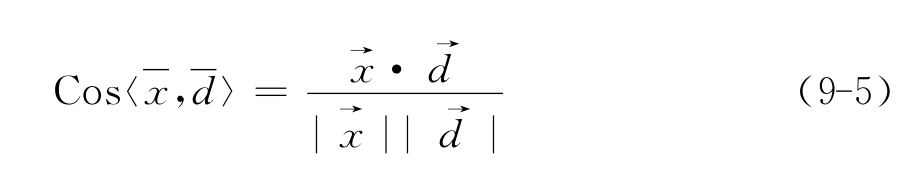文本自动标引与自动分类研究
-
1.1丛书总序
-
1.2序 言
-
1.3第一部分
-
1.3.1第1章 引言
-
1.3.1.11.1 研究背景
-
1.3.1.21.2 自动标引与自动分类的作用
-
1.3.1.2.11.2.1 文本挖掘
-
1.3.1.2.21.2.2 信息检索
-
1.3.1.31.3 本书的内容与章节安排
-
1.3.1.4参考文献
-
1.3.2第2章 文本自动标引与分类研究进展
-
1.3.2.12.1 自动标引研究综述
-
1.3.2.1.12.1.1 概述
-
1.3.2.1.22.1.2 标引对象的界定
-
1.3.2.1.32.1.3 自动标引的五十年研究历程
-
1.3.2.1.42.1.4 自动标引研究路线图与方法分类
-
1.3.2.1.52.1.5 自动标引存在的问题与研究展望
-
1.3.2.22.2 文本分类研究综述
-
1.3.2.2.12.2.1 自动分类方法简介
-
1.3.2.2.22.2.2 国外研究现状
-
1.3.2.2.32.2.3 国内研究现状
-
1.3.2.2.42.2.4 文本分类面临的主要问题
-
1.3.2.32.3 本章小结
-
1.3.2.4参考文献
-
1.4第二部分
-
1.4.1第3章 文本分词技术及抽词词典构造
-
1.4.1.13.1 文本分词技术概述
-
1.4.1.23.2 分词模式设计及其原理
-
1.4.1.33.3 原始抽词词典的构造
-
1.4.1.3.13.3.1 词汇来源
-
1.4.1.3.23.3.2 未登录词补充方法
-
1.4.1.43.4 词典约简算法实验
-
1.4.1.4.13.4.1 算法原理
-
1.4.1.4.23.4.2 算法设计及实验
-
1.4.1.5参考文献
-
1.4.2第4章 基于多特征选择及权值计算
-
1.4.2.14.1 特征选择方法概述
-
1.4.2.1.14.1.1 频度/逆文档频度法
-
1.4.2.1.24.1.2 信息增益
-
1.4.2.1.34.1.3 互信息
-
1.4.2.1.44.1.4 CHI(x<sub>2</sub>)
-
1.4.2.24.2 算法设计原理
-
1.4.2.34.3 结果分析
-
1.4.2.4参考文献
-
1.4.3第5章 自动标引中标引源权重方案确定
-
1.4.3.15.1 标引源权重研究综述
-
1.4.3.25.2 标引源权重方案的确定
-
1.4.3.2.15.2.1 抽样调查方案的设计
-
1.4.3.2.25.2.2 抽样数据的统计分析
-
1.4.3.2.35.2.3 标引源权重方案的确定
-
1.4.3.35.3 本章小结
-
1.4.3.4参考文献
-
1.5第三部分
-
1.5.1第6章 分类知识库的制作
-
1.5.1.16.1 概述
-
1.5.1.26.2 关键词串-分类号关联研究综述
-
1.5.1.2.16.2.1 研究综述
-
1.5.1.2.26.2.2 常规方法存在的问题
-
1.5.1.36.3 关键词串-分类号关联方法
-
1.5.1.3.16.3.1 关联规则挖掘概述
-
1.5.1.3.26.3.2 相关度度量方法介绍
-
1.5.1.46.4 分类知识库的制作
-
1.5.1.4.16.4.1 知识库数据来源
-
1.5.1.4.26.4.2 知识库制作步骤
-
1.5.1.4.36.4.3 知识库规模的确定
-
1.5.1.56.5 分类知识库的性能测评
-
1.5.1.5.16.5.1 数量测评
-
1.5.1.5.26.5.2 质量测评
-
1.5.1.66.6 篇名知识库的制作
-
1.5.1.6.16.6.1 篇名的概念及其特征
-
1.5.1.6.26.6.2 建立篇名库的必要性和可能性
-
1.5.1.6.36.6.3 篇名在表达主题时存在的问题
-
1.5.1.6.46.6.4 篇名的规范
-
1.5.1.6.56.6.5 篇名知识库的制作
-
1.5.1.76.7 本章小结
-
1.5.1.8参考文献
-
1.5.2第7章 基于语义体系的词语相似度计算
-
1.5.2.17.1 概 述
-
1.5.2.27.2 词语相似度研究综述
-
1.5.2.2.17.2.1 基于统计的词语相似度计算方法
-
1.5.2.2.27.2.2 基于本体的词语相似度计算方法
-
1.5.2.2.37.2.3 词语相似度计算的混合方法
-
1.5.2.37.3 基于语义体系的词语相似度算法
-
