第七章 概率与归纳法
A.问题的提出
归纳的问题是一个复杂的问题,它有着不同的方面和分支。我将从叙述单纯列举的归纳法这个问题开始。
1.那个与它比较起来其他都是次要的基本问题是:已知一个类α中许多实例都已发现属于一个类β,那么这种情况使得(a)下一个α将是一个β,或者(b)所有的α都是β,具有概然性吗?
2.如果这两者之一并不普遍为真,那么对于α和β有没有可以发现使它为真的限制?
3.如果加以适当限制这两者之一都为真,那么在这样的限制下,它是一个逻辑的定律还是一个自然界的定律?
4.它可以从某个其他原理推导出来吗?例如自然界的种类,凯恩斯的有限变异说,法则的支配,自然界的齐一性,或者其他原理。
5.归纳原理应当用一种不同形式说出来吗?也就是说:已知一个假设h具有许多已知的真的后果并且没有已知的假的后果,这件事实能使h具有概然性吗?如果在一般情况下不能,在适当情况下它能做到这一点吗?
6.在归纳公设为真的情况下将使已被公认的科学推论正确有效的归纳公设的最低限度形式是什么?
7.有没有任何理由,并且如果有的话是什么理由,使得我们认为这个最低限度的公设为真?或者,如果没有这类理由,是否还有按照假定它为真来行动的理由?
在这些讨论中我们需要记住一般所用的“概然的”这个词在意义上的含混不清。当我说在某些情况下,“大概”下一个α将是一个β时,我希望能够按照有限频率说来解释这个现象。但是如果我说归纳原理“大概”是真的,我一定是在用“大概”这个词来表示高度的可信性。如果不把“概然的”这个词所具有的这两种意义适当划分开来,就很容易发生混淆。
我们将要进行的这个讨论具有一段可以认为是从休谟开始的历史。就很多次要问题来说,我们已经取得了确定的看法;有时这些次要的问题人们当初并没有看出来。但是我们现在进行的研究已经使我们看得相当清楚:得出成果的技术上的讨论对于主要问题的阐明并没有起多大作用,这个主要问题大体上仍然和休谟留下来的情况一样。
B.单纯列举的归纳法
单纯列举的归纳法就是下面这个原理:“已知有n个数目的α已经发现为β,并且没有α已经发现不是β,那么这两个陈述:(a)‘下一个α将是一个β’,(b)‘所有的α都是β’就都具有一种随着n的增加而增加的概率,并且当n接近无限大时接近必然性而以它为极限。”
我将把(a)叫作“特殊归纳”,而把(b)叫作“一般归纳”。这样(a)将根据我们关于过去人类都有死的知识推断某某先生也有死,而(b)则将推断大概所有的人都有死。
在我们还没有接触到较难或有疑问的论点之前,某些比较重要的问题却可以比较容易地得到解决。这些问题是:
1.如果归纳要完成我们期望它在科学中所完成的任务,“概率”的解释就必须使得一个概率陈述断言一件事实;这就要求所涉及的那种概率应当从真与伪推导出来,而不是一个不能下定义的概念;而这一点又能使有限频率的解释或多或少成为不可避免的解释。
2.归纳在应用到自然数列的时候显然是无效的。
3.归纳作为一个逻辑原理是无效的。
4.归纳要求它所根据的实例是一个级数,而不仅仅是一个类。
5.为了使这个原理有效,不管需要规定什么限制,必须通过给α和β这些类下定义的内包的说法表达出来,而不是通过外延的说法。
6.如果宇宙中的事物数目是有限的,或者只有某个有限类对于这种归纳有关,那么就一个足够大的n来说,归纳就成为可以证明的东西;但是在实际应用上这一点并不重要,因为这里所说的n比任何实际研究中可能遇到的一定更大。
我现在就来证明这些命题。
1.如果我们把“概然性”当作一个不可下定义的概念,我们就不得不承认不大可能的事也可能发生,因此一个概率命题关于自然界的进程并没有向我们提供任何知识。如果我们采取这个看法,归纳原理就可能是正确有效的,然而每个符合这个原理的推论却可能证明为伪;这是不大可能,但并非不可能的事。因此,一个使归纳为真的世界在经验界中是不能与一个使归纳为伪的世界区别开来的。由此可以看出永远不可能找出任何支持或反对这个原理的证据,并且它也不能帮助我们推论将要发生的事。如果这个原理要达到它的目的,我们就必须把“概然”的意思解释为“实际上通常发生的事物”;这就是说,我们必须把一个概率解释为一个频率。
2.算术中的归纳 在算术中我们容易找出导致正确结论的归纳实例,也容易找到其他导致错误结论的归纳实例。耶方斯举出两个实例:
5,15,35,45,65,95
7,17,37,47,67,97
