第三节 计算机信息检索的原理
1 计算机信息检索基本原理
前面讲过,计算机信息检索是指利用计算机存储和检索信息两个方面。大量的一次文献经过主题分析、标引和著录,按一定格式输入计算机,构成机读数据库记录和文献特征标识,存储在磁带、磁盘或光盘上。信息存储也就是建立数据库的过程,相当于编制手工检索用的文摘索引等检索工具。信息用户检索时,信息提问也要通过主题分析,确定检索词及其他检索项,构成信息提问标识,输入计算机。计算机将信息提问标识与数据库中文献特征标识进行“类比”与“匹配”,两者一致或基本一致时,即命中文献。
计算机信息存储过程是:用手工或者自动方式将大量的原始信息进行加工,具体做法是将收集到的原始文献进行主题概念分析,根据一定的检索语言抽取出主题词、分类号以及文献的其他特征进行标识或者写出文献的内容摘要。然后再把这些经过“前处理”的数据按一定格式输入计算机存储起来,计算机在程序指令的控制下对数据进行处理,形成机读数据库,存储在存储介质(如磁带、磁盘或光盘)上,完成信息的加工存储过程。
计算机信息检索过程是:用户对检索课题加以分析,明确检索范围,弄清主题概念,然后用系统检索语言来表示主题概念,形成检索标识及检索策略,输入到计算机进行检索。计算机按照用户的要求将检索策略转换成一系列提问,在专用程序的控制下进行高速逻辑运算,选出符合要求的信息输出。计算机检索的过程实际上是一个比较、匹配的过程,检索提问只要与数据库中的信息的特征标识及其逻辑组配关系相一致,则属“命中”,即找到了符合要求的信息。
计算机信息检索基本原理如图所示:

2 计算机信息检索系统的组成
计算机信息检索系统主要是由计算机、通信网络、检索终端设备、数据库和辅助设备组成。
2.1 计算机软硬件
计算机是检索系统的核心部分,它包括硬件和软件。计算机硬件是系统采用的各种硬设备的总称,主要包括主机、外围设备以及与数据处理或数据传送有关的其他设备。不同的系统,其组成也不同。计算机软件包括系统软件和应用软件。系统软件其核心是操作系统,应用软件的主题应是数据库管理系统。此外还包括各种必需的程序。检索系统不同,其软件构成也有差异。通过一定的检索软件,它们能够进行信息的存储、处理、检索以及整个系统的运行和管理,相对地说,硬件部分决定了系统的检索速度和存储容量,而软件部分则是充分发挥硬件的功能,运行检索软件,管理检索系统,确定检索方法。
2.2 通信网络
通信网络是联系计算机检索系统和检索终端设备的桥梁,起着远距离、高效率、无差错传递信息的作用。整个通信网络分成资源子网和通信子网两部分。资源子网包含网络中所有的计算机、输入输出设备、各种软件资源和数据资源,负责全网的数据处理业务,向网络信息检索、信息需求、检索主题、检索提问式及提问标识用户提供各种网络资源和网络服务。通信子网是由用作信息交换的结点计算机和通信线路组成的独立数据通信系统,承担全网数据传输、转接、加工和交换等通信处理工作。检索网络所用的通信线路,一般是公用电话线或专用线,国际联机检索系统则是由通信卫星和海底电缆构成的通信网络。
2.3 检索终端设备
检索终端设备是用户与检索系统相互传递信息进行“人——机对话”的装置,有电传终端、数传终端和PC机终端等。现在基本上都是PC机终端,通常由计算机、调制解调器和打印机组成。调制解调器的作用主要是把传输的信息在传输前加载到一个载波信号上(称之为调制),接受时通过检测收到的信息偏离精确载波信号的程度,分离出原先发送的信息(称之为解调),起到数据转换的作用,有内置式和外置式两种。
2.4 数据库
数据库就是在计算机存储设备(磁带、磁盘或光盘)上按一定方式存储的相互关联的信息集合,由一系列记录组成,是检索系统中的信息源,也是用户检索的依据。它是检索系统的信息源,也是用户检索的对象。数据库可以随时按不同的目的提供各种组合信息,以满足检索者的需求。检索系统中的数据库一般由各个数据库生产商提供,也有一些是系统本身建的。
2.5 辅助设备
辅助设备主要是打印机、光盘、磁盘、磁带、调制解调器、网卡、扫描仪、缩微机等。