1.5.2.3.17.3.1 《同义词词林》简介
-
1.5.2.3.27.3.2 语义编码之间的相似度计算
-
1.5.2.3.37.3.3 词汇间的语义相似度计算
-
1.5.2.3.47.3.4 自动分类中语义相似度匹配算法
-
1.5.2.47.4 基于语义相似度的同义词挖掘
-
1.5.2.4.17.4.1 同义词挖掘概述
-
1.5.2.4.27.4.2 同义词挖掘系统设计与实现
-
1.5.2.4.37.4.3 同义词挖掘系统的测评
-
1.5.2.57.5 本章小结
-
1.5.2.6参考文献
-
1.5.3第8章 基于知识库的文本自动分类
-
1.5.3.18.1 文本自动系统总体设计
-
1.5.3.1.18.1.1 系统结构设计
-
1.5.3.1.28.1.2 系统模块简介
-
1.5.3.28.2 文本自动分类系统的测评
-
1.5.3.38.3 《全国报刊索引》自动标引与自动分类系统介绍
-
1.5.3.48.4 本章小结
-
1.5.3.5参考文献
-
1.6第四部分
-
1.6.1第9章 统计与决策规则双重分类算法
-
1.6.1.19.1 分类器概述
-
1.6.1.1.19.1.1 最小距离分类器(Rocchio算法)
-
1.6.1.1.29.1.2 Na6ve Bayes分类器
-
1.6.1.1.39.1.3 K-NN算法
-
1.6.1.1.49.1.4 支持向量机
-
1.6.1.1.59.1.5 基于粗糙集理论的分类算法
-
1.6.1.29.2 双重分类原理
-
1.6.1.39.3 分类规则提取
-
1.6.1.49.4 双重分类过程
-
1.6.1.59.5 实验结果及分析
-
1.6.1.6参考文献
-
1.6.2第10章 层次分类算法实验
-
1.6.2.110.1 层次分类原理
-
1.6.2.210.2 层次分类算法设计
-
1.6.2.310.3 实验结果及分析
-
1.6.2.4参考文献
-
1.6.3第11章 基于统计与规则相结合的文本分类系统的实现
-
1.6.3.111.1 系统实验用语料选择及分析
-
1.6.3.1.111.1.1 实验语料选择
-
1.6.3.1.211.1.2 训练样本数量对自动分类的影响分析
-
1.6.3.1.311.1.3 维数多少对分类效果的影响分析
-
1.6.3.1.411.1.4 训练样本先期分类情况的影响
-
1.6.3.211.2 系统总体框架与模块介绍
-
1.6.3.2.111.2.1 功能模块结构
-
1.6.3.2.211.2.2 系统总体流程
-
1.6.3.2.311.2.3 系统各模块介绍
-
1.6.3.311.3 系统测试分析
-
1.6.3.411.4 本章小结
-
1.6.3.5参考文献
-
1.6.4后 记
 ,系统在训练集中找出k(k的确定可以设置相应阈值)个最相近的文档,使用这k个文档所属类别作为待分类文档的候选类别。该文档与k个近邻之间的相似度可以按类别分别求和,再减去一个预先得到的截尾阈值,即可作为该文档的类别测度。公式示意如下[2]:
,系统在训练集中找出k(k的确定可以设置相应阈值)个最相近的文档,使用这k个文档所属类别作为待分类文档的候选类别。该文档与k个近邻之间的相似度可以按类别分别求和,再减去一个预先得到的截尾阈值,即可作为该文档的类别测度。公式示意如下[2]: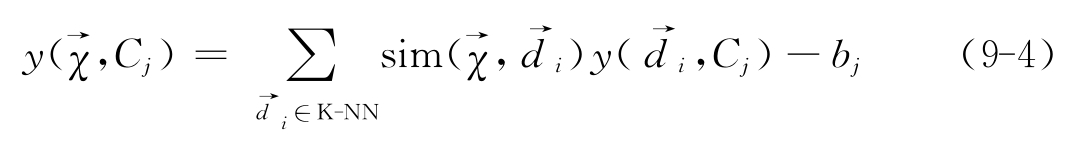
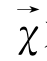 为一篇待分类文本的向量表示;
为一篇待分类文本的向量表示;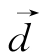 为训练集中的一篇实例文本的向量表示;Cj为一类别;y(
为训练集中的一篇实例文本的向量表示;Cj为一类别;y(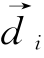 ,Cj)∈{0,1}(当d属于Cj时取1,当
,Cj)∈{0,1}(当d属于Cj时取1,当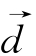 不属于Cj时取0);bj为预先计算得到的Cj的最优截尾阈值;sim(
不属于Cj时取0);bj为预先计算得到的Cj的最优截尾阈值;sim(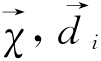 )为待分类文本与文本实例之间的相似度,由公式(9-4)计算得到:
)为待分类文本与文本实例之间的相似度,由公式(9-4)计算得到: