
数据解析
无论来自何处的数据,最终获取的结果都可能会存在缺陷。例如,票房是否都为正数?只有好的数据质量,才能保证后面的模型和分析的正确性。而我们得到的数据也可能是缺失的或不完整的,因此数据检查这一步是非常关键的。无论何种类型的数据都要检查其极端情况,检查时可以进行简单地统计、测试和可视化操作。
数据解析包括检查、清洗与筛选等过程。数据清洗是对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。数据清洗从名字上也看得出就是把“脏”的“洗掉”,是发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值、缺失值等。因为获得的数据是面向某一主题的数据集合,这些数据可能是从多个业务系统中抽取而来的,也可能包含各项历史数据,这样就避免不了部分数据是错误数据或有的数据相互之间有冲突,这些错误的或有冲突的数据都不是我们想要的,称为“脏数据”。我们需要按照一定的规则把“脏数据洗掉”,这就是数据清洗。数据清洗的一般过程如图所示。
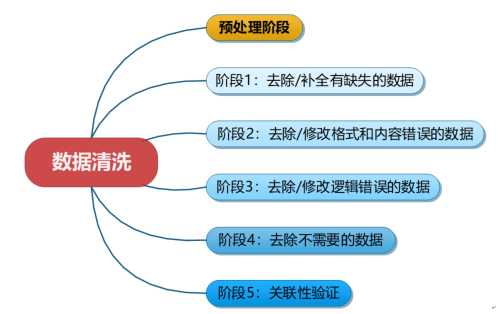
数据清洗的任务是过滤掉不符合要求的数据,将过滤的结果交给业务主管部门,确认是过滤掉,还是由业务单位修正之后再进行抽取。不符合要求的数据主要有不完整数据、错误数据、重复数据三大类。数据清洗一般是由计算机而不是人工完成的。接下来,我们尝试使用计算机程序删除不完整的数据。
任务2.1:从数据项中去除票房数据项为空的“脏数据”
参考代码如下:
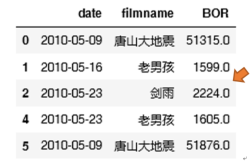
# 数据清洗:去掉缺掉含NaN的数据行
film= film.dropna()
film.head()
结果如下:
数据清洗相关讲解见以下视频:
任务2.2:从数据中筛选电影名称为“老男孩”的数据。
参考代码如下:
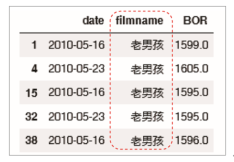
# 筛选出电影名filmname列值为老男孩的数据
film_boy= film[(film.filmname == '老男孩')]
film_boy.head()
结果如下:
任务2.3:从数据中筛选放映日期为2010年5月后半月的电影数据。
参考代码如下:
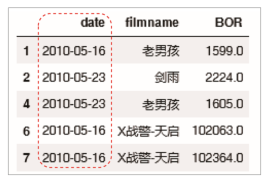
# 将date列即放映时间转换为日期型
film['date'] = pd.to_datetime(film['date'])
# 筛选出放映时间为2010年5月后半月的电影数据
film_date = film.loc[ (film['date']>'2010-5-15') & (film['date']<= '2010-5-31')]
print(film_date)
结果如下:
实验与练习
完成上述所有操作,同时完成以下练习
筛选票房数据“>1600”且名称为“老男孩”或“剑雨”的数据行、
数据筛选相关讲解见以下视频:
上机实践操作:请花25分钟的时间,完成实验报告第二部分(数据解析)的内容。