3 计算机信息检索技术
目前,在实践中经常使用的信息检索技术有:布尔逻辑检索技术、加权检索技术、截词检索技术、限定检索技术、全文检索技术、超文本检索技术以及智能检索技术等。
3.1 布尔逻辑检索技术
布尔逻辑检索技术是利用布尔逻辑算符对多个检索词进行逻辑组配,有利于对复杂课题进行快速检索,是目前运用最广的检索技术,也是构造检索表达式最基本、最简单的匹配模式。
布尔逻辑检索的表达式是目前计算机信息检索系统中使用最多的一种方法,几乎所有的数据库信息检索、联机检索系统、网络检索系统都提供这种检索方式,之所以运用广泛主要有以下特点:⑴与人们思维习惯一致。它可以表达与用户思维相一致的查询要求。咨询要求是用户按照自己的思维习惯提出来的,这些查询要求完全可以表达成布尔逻辑的形式,用户用这种形式提问,可以“翻译”成信息系统可接受的形式。⑵布尔检索表达式表现直观,结构化强,语义表达好。布尔表达式既可以直观而又清晰地表达用户的检索要求,又可以明确地通过对若干信息集合的并、交、补运算,保证用户的提问得以实现。⑶方便扩检和缩检。用户通过给它使用的一个有结构的字典来扩大或缩小检索范围。所谓有结构的字典是指任何一个给定的标引词存储了与之相关的更一般的(上位)或更精确的(下位)关键词的词典。布尔检索很容易利用这些相关项来改进检索,因为布尔检索系统处理是结构化的检索表达式。所以,布尔逻辑可以很方便地通过增加“逻辑与”进行缩检,增加“逻辑或”进行扩检。
虽然布尔逻辑表达检索有很多优点,但还存在着一定的局限性。这种局限性对用户检索结果有一定的影响,需要用户在使用这种检索技术时注意。
⑴它没有反映信息内容所涉及的多个概念的相对重要性。例如,信息用户提问涉及多个概念时,这种技术仅对提问的概念进行检索,忽略了多个概念的重要性顺序或概念之间的关系。这种检索结果,可能是信息集合中某一篇信息重点论述了这种提问的概念主题,也可能是顺带提到的概念主题,会造成检索者的误检结果。
⑵有些检索词表达的概念存在着整体与部分的关系,这种关系处理不好,就不能得到满意的检索结果。例如,检索“肿瘤的治疗”方面的文献,逻辑检索式为:肿瘤*治疗。不难发现使用这种检索式检索,则会造成大量的文献漏检。因为在医学上,肿瘤是一个很大的概念,其下位概念非常多,包括有各科的肿瘤。“治疗”也包括有各种各样的治疗方法。例如,手术治疗、化学治疗、中医治疗等。因此,要查全相关文献,必须进行扩检。对此类问题的处理原则是:如果检索词涉及表达整体的概念,就针对具体情况分别列出每一个表达部分概念的检索词,做相应的扩检。
⑶在检索中,使用“NOT”,能排除含有NOT指定的检索词文献,协助检索出更准确的文献。但是,使用“NOT”必须慎用,因为如果两个关系紧密的检索词同在一个检索逻辑中,对其中一个使用“NOT”逻辑,会导致含有另一个词的文献也被排除。例如,检索式为:(白血病*药物*疗法)“NOT”中医疗法,在这个例子中,检索“白血病药物治疗”方面的文献是检索的主要目的,但由于使用了“NOT”运算符,将同时包含白血病药物治疗和中医治疗的相关文献都排除了,造成漏检。
3.2 加权检索技术
加权检索,与布尔逻辑检索都是信息检索的一个手段,布尔逻辑检索反映了检索词之间的逻辑关系,这种定性检索缺乏“量”的比较,加权检索弥补了这一缺陷。加权检索的侧重点在于判定检索词在满足检索逻辑后对文献命中与否的影响程度,它根据用户的检索需求来确定检索词,再由每个词在检索中的重要程度,分别给予一定的数值(权重)加以区别,同时给出检索命中界线进行限制。界线值也称为阈值,其作用为限制检索结果的输出量。简言之,加权检索技术就是对检索词的组配关系给予定量限制,以判断检索词在满足检索要求后,对所需信息的命中影响程度。进行加权检索时,利用检索词查找数据库,每条命中记录将其包含的检索词根据检索时设定的权值,分别计算命中记录的权值之和,当已检出记录的权值之和达到或超过阈值时,才为“命中”信息,否则为“落选”。加权检索并不是所有系统都能提供的检索技术,而能够提供加权检索的系统,对权的定义、加权的方式、权值计算和检索结果的判定,存在着一定的技术差别。因此,下面分别介绍不同类型的加权检索知识:词加权、词频加权检索等。
(1)词加权检索
词加权检索是最常见的加权检索方法。在检索式的构造过程中,检索者根据对用户检索需求的理解,为需求选定检索词,同时每一个检索词概念给定一个数值权重表示其针对本次检索的重要程度。检索时先判断检索词在文献记录中是否存在,对存在检索词的记录计算其所包含的检索词权值总和,通过与预先给定的阈值比较,权值之和达到或超过阈值的记录视为命中记录,命中结果的输出按权值总和从大到小排列输出。这种用给检索词加权来表示信息需求的方式,称之为词加权提问逻辑。例如,有三个检索词A、B和C,其权值分别为4、3和2,阈值为5,那么A与B、A与C、B与C、A与B与C的组配权值分别是7、6、5、9均大于或等于5,所以,它们都是符号检索要求的组配。
词加权检索具有以下特点:
a.与定性检索一定需要提问式来表达提问要求相比,词加权检索具有:加权使得检索词的重要程度得到体现,因而使检索具有很强的针对性,只要列出检索词,无需列出提问式。
b.加权方法是影响检索结果的核心,对于词加权检索而言,解决的仍不尽如人意。
(2)词频加权检索
词频加权检索是根据检索词在数据库中出现的频次来决定该检索词的权值,而不是由检索者指定检索词的权值,该法消除了人工干预的因素,但这种加权检索方式必须建立在全文或文摘型数据库基础上,否则词频加权将没有意义。词频加权主要是根据词的出现频率来确定词的权值,在检索中采用的通常是绝对词频加权,标引采用的是相对词频加权。
a.绝对词频加权。指检索时累计检索词在记录中出现的次数(权值),检索的记录权值之和由记录包含的所有检索词在记录中出现的次数总和决定,这种方法的缺陷是:长记录与短记录采取了统一的频次标准,导致了短记录不容易被检出来。
b.词频与平均词频相结合确定权值。某检索词在检索集合中的频率与含该检索词的文献数量之比,可得到检索集合中该检索词在每篇文献中的平均出现次数,称为该检索词的平均词频。它可以作为系数来完善绝对词频的计算,即绝对词频与平均词频乘积的总和作为该词的权值。
c.逆文献频率确定权值。仅仅依赖词频或对词频增加一个系数,不能对每一篇文献内部出现的词和只在一些文献中出现的词作出区别。经验表明,一个词表达内容的程度,随着该词在特定文献中出现的频率的增长而提高,随含有该词文献数量的增加而下降,因此,可以将平均词频的总和作为权值。
3.3 截词检索技术
截词检索(Truncation)是一种常用的检索技术,主要是利用检索词的词干或者不完整词形进行检索。特别是在西文检索中,更是广泛使用。它是针对由于近义词、同一词根、单复数等原因造成的检索词列举不全而产生漏检现象而提出来的。西文的构词比较灵活,在词干上加上不同性质的前缀就可以派生出许多新的词汇,而且这些词汇在意义上都比较相近。如单数和复数形式、动词与动名词形式,或者同一词的英美两种不同的拼法等等,这些词如果在检索时不加以考虑就会出现漏检的现象,但是将这些词全部罗列又相当繁琐,而截词检索的功能正是可以检索出所有的词的片段或词干相同的文献,避免了罗列多个词汇的麻烦,也避免了漏检的现象。截词检索分任意截词检索和有限截词检索。
(1)任意截词检索
任意截词检索是指检索词与被检索词实现部分一致的匹配,被截取的部分用*号表示,截词形式有前截断(后方一致),后截断(前方一致)、前后截断(任意一致)三种情况。
例如:“*经济”是前截断,可检索诸如“商业经济”、“知识经济”、“产业经济”等词记录。
“经济*”是后截断,可检索诸如“经济资源”、“经济信息”、“经济科学”、“经济理念”、“经济发展”等词记录。
“*经济*”是任意截断,可检索诸如“经济”、“经济体系”、“发展农业经济体系”等词的记录。
(2)有限截词检索
有限截词检索是指检索词与被检索词只能在指定的位置可以不一致的检索。每个被屏蔽的字符都由一个“?”来替代(汉字由两个“?”来替代),表示在其前面和或后面最多可以有多少字符。
例如:“wom?n”可以检出“woman”、“women”的主题文献;“develop??”可以检出“developed”,但是不能检索出“development”。
总之,对于检索系统而言,截词检索的方法可以减少检索词的输入量,简化检索步骤,扩大检索范围,提高检全率。
3.4 限制检索技术
在检索系统中,为了提高检索的查准率,缩小检索的范围,通常有一些限制的手段和方法。使用这些方法进行检索通常称为限制检索(Limit Search)。常用的限制方法是字段限定。数据库中每条记录都有许多字段,将检索词限定在特定的字段中进行检索就叫做字段限定检索。前面已经提到过数据库的字段,有基本索引字段和辅助索引字段之分。例如:限制检索技术就是对检索词范围(时间、文献类型、期刊名称、文献语种等)进行约束或压缩的方法。其目的是限定检索范围,提高检索专指度和检索速度,它大多通过限制符号或限制命令完成。
3.5 全文检索技术
全文检索在英文称“Full Text Searching”或“ProximitySearching”,对数据库记录的全文本检索,即记录中的每个词都可以作为检索入口,且可以限定词与词之间的语义关系。全文即原文。全文检索就是以原始记录中词与词之间特定位置关系为检索对象的运算。也可以说,是对文献全文内容进行字符串的匹配过程。全文检索技术中的“全文”,表现在它的数据源是全文的,检索对象是全文的,检索技术是全文的,提供的检索结果是全文的。
全文检索的概念主要反映与受控检索相对应的自由词检索方面,与其他检索相比较,有以下特点:(1)直接性。提供存取全文文本的空间,能直接检索原始文献,不必进行二次检索,即全文检索得到的是全文文本,而不是文献线索。(2)详尽性。文献的正文部分或附属部分都可以检索和显示,不失专指性,不产生漏检。用户可以直接查到文献中的每一段、每一句或每个词,还可以看到某些边线性情况。(3)方便灵活性。文本中任何字符或字符串都可以作为检索入口点,用户可直接查询文本中的任何成分或特定单元。(4)广泛适用性。能处理结构化和非结构化等各类文本数据。能够采集各种来源文本,这些来源可能是跨越广泛地理分布的,并且可以是以不同介质、不同格式产生的文本,并整理转换成标准形式,实现全文检索。(5)后处理能力。具有对检索出的文本进行处理的能力,并且以用户乐于接受的形式提供检索并经加工处理的文本,使检索系统功能得到了延伸。(6)用户友好性。易学易用,界面友好。检索方法接近自然语言。(7)易于自动化。分词、标引易在计算机上实现。
全文检索是通过“位置算符”来确定词与词之间的特定位置关系的。检索词在全文检索中的相对位置的限定性检索大致分四种级别的检索。①记录性检索。限定检索词在数据库的同一记录中。②字段级检索。限定检索词在数据库记录的字段范围内。③子字段或自然句级检索。限定检索词在同一子字段或自然句中。④词位置检索,限定检索词的相对位置满足某些条件。不同的检索系统所规定的全文检索位置运算符可能不同。
3.6 超文本检索技术
超文本(Hypertext),是对原有的单向线性工作、单值媒体或单值排列的一种扩充,一种开拓,实质上是对“文本”的一种扩充,它既是一种信息的组织形式,也是一种信息获取技术。人们习惯地将信息分为文本信息Text、图像信息与声音信息等,所谓文本信息包括文字信息与数字信息等;而超文本信息包括了文本信息、图像信息与声音信息等,也即一切可用的现代计算机存储的信息。超文本与普通文本的差别,不仅在于存储信息的形式,而且在理论上,超文本还能存储存在于超文本信息之间的多种自然联系,而普通文本只存储记录之间的并存关系。超文本强调了信息对象之间的关系,方便了人机交互,增加了用户对系统的了解,符合人们联想式的阅读与思维习惯。
作为一种新型的检索技术,超文本技术与受控标引检索相比,具有显著的区别:⑴内容非线性组织和单元关联性。⑵体现了信息的层次关系。⑶动态性、交互界面友好。⑷信息内容表述方式的多样性和直观性不仅有文字,还有图片、照片、地图等各种信息。⑸避免了检索语言的复杂性。这些特点使超文本信息检索与传统信息检索系统相比,具有明显的优越性。首先,它以知识单元为单位,通过链路将同一文献或不同文献的相关部分连接起来,检索时可深入到知识单元,而传统的检索技术以文献为单位,检索结果都是整篇文献;其次,传统的检索系统采用准确匹配的检索方法,检索结果是一组未经排列的文献,无法区分它们的重要性,而在超文本检索系统中,文献是结构化建立的,并非处于同一层次,用户使用超文本检索系统时,可以看到文献间链路以及两个文献间路径和相隔的节点数,并由此确定文献的重要性。同时,还可以根据需要在没有链路的文献之间加上链路;再次,一般检索中,由于不熟悉检索语言和检索策略,给用户造成很大困难。尤其是跨数据库检索时,由于每个数据库具有不同特征和使用不同的检索语言,更增加了检索的难度。而超文本系统可通过链路浏览找到所需信息,避免了检索语言的复杂性。另一方面,超文本系统还可以作为一个独特的用户界面,将不同数据库的检索语言一体化。
3.7 智能化检索技术
信息检索的发展,经历了布尔检索、向量空间检索、模糊集合检索、概率检索、全文检索等,后者比前者在理论上更完善,也更科学合理。发展到超文本检索,不仅检索过程更加灵活、方便、友好,而且检索结果图、文、声并茂,更加生动形象,将信息检索提高到了一个更高的阶段。但是,单纯运用超文本技术,或者简单地将超文本技术与传统的检索方法或系统相结合,都并不能得到令人满意的效果和效率,只有使这些系统向智能化方向发展,即将信息自动化处理技术、超文本技术、传统检索技术和人工智能技术结合起来,才能得到真正方便实用的信息检索系统。
“智能检索”是既查找所需信息又对检索到的信息做适当加工,产生出新信息提供给用户的检索过程。智能检索系统是指具有联想、比较、判断、推理、学习等能力,能模拟人类进行信息检索的计算机检索系统。它不仅能完成简单的匹配检索,而且还能对机内存储的数据进行一定程度的分析、比较、联想、综合、判断或演绎、推理,输出满足查询条件而系统中原本没有,或没有明显表示出来的新信息。属人工智能范畴,是信息检索的发展方向。
“智能检索”可以按以下几个方面理解:⑴某一用户,为了寻求某一问题的求解方法或获取一些有用的信息,来到信息服务中心。⑵用户不知道如何去精确地描述其信息需求,就是说无法精确地说明其信息需求。⑶信息中心的检察咨询人员则可以通过和用户间的交流,从而理解用户的信息需求,通过对一个或多个具有文献描述的数据访问,找出用户所需的文献信息。⑷从智能的角度来看,要完成上述智能检索过程中的第三步,就要求系统必须:①能够考虑个别用户的特性。②能够在问题描述一级解决用户问题不需要用户对其信息需求作进一步的特殊描述。③能够充分考虑某些概念,比如问题求解状态、系统能力、所需响应的时间等。④有一个完整有效的人机接口,以便使系统能够和用户进行一些必要的会话。⑤能够确定存储有关文献的数据库、文献结构、内容及其用户求解问题的有关知识,并能在检索过程中使用这些知识。⑥能够自动确定用户和文献之间的某些关系。⑦不断学习和自我完善的功能。
智能检索系统的核心是必须具有智能化人机接口,从而使用户在求解问题过程中能发挥更恰当的作用。同时必须具备系统推理能力,以此来确定用户及其提问和数据库文档之间的关系,它可以通过启发式的推理处理来完成。现有的检索系统增加智能化的人机接口而形成智能检索系统必须具有:①主动向用户提供检索系统的参数,加数据库分布、更新情况等,帮助用户选择数据库。②具有语法分析功能,使用户能用自然语言进行提问。③帮助用户确定检索策略。④记忆不同用户使用的检索模式及其对数据库的覆盖范围和对所得结果的评价,以便完成自我学习和更新知识。而集中融合传统检索技术和人工智能技术建立的新一代智能型信息检索系统,则完全能以自然语言方式接受检索课题,并向人工那样进行课题分析与设计,全过程自动完成课题的检索。
4 计算机信息检索的方法与步骤
4.1 明确检索要求和检索目标
计算机检索的第一步工作是明确检索要求和检索目标。
