软件工程
-
1.1高等院校计算机系列教材
-
1.2前 言
-
1.3第1章 概 论
-
1.3.11.1 软件
-
1.3.1.11.1.1 软件的定义和特点
-
1.3.1.21.1.2 软件的发展
-
1.3.21.2 软件危机
-
1.3.2.11.2.1 软件危机的主要特征
-
1.3.2.21.2.2 软件危机的具体体现
-
1.3.2.31.2.3 软件危机产生的原因
-
1.3.2.41.2.4 软件危机的解决途径
-
1.3.31.3 软件工程
-
1.3.3.11.3.1 软件工程的定义
-
1.3.3.21.3.2 软件工程的背景和历史
-
1.3.3.31.3.3 软件工程的基本原理
-
1.3.3.41.3.4 软件工程工具
-
1.3.4习 题 1
-
1.4第2章 软件过程
-
1.4.12.1 软件生存周期
-
1.4.22.2 软件过程概念
-
1.4.32.3 软件过程模型
-
1.4.3.12.3.1 瀑布模型
-
1.4.3.22.3.2 演化过程模型
-
1.4.3.32.3.3 增量过程模型
-
1.4.3.42.3.4 专用过程模型
-
1.4.3.52.3.5 Rational统一过程
-
1.4.3.62.3.6 极限编程与敏捷过程
-
1.4.3.72.3.7 微软过程
-
1.4.3.82.3.8 第四代技术过程模型
-
1.4.42.4 软件过程改进
-
1.4.5习 题 2
-
1.5第3章 软件分析
-
1.5.13.1 可行性研究
-
1.5.1.13.1.1 可行性研究的任务
-
1.5.1.23.1.2 可行性研究的步骤
-
1.5.1.33.1.3 可行性研究报告
-
1.5.23.2 需求分析
-
