
网络数据一次爬取
任务1.1:从网页中爬取数据,假设爬取的数据URL为“https://www.***.com”。
步骤一:准备环境,添加并配置urllib包。
步骤二:撰写如下代码。
| # 导入包 import urllib # 向网页https://www.***.com发起请求 # 打印utf-8解码后的内容 |
步骤三:将对应URL位置“https://www.***.com”置入对应的网址,运行代码,示例部分结果如下图所示。

任务1.2:模拟成不同的浏览器,爬取“https://www.***.com”。
| import urllib # 模拟Magic Browser向服务器发起请求 # 打开请求访问的网页 # 从网页中读取数据 |
返回结果如下

为什么要这么做?就爬虫、反爬虫、反反爬虫说说你的认识。
下面就如何实现网页下载器,做一个简单的介绍:
任务1.3:从网站“http://movie.***.com/”中获取“热门电影”列表数据。
在进入到具体的任务之前,我们先来看一段视频,对任务具体情况做一个简单介绍,并完成网页下载器的功用。
步骤一:使用浏览器访问页面,需要获取数据部分的示例如下图所示,查看热门电影部分对应的源码。

步骤二:撰写代码,获取网页数据。参考代码如下:
| #!/usr/bin/Python |
步骤三:运行代码,返回页面结果。
步骤四:解析网页文件。
为完成页面的解析,要了解页面的结构,取出我们需要的数据。页面结构及网页解析说明如下:
从爬取的内容中,可以找到热门电影部分。找到某一部热门电影对应的网页数据源码结构部分。示例如下,显示的是热门电影名为“复仇者联盟4:终局之战(2019)”的源码,加粗加框且灰色背景部分的文字即是计划需要抽取的目标内容。
| <dl id="topMovieSlide"> <dd id="top_218090" movieid="218090" year="2019" month="4" day="24" pan="Dis-HotMovie1"> <em>1</em> <p> <a href="http://movie.***.com/218090/" target="_blank" title="复仇者联盟4:终局之战/Avengers: Endgame(2019)"> <img src="http://img5. .***..cn/mt/2019/03/29/095608.66203322_175X262X4.jpg" width="175" alt="复仇者联盟4:终局之战/Avengers: Endgame(2019)" /></a></p> <h3><a href="http://movie. .***..com/218090/" target="_blank"title="复仇者联盟4:终局之战/Avengers: Endgame(2019)">复仇者联盟4:终局之战(2019)</a></h3> <p><span></span> <span class="c_green px14"></span> </p> </dd> |
为获得最新的热门电影,我们需要从源码中解析出10部热门电影对应的位置,并对其中的标记语言进行分析和提取。撰写代码时,首先找到每一部热门电影对应的位置,然后按上述结构对该模块进行切分。代码如下:
| import re # 找到热门电影对应源码的起始位置 |
步骤五:存储并输出爬取的关键数据
以当前日期为文件名,保存这10部电影,代码说明在下面的视频中:
代码如下:
| import time # 新建一个以本地时间命名的文本文件 |
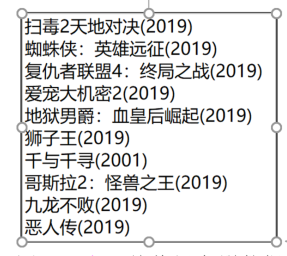
步骤六:打开存储的文件,检查下载的数据。文件中显示的内容如图所示。
网络数据定时爬取
为实时地查看最新的热门电影,可在系统中添加定时任务,定时执行代码从网站上获取最新的数据并存储。在windows系统中,可以使用【任务计划】来完成;而在Linux中,可使用crontab命令来设置定时任务。
Windows系统中进入【控制面板】【管理工具】【任务计划程序】【创建任务】来添加新的定时任务。添加新任务时,需要建立新的触发器,进入【触发器】页签后,点击新建触发器。
花一分钟简单说明一下,windows中计划任务功能:

