大学计算机基础:文史类
-
1.1内容提要
-
1.2前 言
-
1.3第1章 计算机系统基础
-
1.3.11.1 信息技术概述
-
1.3.21.2 计算机发展及趋势
-
1.3.31.3 计算机系统的组成及工作原理
-
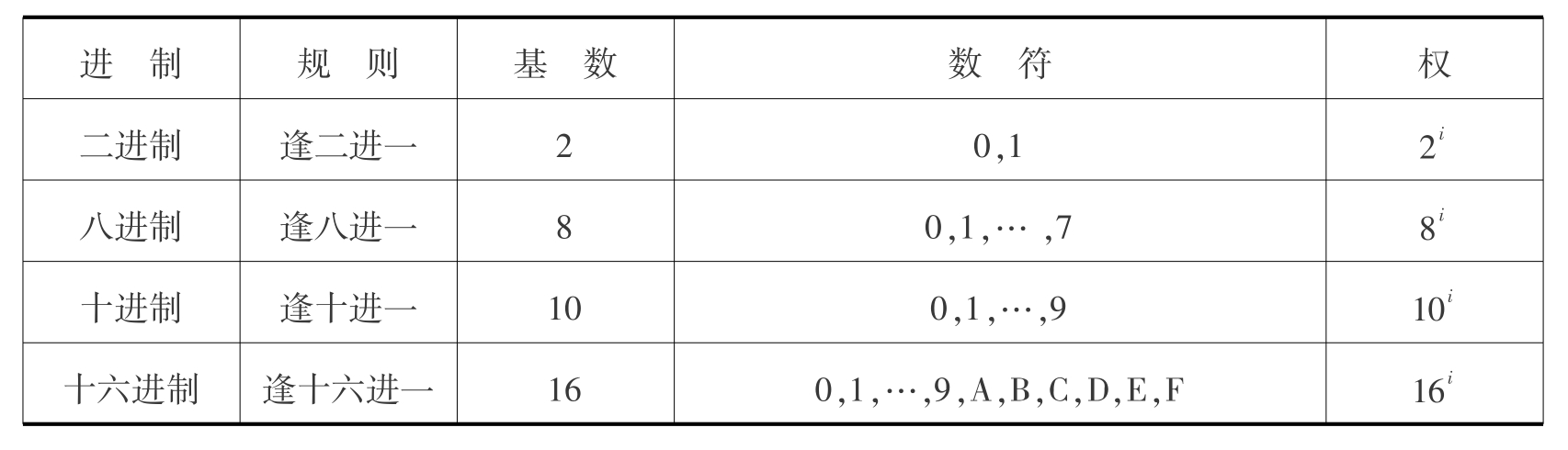
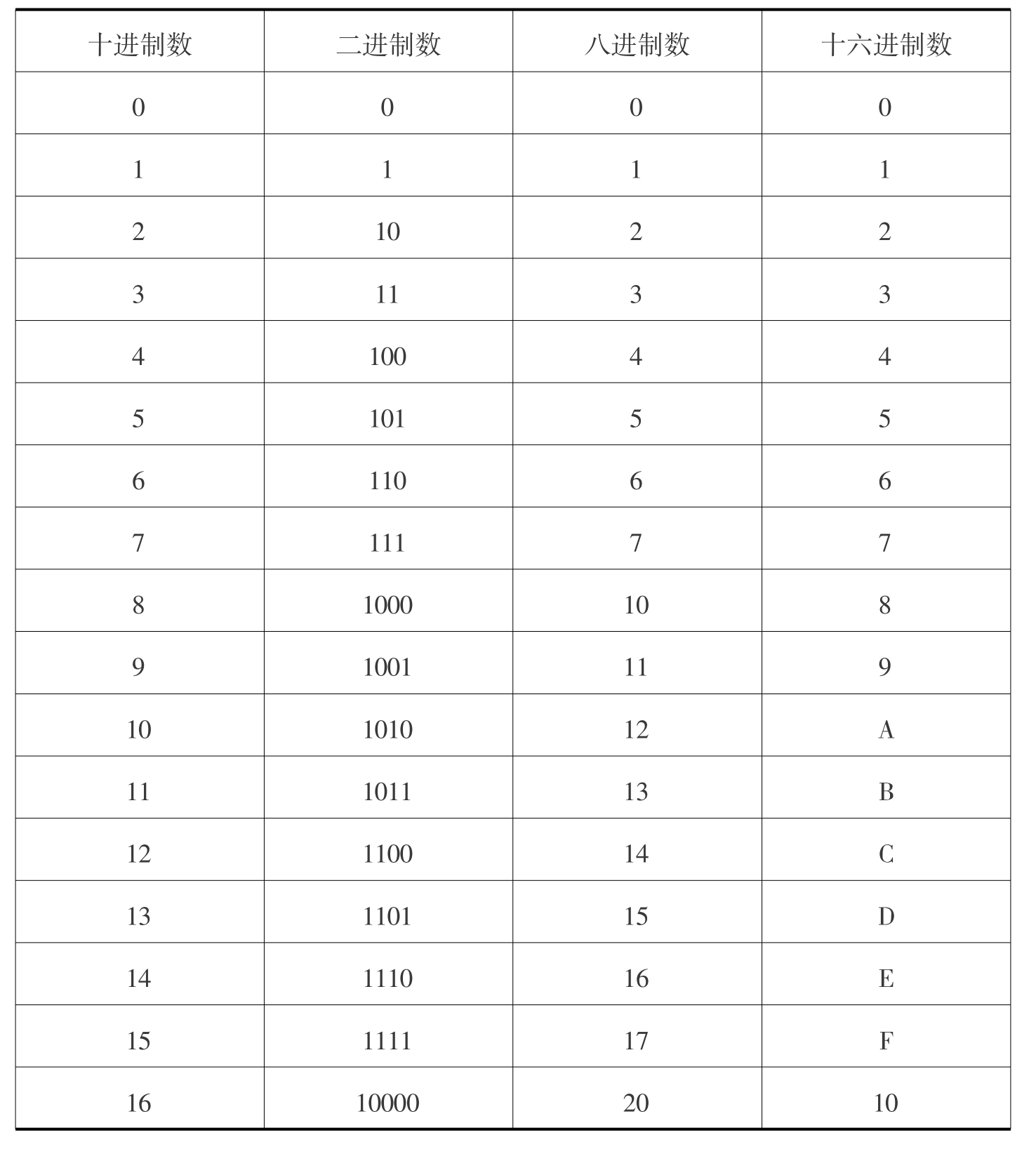
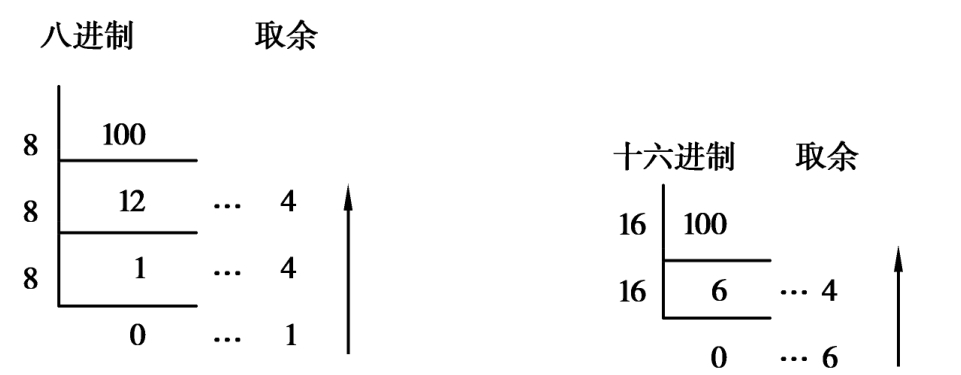
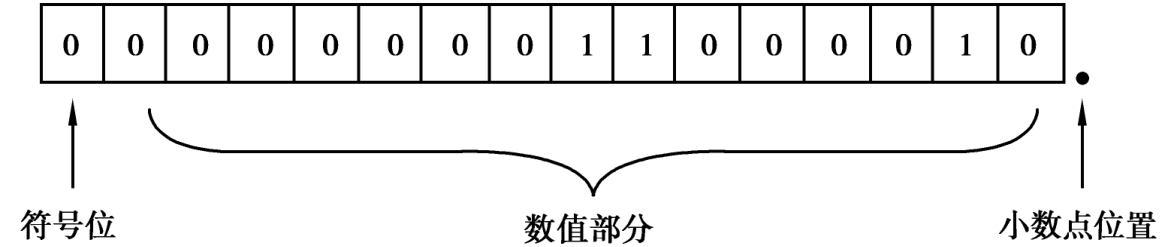