在第一行中,每个以5结尾的数都可以被5整除;这就使人推想每个以5结尾的数都可以被5整除,而这是对的。在第二行中,每个以7结尾的数是一个质数;这也可能使人推想每个以7结尾的数都是质数,而这却是错误的。
或者让我们看:“每个为偶数的整数是两个质数的和。”每个试过的实例都说明这是对的,而这样的实例在数量上是很大的。然而人们对于它是否永远为真这一点却一直抱着合理的怀疑。
作为算术归纳的一个明显失败的例子,让我们看下面这个实例[10]:
使π(x)为≤x的质数的数目
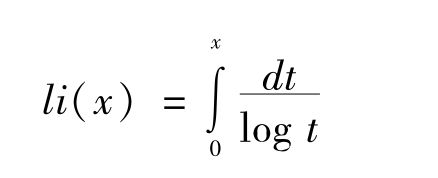
我们知道当x数大时,π(x)和li(x)几乎相等。我们还知道对于每个已知的质数来说,
π(x)<li(x)
高斯推想过这个不等式永远为真。人们试过所有107以下的质数以及许多超过107的质数,都没有发现不能成立的个别情况。然而里脱伍德在1912年却证明对于无限数目的质数来说这个不等式不能成立,斯古士(《伦敦数学学会通报》,1933年)也证明这个不等式对于某个小于
34
10
10
10
的数不能成立。我们将看到高斯的推想尽管已经证明是错误的,它却具有甚至比我们最坚信不疑的关于经验界的概括所依靠的要好得多的归纳证据。
我们很容易无限制地得出算术中的错误归纳,而无须过多地涉及数论。举例来说,小于n的任何数都不能被n整除。我们可以使n任意增大,这样就为“任何数目都不能被n整除”这个概括找到尽可能多的有利的归纳证据。
显然任何n个整数一定具有大多数整数所不具有的许多共同性质。举一件事情来说,如果m是其中最大的数,它们就都具有不比m大这个无限罕见的性质。所以如果应用到整数上来,无论一般的还是特殊的归纳都不是正确有效的,除非在它身上应用归纳的那种性质具有某些限制。我不知道怎样说出这种限制,然而任何一个有能力的数学家关于那种可能得出一个后来证明正确有效的归纳的性质都具有一种类似常识的觉察力。如果你看到1+3=22,1+3+5=32,1+3+5+7=42,你就会容易推想到
1+3+5+……+(2n-1)=n2
并且我们可以很容易证明这个想法是正确的。同样,如果你看到13+23=32,13+23+33=62,13+23+33+43=102,你就会推想到靠前面的n个立方的和永远是一个平方数,而这又是很容易加以证明的。对于这类归纳来讲,数学的直观并不是永远可靠的,但是有能力的数学家运用直观时对的次数似乎比错的次数要多。但是我不知道怎样讲明白在这类情况下指导数学直观的那种东西。另外,我们只能够说还没有任何已知的限制能使应用到自然数上的归纳有效。
3.归纳作为一个逻辑原理是无效的显然如果我们可以任意选择我们的类β,我们就可以很容易地确信我们的归纳将要失败。设a1,a2,……an为α中直到现在已经观察过的分子,并已发现它们都是β的分子,另外设an+1为α的下一个分子。就纯粹逻辑的范围而论,β也许只由a1、a2,……an这些项目组成;或者它也许是由把an+1除外的宇宙中所有事物组成;或者它也许是由任何介乎这两者之间的任何类组成。就这类情况中无论哪一种情况来说,推论到an+1的归纳都是错误的。
显然(反对的人可能说)β必须不是一个也许可以叫作“制造出来的”类,即一个部分地由外延得到定义的类。在归纳推论中所研究的那类例子中,β永远是一个通过内包而不是通过外延来知道的类,除了那些被观察到的分子a1,a2,……an以及那些不同时是α的分子而又碰巧可能被观察到的β的分子。
我们很容易作出显然错误的归纳。一个乡下人可能会说:所有我曾看到的牛都在希尔福郡内,所以大概所有的牛都在这个郡内。或者我们可以提出:所有现在活着的人都没有死去,所以大概所有现在活着的人都不会死。这类归纳中的谬误是很明显的,但是如果归纳是一个纯粹逻辑的原理,这些就不是谬误。
因此显然如果要归纳不能证明为伪,β这个类必须具有某些特点,或者必须与α这个类具有某种特殊关系。我并不是主张有了这些限制这个原理就一定为真;我所主张的是没有这些限制这个原理就一定为伪。
4.在经验界的素材中,事例都是按照时间顺序发生的,因而它们永远是成系列的。当我们研究归纳是否可以在算术中应用的时候,我们自然想到按照大小排列起来的那些数字。但是如果我们可以任意排列它们,我们就可以得到奇怪的结果;例如,像我们已经看到的那样,我们可以证明一个任意选取的数不为质数的可能是无限小的。
在表述特殊归纳时重要的是应当有下一个例子,这就要求排成系列。