1.5.2.13.2.1 需求分析的任务
-
1.5.2.23.2.2 需求分析的步骤
-
1.5.2.33.2.3 需求获取的方法
-
1.5.2.43.2.4 软件需求说明书
-
1.5.33.3 结构化分析方法
-
1.5.3.13.3.1 结构化分析模型
-
1.5.3.23.3.2 数据流图
-
1.5.3.33.3.3 数据字典
-
1.5.3.43.3.4 加工说明的描述工具
-
1.5.43.4 Visio的功能及使用方法
-
1.5.4.13.4.1 Visio 2007简介
-
1.5.4.23.4.2 利用Visio绘制数据流图
-
1.5.5习 题 3
-
1.6第4章 软件设计
-
1.6.14.1 软件设计的概念
-
1.6.1.14.1.1 抽象
-
1.6.1.24.1.2 模块化
-
1.6.1.34.1.3 信息隐藏与局部化
-
1.6.1.44.1.4 模块独立性
-
1.6.24.2 软件体系结构
-
1.6.2.14.2.1 软件体系结构概述
-
1.6.2.24.2.2 新型软件体系结构
-
1.6.34.3 总体设计
-
1.6.3.14.3.1 总体设计过程
-
1.6.3.24.3.2 总体设计方法
-
1.6.3.34.3.3 总体设计说明书
-
1.6.44.4 详细设计
-
1.6.4.14.4.1 详细设计的任务和原则
-
1.6.4.24.4.2 详细设计工具
-
1.6.4.34.4.3 数据库设计
-
1.6.4.44.4.4 界面设计
-
1.6.4.54.4.5 详细设计说明书
-
1.6.5习 题 4
-
1.7第5章 软件实现与维护
-
1.7.15.1 软件编码
-
1.7.1.15.1.1 程序设计语言
-
