任务目标
为分析房产面积、房间数、地理位置对房产租赁价格的影响,我们从网络上爬取用户发布的实时信息。为方便解析网页,我们可以利用很多便捷的第三方工具来方便地拉取和分析HTML/XML数据。
环境准备
目前,有许多优秀的库包,用于爬取、分析网页数据。包括requests、BeautifulSoup和Scrapy等。本项目中配置并使用了requests、BeautifulSoup4这两个库。
任务步骤
任务2:从网页中,如http://zu.wz.***.com/house爬取温州市区房产租赁的信息,包括信息标题、房间数、面积、区域、所属行政区及其他,并保存为result.csv文件。阅读到的网站信息截图示例如下图所示。
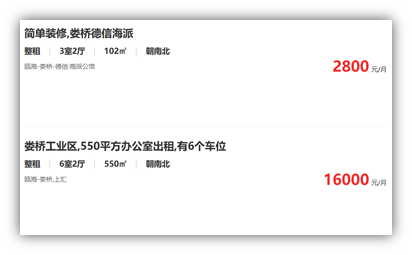
下面就该项任务做一个简单的说明与介绍:
| #!/usr/bin/Python
# -*- coding: gbk -*-
# 导入包
import requests
from bs4 import BeautifulSoup
import csv
import os
# 定义一次爬取的函数
def getData(url):
# 设置模拟的请求头
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'}
# 向网页发起请求
data=requests.get(url,headers=headers)
# 设置编码为gbk
data.encoding='gbk'
# 使用BeautifulSoup解析网页
soup = BeautifulSoup(data.text, "html.parser")
# 查找所有标签p的title属性对应的值
title=soup.find_all("p","title")
area=soup.find_all("p","gray6 mt12")
concretedata = soup.find_all("p","font15 mt12 bold")
price = soup.select("#listBox > div.houseList > dl > dd > div.moreInfo > p > span")
dic = []
for title, price, concretedata, area in zip(title, price, concretedata, area):
# 对concretedata中的内容去空格并切片
detail = concretedata.get_text().strip().split('|')
# 准备好写入字典的内容
last_data = {
"title": title.get_text().strip(),
"fj":detail[1][0:1].strip(),
"mj": detail[2][0:-1].strip(),
"price": price.get_text().strip(),
"concretedata":concretedata.get_text().strip(),
"area": area.get_text().strip('-'),
"district":area.get_text()[0:2]
}
#添加到dic列表
dic.append(last_data)
#print(title.get_text().strip() +'\t'+ concretedata.get_text().strip() + '\t'+ price.get_text().strip() + '\t'+area.get_text().strip())
#返回列表
return dic
header = ['title','fj','mj','price','concretedata','area','district']
# 用追加的方式打开result.csv文件
fp = open('result.csv','w+')
url = "http://zu.wz.***.com/house"
f_csv = csv.DictWriter(fp,header)
# 在打开的文件中写入列标签
f_csv.writeheader()
# 在csv写入返回的所有房产信息
f_csv.writerows(getData(url))
# 循环爬取多个网页中的数据
for i in range(2,9):
url1 = url + '/i3' + str(i)
# 保存数据至打开的文件中
f_csv.writerows(getData(url))
fp.close() |
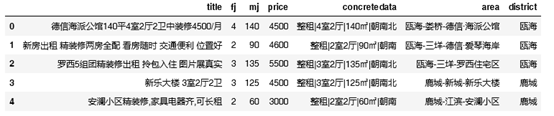
不难发现,通过API来爬取网站信息就很容易访问到珍贵的数据。但大部分商家并不太希望有人去大量地下载这些有用的数据。因为开放这些数据会催生许多有价值的消费应用程序,对原商家来说无疑是一笔财富的流出。所以很多网站会对数据做了封装,让数据变得不容易被爬取。因此,有时要深入分析页面源码。