要让普遍归纳具有说服力,我们就必须知道α的前n个分子发现是β的分子,而不仅知道α和β具有n个共同分子。这也要求排成系列。
5.假定我们承认如果要归纳推论正确有效,在α和β之间就必须有着某种关系,或者它们当中一个必须有着某个特点,由于这种关系或这个特点它才正确有效,那么显然这种关系必须是介乎内包之间的——例如介乎“人”和“有死的”之间或者介乎“反刍动物”和“分蹄的”之间。我们打算推论出一种外延关系,但是在我们处理经验界中不断发现新的分子的一些已知类时,我们起初并不知道α和β的外延。每个人都会承认“狗吠”是一个正确的归纳;我们预料到一种动物的视觉外形与它发出的声音之间的相互关联。这种预料当然也是另一种范围更大的归纳的结果,但这并不是目前我所要谈的问题。我所要谈的是介乎都是内包的一种形状与一种声音之间的相互关联以及某些内包看来好像比某些其他内包更可能具有归纳上的关系这件事实。
6.这一点是明显的。如果宇宙是有限的,完全的列举在理论上就是可能的,在完成这项工作之前一般的概率计算表明归纳大概是正确有效的。但是在实际应用上这种想法并没有什么重要性,这是因为我们能够观察的事物与宇宙中事物在数量上过分悬殊的缘故。
让我们回到那个一般原理上来,记住我们必须找出某些使它可能正确有效的限制。让我们先看特殊归纳。特殊归纳说,如果我们发现任意选出的属于α的n个分子完全由β的分子组成,那么下一个α将是一个β就是可能的;换句话说,大多数剩下的α是β。这句话本身只需要具有概然性。我们可以假定α是一个有限类,比方说包括N个分子。我们知道其中至少有n个是β的分子。如果同时为β的分子的α的分子总数是m,那么选择n个项目的方法总数是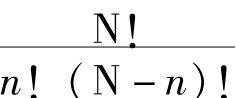 [11],而选择n个为α的项目的方法总数是
[11],而选择n个为α的项目的方法总数是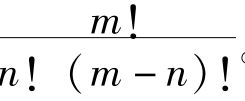 。因此一个完全由α组成的选择机会是
。因此一个完全由α组成的选择机会是
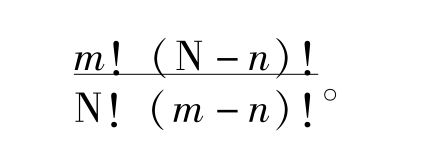
如果pm是m作为α和β的共同项目数的先验可能性,那么在经验后出现的可能性就是
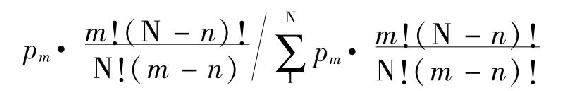
让我们把它叫作qm。
如果α和β的共同分子数是m,那么取出n个为β的α之后,还有m-n个β和N-m个非β。所以,根据α和β有m个共同分子的假设,我们得出另一个β的概率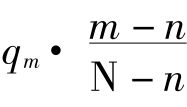 。因此总的概率是
。因此总的概率是
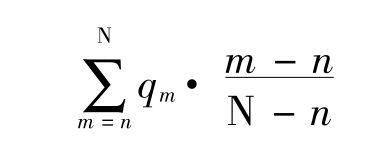
这个式子的值完全要看pm的值来定,而pm的值并没有正确有效的计算方法。如果我们和拉普拉斯一样,假定m的每个值具有相同的概率,我们就得到拉普拉斯的结果,即下一个α是β的机会是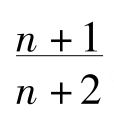 。如果我们先验地假定每个α为β和不为β是同样可能的,那么我们就得到1/2的值。即使我们有拉普拉斯的假设,普遍归纳也只有
。如果我们先验地假定每个α为β和不为β是同样可能的,那么我们就得到1/2的值。即使我们有拉普拉斯的假设,普遍归纳也只有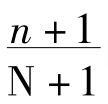 的概率,通常这是个较小的值。
的概率,通常这是个较小的值。
因此我们需要某种在m接近N时使得pm为大数的假设。这将必须依靠α和β两类的性质,如果我们要让它具有正确有效机会的话。
C.归纳的数学处理
从拉普拉斯那时以来,为了证明归纳推论的概然真理来自数学的概率论,人们曾经作过各种不同的尝试。现在大家认为这些尝试都不成功,并且认为如果要使归纳论证正确有效,就必须借助于不是属于逻辑学家所可能想到的在逻辑上可能的各个不同的世界,而是属于现实世界的某种超出逻辑范围的特点。
这类论证中第一个就是由拉普拉斯提出的。它的正确的纯数学形式有如下面所说:
有n+1个外形相似的口袋,每个口袋里有n个球。第一个口袋里的球都是黑球;第二个口袋里有一个白球,其余是黑球;第(r+1)个口袋里有r个白球,其余是黑球。我们选择其中一个不知包含什么的口袋,并从中取出m个球。结果发现这些球都是白球。那么(a)下一个取出的球是白球,和(b)我们已经选出其中都是白球的口袋的概率是多少?
答案是:(a)下一个球为白球的机会是: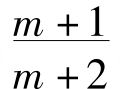 ;(b)我们已经选出其中都是白球的口袋的机会是
;(b)我们已经选出其中都是白球的口袋的机会是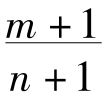 。
。
根据有限频率说这个正确的结果有一种简单明确的解释。但是拉普拉斯推论出如果已经发现m个A为B,那么下一个A为B的机会是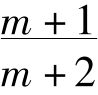 ,而所有的A都为B的机会是
,而所有的A都为B的机会是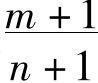 。他是通过假定给出n个我们对之一无所知的客体,其中0,1,2,……n个为B的概率都相等而得出这个结果的。当然这是一个荒谬的假定。如果我们换用一个荒谬程度稍小的假定,即认为每个客体为B或不为B的机会相等,那么下一个A为B的机会仍然是1/2,尽管已经发现许多A为B。
。他是通过假定给出n个我们对之一无所知的客体,其中0,1,2,……n个为B的概率都相等而得出这个结果的。当然这是一个荒谬的假定。如果我们换用一个荒谬程度稍小的假定,即认为每个客体为B或不为B的机会相等,那么下一个A为B的机会仍然是1/2,尽管已经发现许多A为B。
即使我们接受他的论证,如果n比m大得多的话,普遍归纳仍然不大可能,虽然特殊归纳可能变得具有很大的概然性。事实上他的论证已经成了只有历史兴趣的东西。
凯恩斯在他的《概率论》中对于归纳作出了纯粹数学可能作出的最好处理,并且最后认为归纳是不充分的。他得出下面的结果:
设g是一个概括性命题,x1,x2,……是有利于这个命题的观察到的实例,h是在有关范围内的一般外界条件。
假定x1/h=x2/h=等等。
使pn=g/h x1x2……xn。
这样pn就是普遍归纳在有了n个有利的实例之后的概率。写出g
表示g的否定,p0表示g/h,即这个概括命题的先验概率。
那么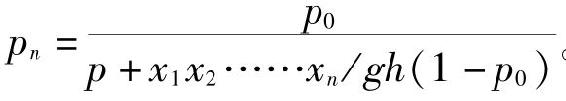 。
。
当n增加时,它就接近于1而以1为极限,如果
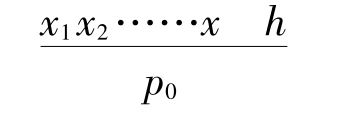
接近于0而以0为极限的话;如果有着有限量ε和η使得对于所有足够大的r来说,
xr/x1x2……xr-1ḡgh<1-ε 并且p0>η,
那么上面那种情况就会发生。
让我们研究一下这两种情况。第一种情况说有一个小于1的量1-ε,在这个概括性命题为伪的情况下,使得在出现一定数目的有利实例之后,出现下一个有利于这个概括的概率永远小于这个量。让我们看它的一个失败的例子,即“所有的数都不是质数”这个概括。当我们顺着数列看下去时,质数越来越少,在出现r个非质数之后下一个数本身为非质数的机会就会增加,并且在r保持不变的情况下接近必然性而以它为极限。所以这种情况可能失败。
但是第二种情况,即g在归纳开始之前就必须具有一个大于某个有限概率的概率,却更为困难。一般来说,我们很难看出有什么方法计算这种概率。对于一个从来没有见过天鹅或听说过天鹅是什么颜色的人来说,“天鹅都是白色的”具有多大的概率呢?这类问题是既不清楚而又意思含糊的,凯恩斯也看出这类问题使得他的结论不够令人满意[12]。
有一个简单的假设可以得出凯恩斯所需要的那种有限概率。让我们假定宇宙中事物的数目是有限的,比方说是N。设β是一个由n个事物组成的类,并且设α是一个由任意选取的m个事物组成的类。
那么可能出的α的数目是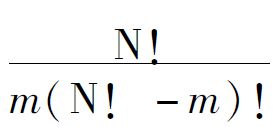 ,并且这些可能出现的α包含在β内的数目是
,并且这些可能出现的α包含在β内的数目是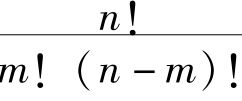 。所以“所有的α都是β”的机会是
。所以“所有的α都是β”的机会是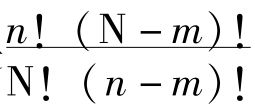 ,而这是个有限数。这就是说,我们对之没有任何证据的每个概括性命题为真的机会都是一个有限数。
,而这是个有限数。这就是说,我们对之没有任何证据的每个概括性命题为真的机会都是一个有限数。
可是我却担心,如果N像爱丁敦所认为的那样大,那么使得一个归纳概括具有很高概率所需的有利实例的数目将会大大超过实际可能发现的有利实例的数目。所以这种摆脱困难的方法从理论上看尽管很好,却不能用来为科学实践找到合理的根据。