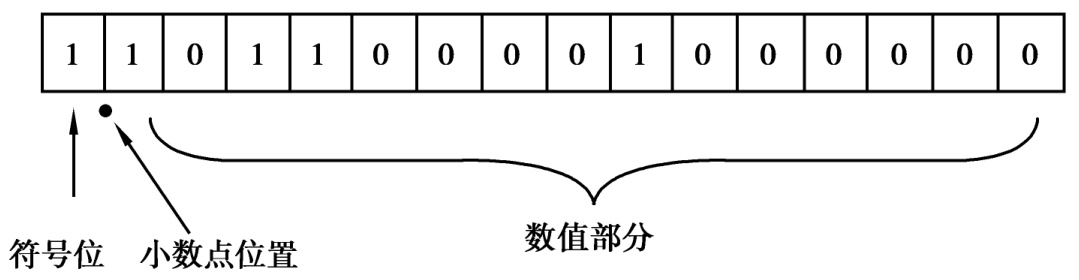
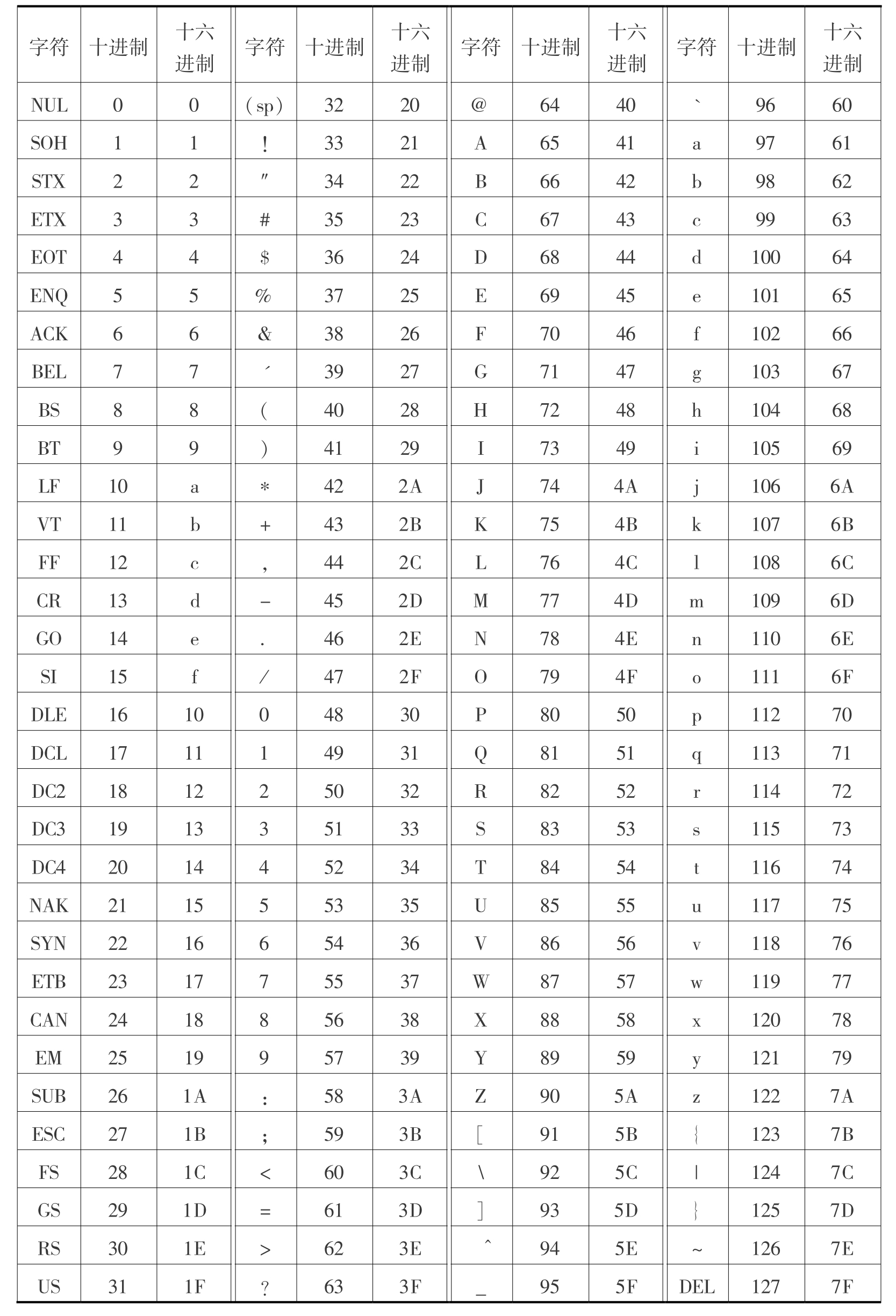
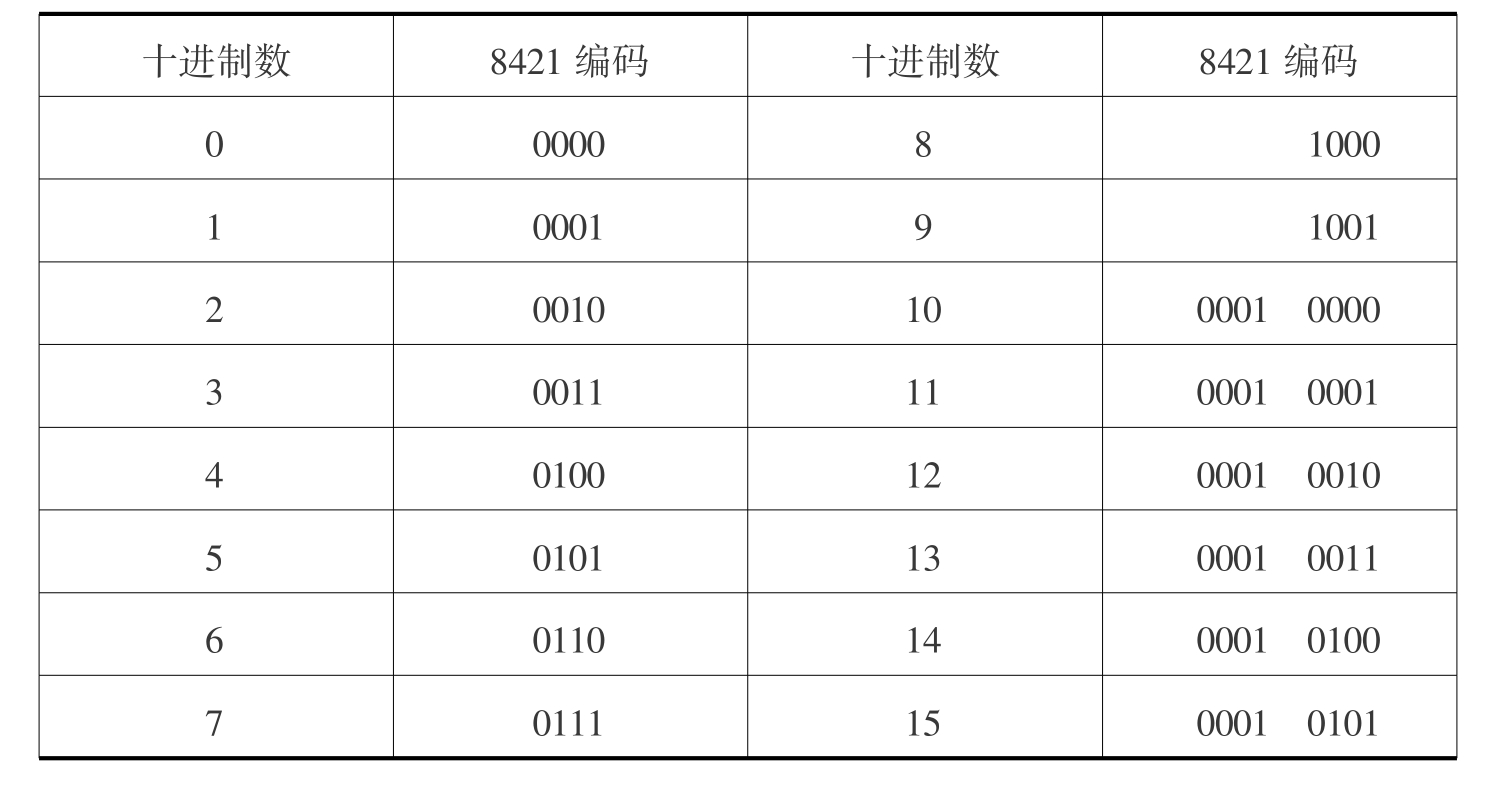
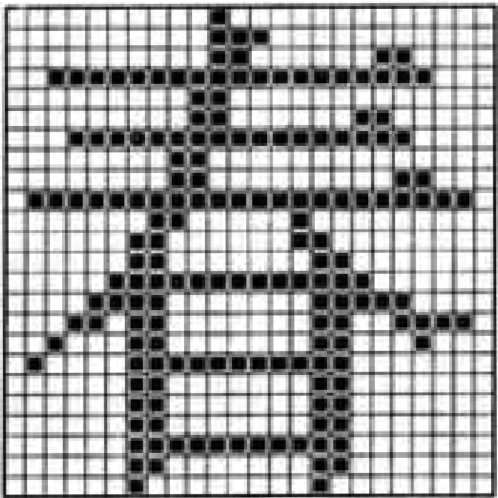
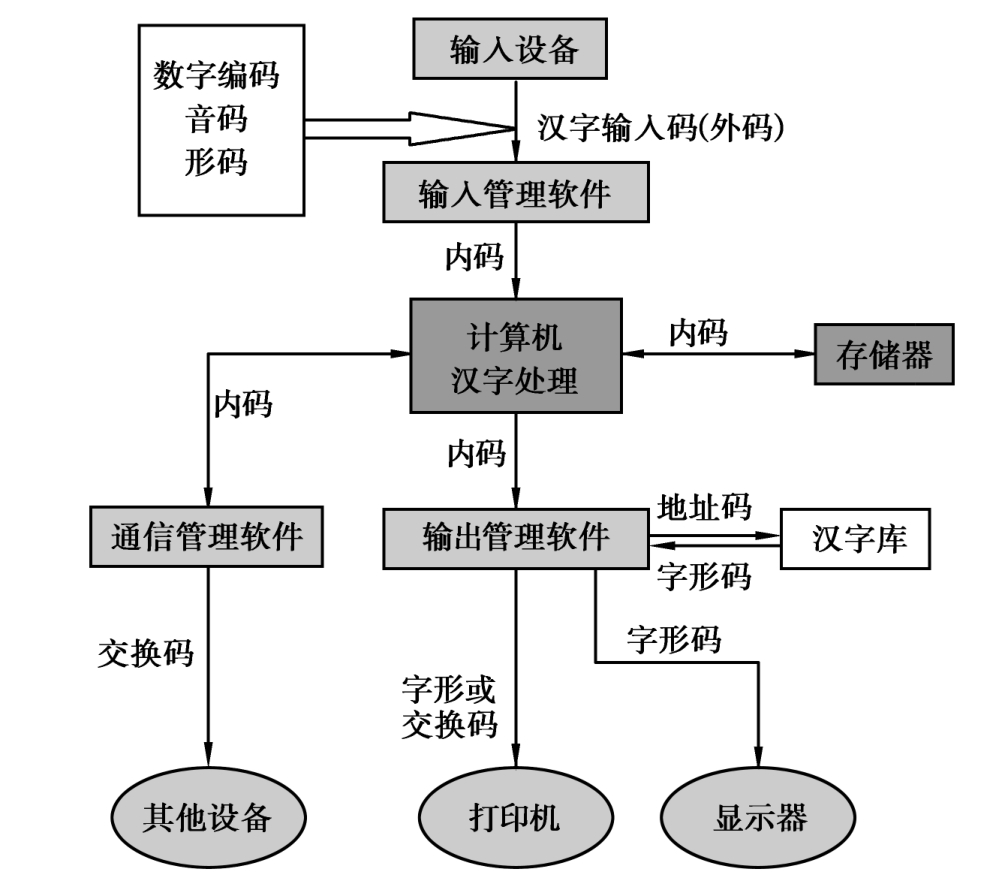
1.3.41.4 计算机中的信息表示
-
1.3.5习 题
-
1.4第2章 中文操作系统
-
1.4.12.1 操作系统概述
-
1.4.22.2 Windows XP操作系统概述
-