1.7.1.25.1.2 程序设计风格
-
1.7.1.35.1.3 程序复杂性度量
-
1.7.1.45.1.4 编码效率
-
1.7.25.2 软件测试
-
1.7.2.15.2.1 软件测试的基本概念
-
1.7.2.25.2.2 白盒测试
-
1.7.2.35.2.3 黑盒测试
-
1.7.2.45.2.4 软件测试策略
-
1.7.35.3 软件调试
-
1.7.45.4 软件维护
-
1.7.5习 题 5
-
1.8第6章 面向对象方法学
-
1.8.16.1 传统软件开发方法与面向对象方法的比较
-
1.8.26.2 面向对象方法的基本概念
-
1.8.2.16.2.1 对象
-
1.8.2.26.2.2 类
-
1.8.2.36.2.3 继承
-
1.8.2.46.2.4 消息
-
1.8.2.56.2.5 多态性和动态绑定
-
1.8.2.66.2.6 永久对象
-
1.8.36.3 面向对象建模方法
-
1.8.3.16.3.1 建模的目的与重要性
-
1.8.3.26.3.2 Booch方法
-
1.8.3.36.3.3 Coad-Yourdon方法
-
1.8.3.46.3.4 OMT方法
-
1.8.3.56.3.5 OOSE方法
-
1.8.46.4 UML
-
1.8.4.16.4.1 UML的形成历史
-
1.8.4.26.4.2 UML的特点
-
1.8.4.36.4.3 UML的模型元素
-
1.8.4.46.4.4 UML视图
-
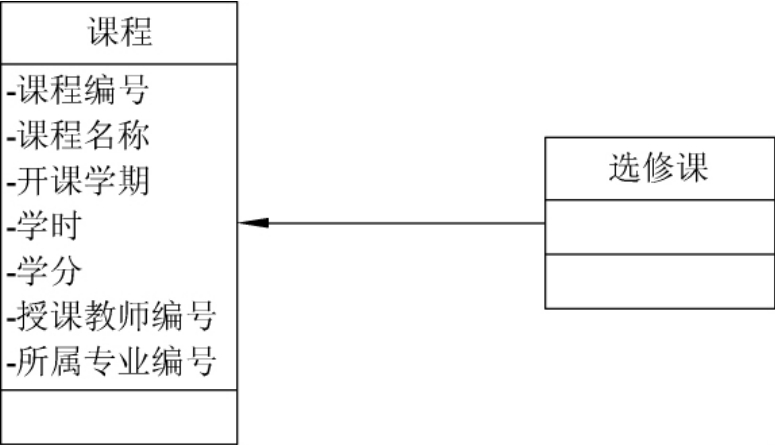
1.8.4.56.4.5 类图
-
1.8.4.66.4.6 用例图
-
1.8.4.76.4.7 顺序图
-
1.8.4.86.4.8 合作图