先进科学使用的归纳法与简单列举的归纳法有些不同。首先要有许多观察到的事实,然后有一个与所有事实都相一致的一般理论,然后又从这个理论引导出为以后的观察所证实或推翻的推论。这里的论证依靠反概率原理。设p为一个一般理论,h为已经知道的数据,q为有关p的一个新的实验数据。那么
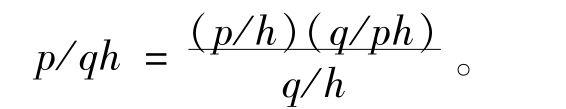
在最重要的情况下,q是从p和h得出的结果,所以q/ph=1。因此,在这种情况下,
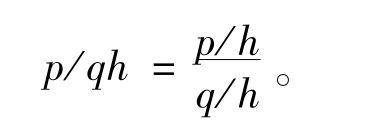
由此可以看出如果q/h的值很小,q的证实就大大增加了p的概率。可是这却不具有人们可能希望得到的那些结论。如果用“Ṗp”表示“非p”,我们就有
q/h=pq/h+Ṗq/h=p/h+Ṗq/h
因为在已知h的情况下,p蕴涵q。这样如果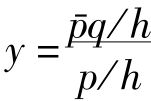 ,我们就有
,我们就有
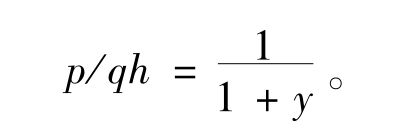
如果y的值小,那么这将是一个很大的概率。现在有两个条件可以使y的值小:(1)如果p/h的值大,(2)如果Ṗq/h的值小,也就是p伪而使q变得不大可能的那种情况。计算这两个因子所遇到的困难正和凯恩斯的讨论中所出现的困难一样。为了算出p/h,我们需要具有某种在发现使我们想到p的个别证据之前,计算p的概率的方法,而这种方法却是不容易找出来的。我们看得清楚的只是如果一个让我们想到的定律在发现任何有利于它的证据之前就具有相当大的概率,那就一定要依靠一个大意是说某种相当清楚的简单定律必然为真的原理。但这却是一个困难的问题,我在以后还要谈到它。
在某些种类的情况下,对于Ṗq/h进行近似计算具有更大的可能。让我们拿海王星的发现作例。就这个实例来讲,p是万有引力定律,h是海王星发现以前关于行星运动的观察,而q是海王星存在于计算表明它所应该存在的地方。这样Ṗq/h就是在万有引力为伪的情况下,海王星出现于它所在的地方的概率。这里我们必须对于我们所用的“伪”这个词的意思作出一条规定。就这个词的适当意思来讲,认为爱因斯坦的理论证明牛顿的理论为“伪”是不正确的。在肯定一切表示数量的科学理论时都应该保留误差范围;如果做到了这一点,牛顿的万有引力学说对于行星运动来说就仍然为真。
下面的论证看来似乎令人抱有希望,但是在事实上却是不正确的。
就我们所举的实例来讲,脱离开p或者某个一般定律,h对于q就是无关的;这就是说,对于其他行星的观察不能使海王星的存在具有比原来更多或更少的概率。至于其他定律,我们也许可能认为波得定律使得有一个大体具有海王星轨道的行星存在从大体上看是可能的,但是它却不能指明在某一特定日期行星已经走过的一段轨道。如果我们假定波得定律以及万有引力以外的任何其他有关定律给予认为有一个大体沿着海王星轨道运行的行星的假定以概率x,并且假定对于海王星的视位置的计算带有误差范围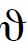 ,那么海王星在它所在的位置被发现的概率就将是
,那么海王星在它所在的位置被发现的概率就将是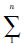 /2π。现在的值很小而x的值也不能认为很大。所以Ṗq/h,这个值等于x×/2π,就必然很小。假定我们把x作为1/10,作为6分钟,那么Ṗq/h=1/10×1/3600=1/36,000。所以如果我们假定p/h=1/36,我们就将有y=1/1000和
/2π。现在的值很小而x的值也不能认为很大。所以Ṗq/h,这个值等于x×/2π,就必然很小。假定我们把x作为1/10,作为6分钟,那么Ṗq/h=1/10×1/3600=1/36,000。所以如果我们假定p/h=1/36,我们就将有y=1/1000和
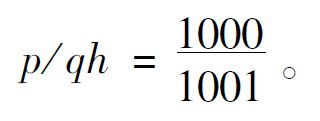
这样,即使在海王星被发现之前,万有引力定律像掷骰子出双六那样不大可能,在发现之后它却具有1000比1的有利情况。
这个论证如果推广到所有观察到的有关行星运动的事实,显然表明如果万有引力定律在最初被人提出来的时候即使具有很小的概率,它不久就几乎成了带有必然性的东西。但是它却丝毫不能帮助我们估计这种最初的概率,因此即使它真,也不能为我们从观察到理论中间所作的理论性质的推理提供稳固可靠的基础。
另外,上面这种论证由于以下的事实也可以受到人们的反对,即万有引力定律并不是使人预料海王星在它原来的地点出现的唯一定律。假定万有引力定律在时间t以前一直为真,这里t是发现海王星之后的任何一个时刻;那么我将仍然有q/p′h=1,这里p′表示认为这个定律只是到t以前一直为真的假设。所以我们有比纯粹机会或者纯粹机会和波得定律加起来更多的理由来预料海王星的发现。这个定律直到那时一直为真这件事已经成为具有很大概然性的事情。推论它在将来有效就需要一个绝不能从数学的概率论中推导出来的原理。这种想法破坏了建设一般理论的归纳论证的全部力量,除非这种论证受到某种类似人们所认为的自然的齐一性的原理的支援。在这里我们又一次看到归纳需要某种超出逻辑范围、不依靠经验的普遍原理的支持。
D.莱新巴哈的理论
莱新巴哈的概率论的特点在于归纳就包含在概率的定义之中。这个理论有如下述(略加简化):
已知一个统计上的系列——例如生死统计上的系列——并且已知包含该系列中某些分子的部分重合的两个类α和β,我们常常发现当项目数大时,α的分子为β的分子的百分数大体上保持不变。假定当项目超过了比方说10,000时,人们发现记录下来的α为β的比例永远不能大大超过或不及m/n,并且这个有理分式比任何其他分式都更加接近平均观察到的比例。这样我们就“假定”不管这个系列怎样扩展,比例将永远接近m/n。我们把一个α为一个β的概率定义为在观察次数无限增加时观察到的频率的极限,借着我们的“假定”,我们认为这个极限是存在的并且就在m/n的邻域中,这里m/n是可能得到的最大实例中所观察到的频率。
莱新巴哈明确断言任何命题都不带必然性;所有命题都只具有不同程度的概然性,并且每个概率都是一个频率的极限。他承认,根据这种理论,计算频率所用的那些项目本身也只具有概然性。拿死亡率作例来看:当我们判断一个人死了之后,他可能仍然活着;因此死亡统计中每一项都是可以怀疑的。根据定义,这就表示一次死亡的记录一定是一系列记录当中的一个,而这个系列中有些记录是正确的,有些则是错误的。但是那些我们认为正确的记录也只具有概然的正确性,并且必定是某种新的系列的分子。这一切他都承认,但是他说到了某个阶段我们就结束了这种无止境的后退,而采取一种他所谓的“盲目假定”[13]。一个“盲目假定”是认某个命题为真的一次决定,尽管我们并没有这样做的充分理由。
在这个理论中有两种“盲目的假定”,也就是:(1)在这个统计系列中我们选取当作基本项目的那些最终项目;(2)认为在有限次数的观察中发现的频率,不管观察次数怎样增加,大体上会保持不变的那个假定。莱新巴哈认为他的理论是完全属于经验范围的,因为他并不断言他的“假定”为真。
我现在并不是要研究莱新巴哈的一般理论,这种理论已经在前面一章里谈论过。我现在要研究的只是他关于归纳的理论。他的理论的要点是:如果他的归纳假定为真,那么预测就是可能的,否则预测就是不可能的。因此我们唯一能够得到支持一种预测而不是另一种预测的概率的途径就是设想他的假定为真。我并不是想否认要得到支持预测的概率就需要某种假定,我想否认的是所需要的那种假定就是莱新巴哈的假定。
他的假定是:已知α和β两个类,并且已知α的实例是按照时间顺序排好的,如果我们在观察了充分数目的α之后,发现α为β的比大体上永远是m/n,那么不管以后可能观察到多少个α的实例,这个比例将仍然继续保持下去。
我们首先看到这个假定仅仅在表面上比那个应用到所有观察到的α都是β的情况上的假定具有更大的普遍性。因为在莱新巴哈的假设中由α组成的系列的每一段落都具有大约m/n的分子为β的性质,并且我们可以把那个比较狭义的假定应用到这些段落上去。因此我们可以只研究那个比较狭义的假定。
因此莱新巴哈的假定和下面的话意义相同:在我们观察了大量的α,并且发现所有的α都是β之后,我们就将假定所有的α几乎可以都是β。这个假定对于概率的定义,以及一切科学预测来说都是必要的(他这样认为)。
我认为这个假定可以证明是错误的。假定α1,α2,……αn是已经观察过并且发现是属于某一类β的α的分子。假定αn+1是要观察到的下一个α。如果它是一个β,那么把不包括αn+1在内的由β组成的类来代替β。对于这个类来说,这种归纳就无能为力。这种论证显然还可以推广。由此可以看出,如果要让归纳具有正确有效的机会,α和β就不能是任意的类,而必须是具有某些性质或关系的类。我的意思并不是说α和β之间存在着一种适当关系时归纳就一定正确有效,我只是说在这种情况下归纳可能正确有效,而就它的一般形式来讲,它却可以证明是错误的。