1.4.32.3 Windows XP的工作环境
-
1.4.42.4 Windows XP的文件管理
-
1.4.52.5 Windows XP的磁盘管理
-
1.4.62.6 Windows XP的系统设置
-
1.4.72.7 Windows XP的附件
-
1.4.82.8 Windows7操作系统
-
1.4.9习 题
-
1.5第3章 Word 2007 文字处理软件
-
1.5.13.1 文字处理软件介绍
-
1.5.23.2 文档的基本操作
-
1.5.33.3 对 象
-
1.5.43.4 文档排版
-
1.5.53.5 综合案例--课程设计报告排版
-
1.5.6习 题
-
1.6第4章 Excel 2007 电子表格处理软件
-
1.6.14.1 电子表格软件介绍
-
1.6.24.2 Exce l2007的基本操作
-
1.6.34.3 数据的录入与编辑
-
1.6.44.4 格式化工作表
-
1.6.54.5 公式与函数
-
1.6.64.6 统计与分析
-
1.6.74.7 图表功能
-
1.6.84.8 综合案例--学生成绩单的统计与汇总
-
1.6.9习 题
-
1.7第5章 PowerPoint 2007 演示文稿制作
-
1.7.15.1 演示文稿软件介绍
-
1.7.25.2 演示文稿的基本操作
-
1.7.35.3 编辑幻灯片
-
1.7.45.4 幻灯片的外观设置
-
1.7.55.5 幻灯片的动画效果
-
1.7.65.6 演示文稿的放映
-
1.7.75.7 综合实例--社团纳新宣传片的制作
-
1.7.8习 题
-
1.8第6章 计算机网络基础
-
1.8.16.1 计算机网络概述
-
1.8.26.2 计算机网络的体系结构
-
1.8.36.3 计算机网络的物理组成
-
1.8.46.4 Internet技术
-
1.8.56.5 Internet提供的服务
-
1.8.66.6 网站与网页制作
-
1.8.7习 题
-
1.9第7章 多媒体技术基础
-
1.9.17.1 多媒体技术概述
-
1.9.27.2 多媒体信息数字化和压缩技术
-
1.9.37.3 常用的多媒体信息处理工具
-
1.9.4习 题
-
1.10第8章 信息系统安全
-
1.10.18.1 计算机病毒及其防治
-
1.10.28.2 网络安全技术
-
1.10.38.3 Windows安全中心
-
1.10.48.4 使用Windows优化大师
-
1.10.5习 题
-
1.11第9章 专业软件简介
-
1.11.19.1 艺术设计类专业软件简介
-
1.11.29.2 经管类专业软件简介
-
1.11.39.3 建筑类专业软件简介
-
1.12参考文献