-
1.8.4.96.4.9 状态图
-
1.8.4.106.4.10 活动图
-
1.8.4.116.4.11 包图
-
1.8.4.126.4.12 构件图
-
1.8.4.136.4.13 部署图
-
1.8.5习 题 6
-
1.9第7章 面向对象开发过程
-
1.9.17.1 面向对象的分析
-
1.9.1.17.1.1 需求陈述
-
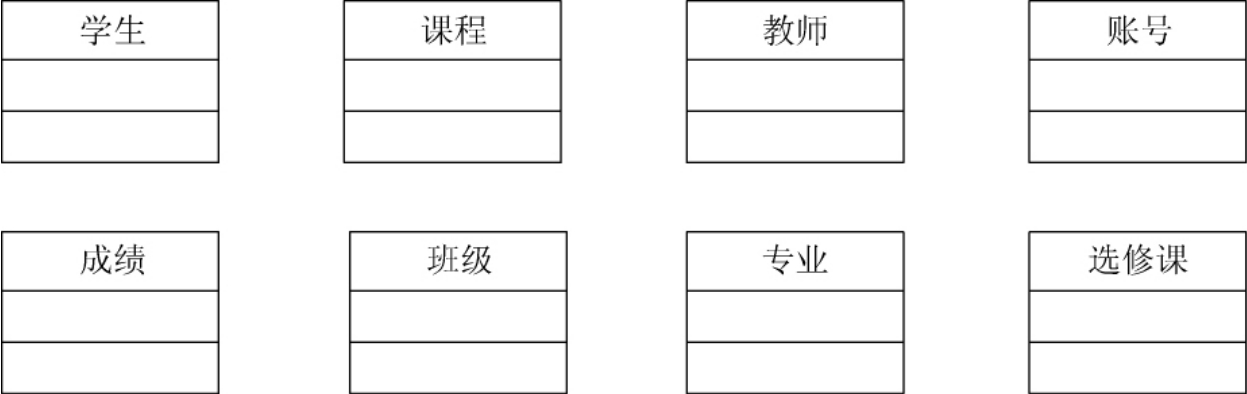
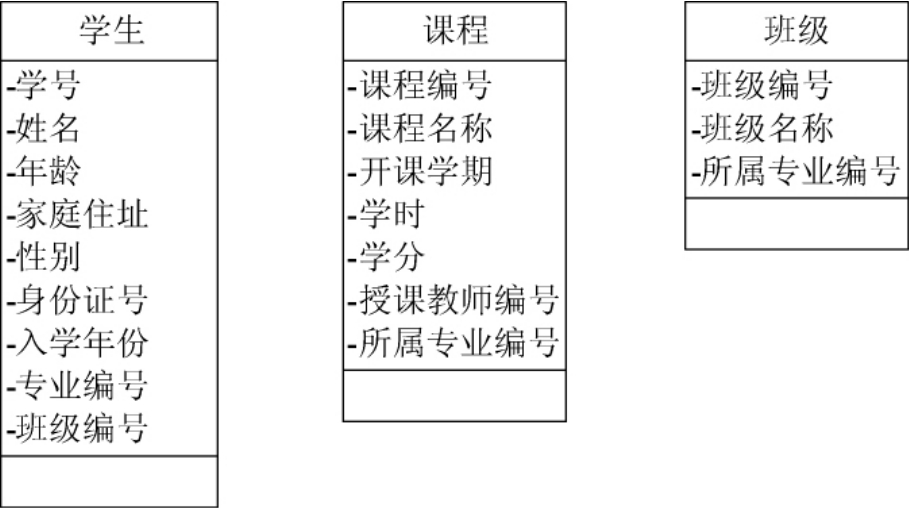
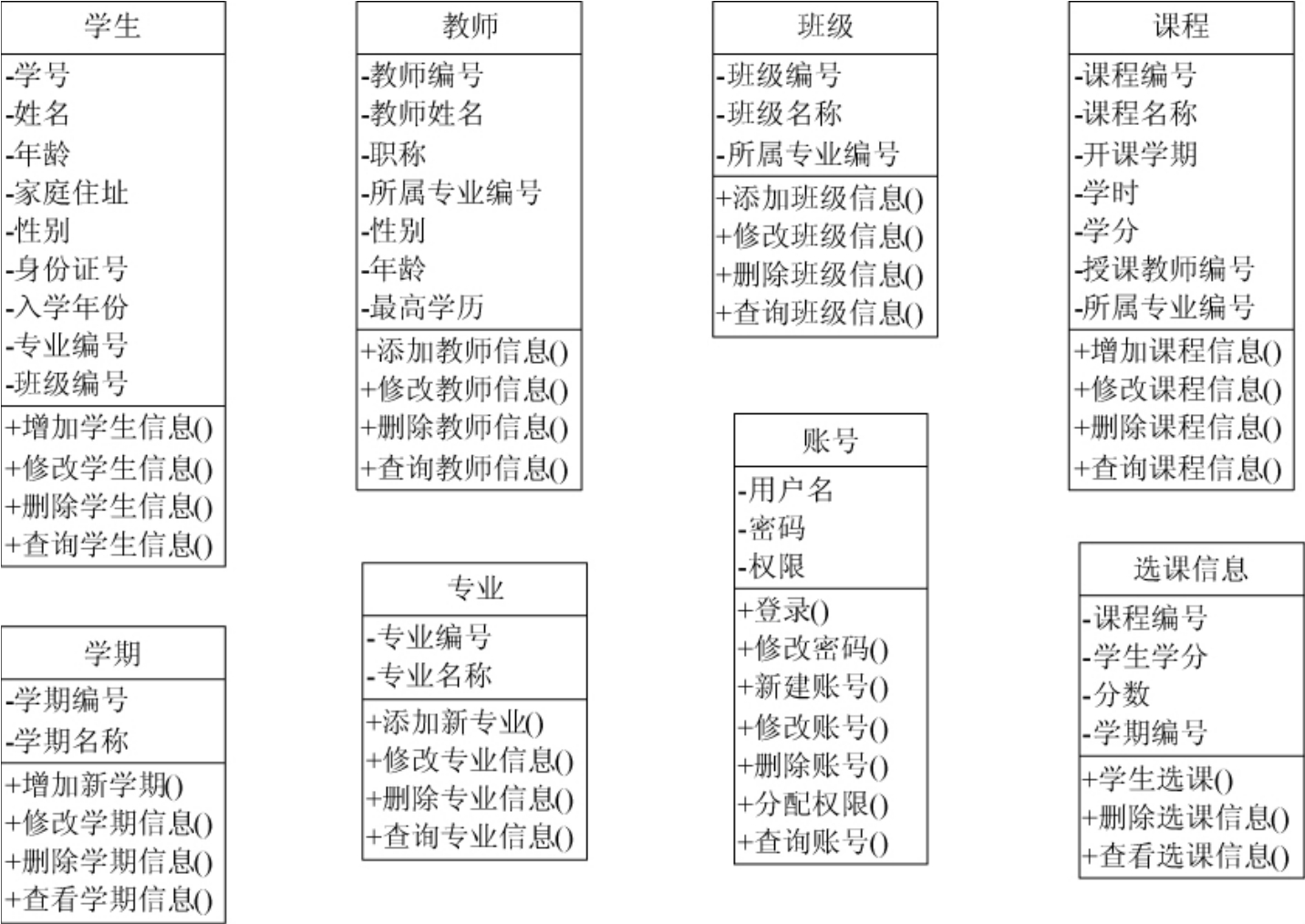
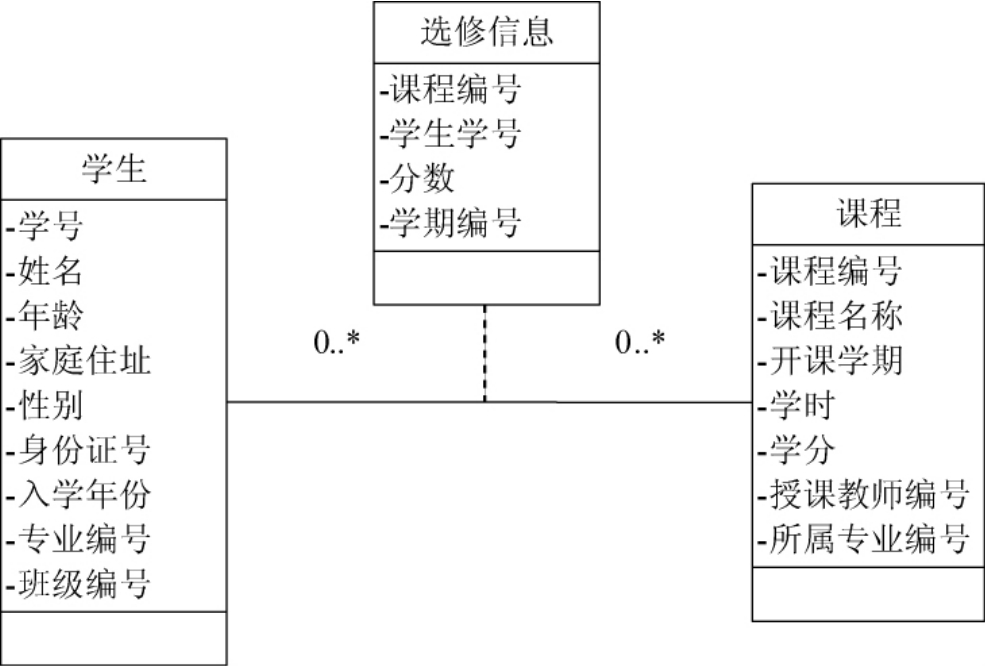
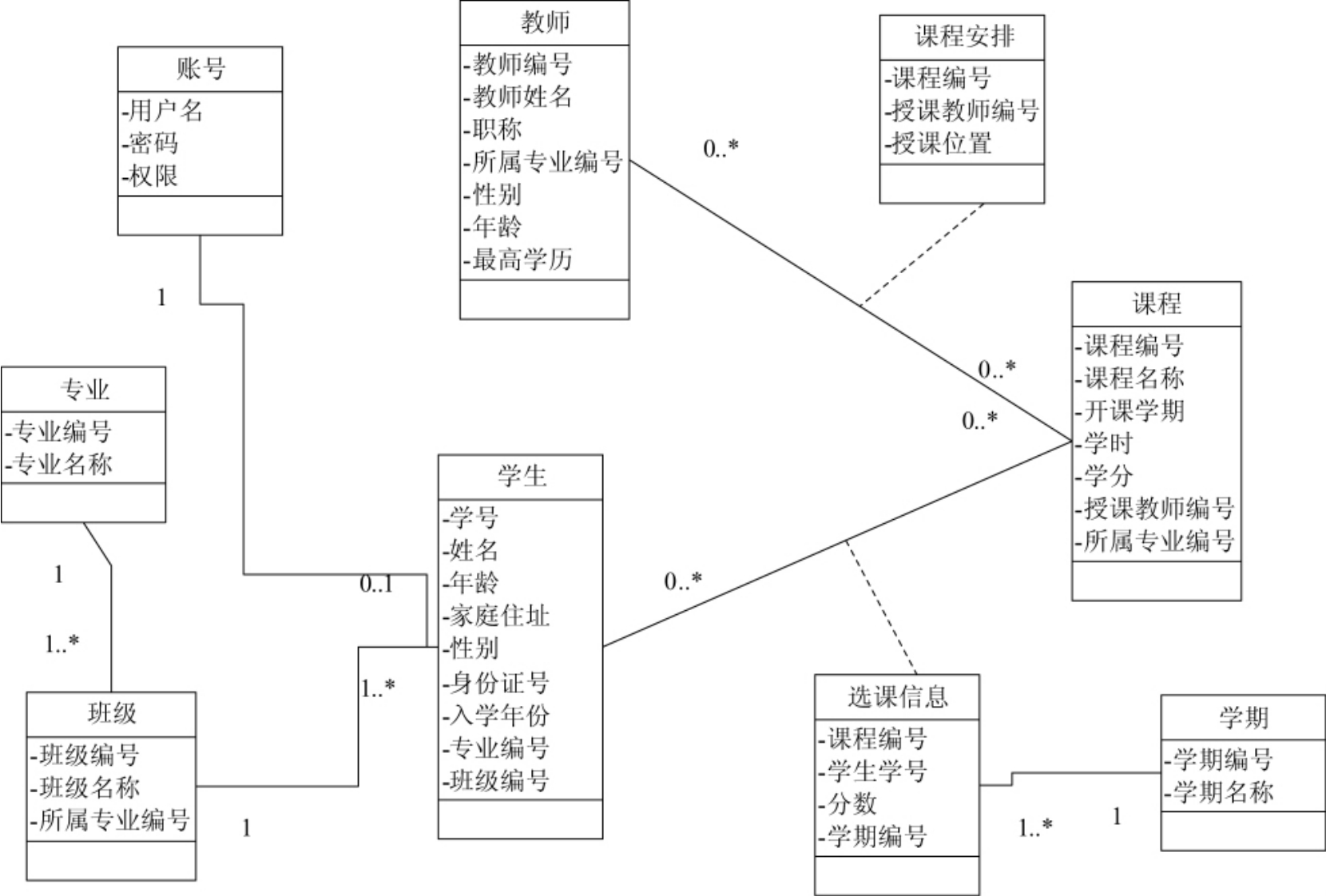
1.9.1.27.1.2 小型的教务管理系统
-
1.9.1.37.1.3 建立对象模型
-
1.9.1.47.1.4 建立动态模型
-
1.9.1.57.1.5 建立功能模型
-
1.9.27.2 面向对象设计
-
1.9.2.17.2.1 面向对象的设计准则
-
1.9.2.27.2.2 系统设计
-
1.9.2.37.2.3 类设计
-
1.9.37.3 面向对象的实现
-
1.9.3.17.3.1 面向对象编程
-
1.9.3.27.3.2 面向对象测试
-
1.9.4习 题 7
-
1.10第8章 软件项目管理
-
1.10.18.1 软件项目管理的范围和过程
-
1.10.28.2 软件项目计划
-
1.10.2.18.2.1 软件度量
-
1.10.2.28.2.2 项目资源估算与成本分析
-
1.10.2.38.2.3 进度安排
