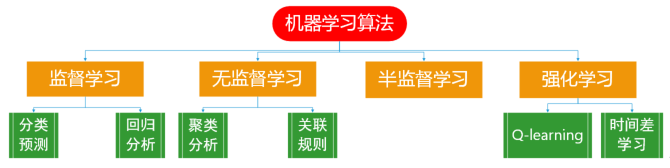
比如,预测明天下雨不下雨的问题就是一个分类问题,因为预测结果只有两个值:下雨和不下雨(离散的);预测中国未来的国民生产总值(GDP)就是一个回归问题,因为预测结果是一个连续的数值。在某些情况下,通过把连续值进行离散化,那么回归问题就可以转化为分类问题。
1.2 监督学习
监督学习(Supervised Learning)是使用已知正确答案的示例来训练网络的。举个例子,假设我们需要训练一个模型,让其从照片库中(其中包含本人的照片)识别出你自己的照片,那么下图显示了在这个假设场景中所要采取的机器学习方法的应用步骤。
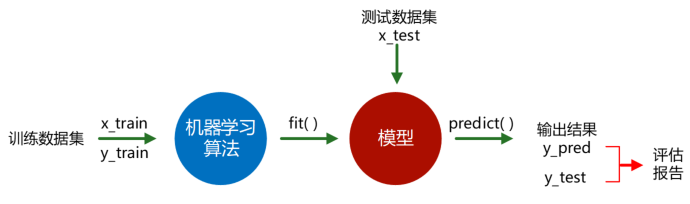
步骤1:数据集的创建和分类
首先,我们要浏览所有的照片(数据集),确定其中含有你的照片,并对其进行标注。然后我们将把所有照片分成两块。使用第一块(训练数据集)来训练模型,而通过第二块(验证数据、测试数据集)来查看训练好的模型在选择照片操作上的准确程度。
在数据集准备就绪后,我们就会将照片提供给模型。在数学上,我们的目标就是在模型中找到一个函数,这个函数的输入是一张照片,而当你的头像不在照片中时,其输出为0,否则输出为1。
此步骤通常称为分类任务(categorization task)。在这种情况下,我们进行的通常是一个结果为是或否的训练。当然,监督学习也可以用于输出一组值,而不仅仅是0或1。例如,我们可以用它来输出一个人偿还信用卡贷款的概率,那么在这种情况下,输出值就是0到100之间的任意值。这些任务我们称之为回归。
步骤2:训练
既然我们已经知道有你的照片是哪些图片,那么我们就可以告诉模型它的预测是对还是错。然后我们会将这些信息反馈(feed back)给模型。
该算法使用的这种反馈,就是一个量化“真实答案与模型预测有多少偏差”的函数的结果。这个函数被称为成本函数(cost function),也称为目标函数(objective function)、效用函数(utility function)或适应度函数(fitness function)。然后,该函数的结果用于修改一个称为反向传播(backpropagation)过程中节点之间的连接强度和偏差,因为信息从结果节点“向后”传播。每个图片都重复此操作。过程中,算法都在尽量地最小化成本函数。
步骤3:验证
处理好了所有照片后,接下来可以去测试该模型。我们应充分利用好第二块照片,并使用它们来验证训练出的模型是否可以准确地挑选出含有你在内的照片。
步骤4:使用
最后,有了一个准确的模型后,就可以将该模型部署到应用程序中。可以将模型定义为API调用,可以从软件中调用该方法,使用模型进行推理并给出相应的结果。监督学习方法,针对不同的应用(回归或分类),常用的有以下几种,如图所示。
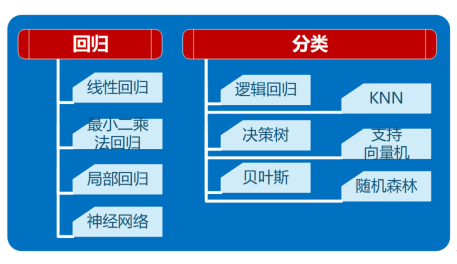
然而,有时要得到一个标记好的数据集可能需要的代价很高。因此,确保预测的价值是超过获得标记数据的成本才是值得的。例如,获得可能患有癌症的人的标签需要X射线,这种代价是非常昂贵的。但是,获得产生少量假阳性和少量假阴性的准确模型的值,这种获取的可能性就非常高的。这时候可以使用无监督学习。
无监督学习适用于有数据集但无标签的情况。无监督的学习技术包括:自编码(Autoencoding)、主成分分析(Principal components analysis)、随机森林(Random forests)、K均值聚类(K-Meansclustering)。在后面章节中再详述。
1.3 分类器
在机器学习中,分类器作用是在标记好类别的训练数据基础上判断一个新的观察样本所属的类别。分类器依据学习的方式可以分为无监督学习和监督学习。
无监督学习顾名思义指的是给予分类器学习的样本但没有相对应类别标签,主要是寻找未标记数据中的隐藏结构。监督学习通过标记的训练数据推断出分类函数,分类函数可以用来将新样本映射到对应的标签。在监督学习方式中,每个训练样本包括训练样本的特征和相对应的标签。监督学习的流程包括确定训练样本的类型、收集训练样本集、确定学习函数的输入特征表示、确定学习函数的结构和对应的学习算法、完成整个训练模块设计、评估分类器的正确率。
本项目通过身高、体重、性别数据的分析,介绍监督学习中的分类方法。
任务简介
男性、女性的平均身高与体重不同,可否从身高、体重数据上找出与性别的关联。如果能够找出关联,那么我们就可以根据身高、体重数据来鉴别性别。
课程用实验报告,请下载并在完成后上交
第1次课程:
doc版
ipynb版
项目可用资源
主要内容
第2次课程:
doc版
ipynb版
项目可用资源
主要内容