α和β一定不是可以叫作“制造出来”的类,这一点似乎是明显的。我想把上面出现的不包括αn+1在内的β叫作一个“制造出来”的类。广义来讲,我所说的一个“制造出来”的类是一个通过说出某某一项是或不是它的一个分子而得出至少是它的一部分定义的。这样,“人类”就不是一个制造出来的类,但是“不包括苏格拉底在内的全部人类”却是一个制造出来的类。如果α1,α2,……αn+1是α的最先观察到的n+1个分子,那么α1,α2,……αn就具有不是αn+1的性质,但是我们一定不能用归纳的方法推论出αn+1具有这种性质,不管n可能有多么大。α和β这些类必须通过内包,而不是通过说出它们的分子来得到定义。任何为归纳提供合理根据的关系一定是一种概念的关系,并且由于不同的概念可能给同一个类下定义,所以可能出现一对在归纳上相关并分别替α和β下定义的概念,而另外一些成对的概念虽然也替α和β下定义,在归纳上却不相关。例如,我们可以根据经验推论出无羽毛的两足动物是有死的,但却不能推论出地球上居住的理性动物是有死的,尽管存在着这两个概念碰巧替同一个类下定义这件事实。
数理逻辑就它迄今为止的发展来看,是以尽可能做到外延的处理为其目的的。也许这是一个多少带有偶然性的特点,来自算术对于逻辑学家的思想和意图所产生的影响。与此相反,归纳的问题却要求做到内包的处理。固然在一个归纳推论中出现的α和β这些类,就观察到的实例α1,α2,……αn来讲,是以外延方式表达出来的,但是超过了这一点,重要的却是这两个类直到现在只以内包方式表达出来。举例来说,α可能是血液中有某些杆状菌的那一类人,而β则可能是出现某些症状的那一类人。归纳的最重要的性质就是人们事先并不知道这两个类的外延。在实际应用上,我们认为某些归纳值得证实,而另外一些归纳则不值得证实,我们还似乎受着一种对于很可能具有联系的那些种类的内包的觉察力的引导。
因此莱新巴哈的归纳假定不仅过于广泛而且还太偏重外延。如果莱新巴哈的假定不想成为可以证明是错误的东西,我们就需要有某种范围较窄和偏重内包的假定。
我们对于莱新巴哈关于不同等级频率的理论还要谈论一下,这些不同等级频率最后导致一组“盲目假定”的概率。这是和他认为在逻辑中应该用概率来代替真理的学说分不开的。让我们通过一个实例来看这个理论,比方说一个六十岁的英国人在一年内死去的机会。
第一阶段是简单明白的:把文件上的记载当作完全正确的东西,然后以总人数去除去年死去的人数。但是我们现在记得统计中每一个项目都可能是错误的。为了计算这个概率,我们必须得到某组经过仔细研究的类似的统计,并且发现其中所含错误的百分比。我们还记得那些认为他们发现错误的也可能弄错,于是我们就开始去统计关于错误的错误。在这种后退的某一阶段我们势必停顿下来;不管我们在什么地方停顿下来,我们习惯上总会给它一种“分量”,这种分量人们认为大概不是必然性就是我们猜想在后退的下一阶段会出现的那种概率。
作为一种认识论来看,这种方法有着许多可以反对的理由。
首先,在后退中靠后的阶段通常比靠前的阶段要困难和不确定得多;我们不大可能,比方说,在对于官方统计的错误所作的估计上,达到官方统计本身所达到的正确性。
其次,那些我们必须当作出发点的盲目假定是一种想使心灵与肉体两个世界取得调和的努力:盲目假定要完成的任务就是数据在我的体系中所要完成的任务,数据可能是错误的,但是莱新巴哈想通过把它们叫作“假定”而逃避开认它们为“真”所承担的责任。在选择一个假定而不是另一个假定的时候,除了他认为这个假定更有可能为“真”以外,我看不出还有什么别的理由;并且因为,照他自己的话来讲,这并不表示(当我们处在盲目假定这个阶段时)存在着使这个假定具有概然性的某种已知的频率,所以他才不得不凭借频率以外的某种其他标准来挑选假设。他并没有告诉我们这可能是什么东西,因为他并没有觉察出它的必要性。
第三,如果我们为了结束无止境的后退而抛弃盲目假定完全属于实用方面的需要,并且从纯粹理论方面观察莱新巴哈的概率可能表示的意思,我们就会感到自己陷进了难以解决的复杂情况之中。在第一等级,我们说一个α将为一个β的概率是m1/n1;在第二等级,我们对于这个陈述给予概率m2/n2,这是通过使这个陈述作为某一系列类似陈述当中的一个陈述而得到的;在第三等级,我们对于认为有一个概率m2/n2支持我们的第一个概率m1/n1的那个陈述给予概率m3/n3;这样一直继续下去。如果我们能够完成这种无止境的后退的话,那么支持我们最初估计m1/n1的最后的概率会是一个无限乘积