-
1.10.38.3 软件项目组织
-
1.10.3.18.3.1 组织原则
-
1.10.3.28.3.2 组织结构模式
-
1.10.3.38.3.3 程序设计小组的组织形式
-
1.10.3.48.3.4 人员配备
-
1.10.48.4 软件项目控制
-
1.10.4.18.4.1 风险管理
-
1.10.4.28.4.2 质量管理
-
1.10.4.38.4.3 配置管理
-
1.10.5习 题 8
-
1.11第9章 软件工程标准化和新趋势
-
1.11.19.1 软件工程标准化
-
1.11.1.19.1.1 软件工程标准化的意义
-
1.11.1.29.1.2 软件工程标准分类
-
1.11.1.39.1.3 软件工程标准的制定与推行
-
1.11.1.49.1.4 我国的软件工程标准化工作
-
1.11.29.2 软件国际标准
-
1.11.2.19.2.1 ISO 9000标准
-
1.11.2.29.2.2 ISO/IEC 12207软件生存周期过程标准
-
1.11.2.39.2.3 ISO/IEC TR15504软件过程评估标准
-
1.11.2.49.2.4 IEEE 1058.1软件项目管理计划标准
-
1.11.2.59.2.5 能力成熟度模型
-
1.11.39.3 软件文档
-
1.11.3.19.3.1 软件文档的作用与分类
-
1.11.3.29.3.2 文档的管理与维护
-
1.11.49.4 软件工程新趋势
-
1.11.4.19.4.1 软件构件
-
1.11.4.29.4.2 可信软件
-
1.11.4.39.4.3 群体软件工程
-
1.11.5习 题 9
-
1.12附录 部分习题参考答案
-
1.13参考文献