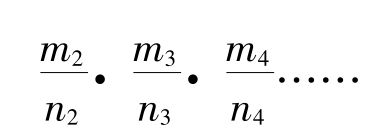
而我们可以预料这个乘积为零。因此看来在选择第一等级上概然性最大的估计时,我们几乎肯定是会错的;但是一般来说这仍然是我们可以得到的最精确的估计。
在“概然的”定义中就存在的这种无止境的后退是令人难以接受的。如果我们想避免这种无止境的后退,我们就必须承认我们原来统计中每个项目不是真便是伪,并且承认我们得到的第一个概率的值m1/n1不是对便是错;事实上我们对于概然性判断必须和对其他判断一样完全使用真—或—伪这种二分法。详尽来讲,莱新巴哈的立场有如下述:
有一个命题p1,比方说“这个α是一个β”。
有一个命题p2,说p1具有概率x1。
有一个命题p3,说p2具有概率x2。
有一个命题p4,说p3具有概率x3。
这个系列是无尽止的,并且导致(人们要这样认为)一个极限命题,只有对这个命题我们才有权力加以肯定。但是我却看不出怎样才能把这个极限命题表达出来。困难在于:就这个系列中所有先于它的分子来说,根据莱新巴哈的原理,我们没有理由认为它们为真的可能性比为伪的可能性大;事实上它们并不具有我们可以估计的概率。
我的结论是:想不用“真”和“伪”这些概念的努力是个失败,并且概然性的判断和其他判断并没有本质上的不同,而是同样包含在完全的真—伪二分法的范围之内。
E.结论
自从休谟以来,在科学方法的讨论中归纳一直起着非常重大的作用,所以弄清楚上面的论证所得出的结论(如果我没有弄错的话)是很重要的。
第一,数学的概率论并没有任何东西可以使我们有理由认为不管是一个特殊归纳还是一个普遍归纳具有概然性,不管有利于它的实例的确定数目有多么大。
第二,如果对于一个归纳中所涉及的A和B这些类的内包定义的性质不加什么限制,那么我们就能证明归纳原理不仅可以怀疑而且是虚妄的。这就是说,已知某一个类A的n个分子属于另外某一个类B,那么使A的下一个分子不属于B的那些“B”的值比起使下一个分子属于B的值更多,除非n不太小于宇宙中事物的总数。
第三,在一般所谓的“假言归纳”中,由于迄今为止所有它的观察到的后果都得到证实而使我们认为某一普遍理论具有概然性,这种归纳与单纯列举的归纳并没有什么重要的不同。因为如果P是所说的那种理论,A是由有关现象组成的类,而B是由P的后果组成的类,那么P和“所有的A都是B”就具有相同的意思,P的证据就是通过单纯列举得到的。
第四,如果一个归纳论证可以正确有效的话,那么归纳原理的叙述就必须加上某种迄今尚未发现的限制。在实际应用上,科学的常识在各种不同的归纳面前畏缩不前,这一点我认为是对的。但是那种指导科学的常识的东西到现在却一直没有得到明确的表述。
第五,如果科学的推理一般来说正确有效的话,它们之所以正确有效必然是借助于自然界的某个或某些定律,而这个或这些定律说出了现实世界的一种或几种综合性质。肯定这类性质的一些命题的真实性靠着来自经验的论证是连概然性也得不到的,因为这类论证一旦超出了迄今记载下来的经验的范围,它们的正确性就要依靠我们所说的那些原理。
这些原理是什么,并且如果有意义的话,那么又是在什么意义上?我们能够名副其实地认识这些原理,仍然是有待我们探讨的问题。
【注释】
[1]不要和“所有的人大概都有死”相混淆。
[2]即包含未确定的变项的句子——例如,“A是一个人”——如果我们把值给变项(在上述例子中就是A),它们就成为命题。
[3]关于“解释”,看第四部分第一章。
[4]哲学杂志《精神》,新第210号,第98页。
[5]这个极限要依靠a的顺序,因此它是在把a当作系列而不是当作类的情况下从属于a的。
[6]理查德·冯·米西斯《概率、统计与真理》第二版,维也纳,1936(第一版,1928)。汉斯·莱新巴哈《概率论》,来登,1935。并参看后者的《经验与预见》,1938。
[7]参看杰弗雷著《概率论》和《科学推论》。
[8]麦西尼,古希腊城市名。——译者
[9]是否包括Z要看我们是否把“Zoo”当作一个词来决定。
[10]看哈代的《腊玛努赞》,第16、17页。
[11]“N!”表示从1到N所有数目的乘积。
[12]我将在第六部分第二章里再来谈这个问题。
[13]《经验与预测》,第401页。