明确检索要求就是要搞清楚本课题属于什么学科,所需情报的文献类型及语种,查找文献的年代,所需文献的最佳篇数,允许支配的检索费用。这些要求对选择数据库、构造检索策略都是十分重要的。
确定检索目标也是计算机信息检索前应搞清楚的准备工作。例如,如果课题性质属于解决技术疑难问题,则应尽可能地检索出与之密切相关的那一部分文献,即要求较高的查准率;如果属于开题调研、成果查新性质,则应尽可能地检索出与之相关的全部文献,即要求较高的查全率;如果属于探索性性质,只需要查出一些启发性的文献,对查准率和查全率要求都不高。
4.2 课题概念分析方法
(1)一般的课题概念分析方法
分析课题就是分析出课题所涉及的主要概念,并找出能代表这些概念的若干个词或词组,进而分析概念之间的上、下、左、右关系。对于新学科、交叉学科和边缘学科的课题,更要搞清楚这些概念关系。概念分析的结果应以概念组为单元的词或词组形式列出,以便下一步制订检索策略。例如,“甜瓜的栽培技术(Cultivation Techniques Of Melon)”这一课题,经过分析,涉及的主要概念是“甜瓜(melon)”和“栽培技术(cultivation techniques)”。又如,“禽流感的防治(Prophylaxis And Treatment Of Avian Influenza)”这个课题可划分为主要概念“禽流感(avian influenza)”和辅助概念“防治(prophylaxis and treatment)”。
(2)核心概念的选取
有些检索词中已经含有的某些概念,在概念分析中应予以排除。例如,课题“玻璃纤维增强石膏制品”,从字面上看,这个课题可划为三个概念:即“玻璃纤维”、“增强”、“石膏制品”。但石膏制品中加入玻璃纤维,其目的就是为了增强石膏制品,因此可将“增强”这一概念排除在外。又如,课题“内弹道高温高压高密度的气体状态方程”。如果把“内弹道”、“高温”、“高压”、“高密度”、“气体”、“状态方程”六个概念全部组配起来,会造成大量漏检。实际上,内弹道状态方程必然是高温高压高密度情况,而且,弹道状态方程也必然是针对气体而言的。因此,本课题只需采用“内弹道”和“状态方程”这两个本质概念即可。
如果有些检索概念已经体现在所使用的数据库中,这些概念也应该予以排除。例如,在使用牦牛数据库(Yaks Database)时,“牦牛(Yaks)”这一概念一般可以排除,而computer(计算机)一词在计算机数据库(Computer Database)中一般也应予以排除。
另外有一些比较泛指、检索意义不大的概念,例如,“发展”,“趋势”,“现状”等在不是专门查找综述类文献时也应予以排除。
4.3 检索词的扩展、选择和处理
目前的计算机信息检索系统,还不具备智能思考能力,不会对所输入的检索词以及涉及的所有词进行自动地、全面地检索。因此,必须在概念分析的基础上列出与概念有关的词,从中做出选择,并利用截词等方法对检索词予以归并。
4.3.1 检索词的扩展方法
常用扩展方法有基于同一概念、基于内容分析和基于检索结果三种方法。
一、同一概念的检索词的扩展
许多事物从不同的角度考虑,有着不同的名称,它们都可以作为检索提问。具体的方法有:
(1)寻找同一事物的学名、俗名、商品名和代号等。例如,乙酰水杨酸与阿司匹林、氢氧化铵与氨水、空间通信与宇宙通信、计算机与电脑、乙醇与ethanol以及alcohol、氟利昂22与Freo-22以及chlorodifluoromethane、过氧化氢酶与E.C.1.11.1.6以及catalase等。
(2)寻找同一事物的简称、全称、音译和意译等。例如,world wide web与WWW、电动机与马达、互联网与因特网、逻辑代数与布尔代数、激光器与镭射、电视与TV以及television等。
(3)寻找同一事物名称的反义词。如,光洁度与粗糙度、精度与误差、污水处理与水净化等。
(4)如果是英语,寻找同一事物名词的单复数、不同词性、英美语的不同形式等。例如,computer与computers、design与designed、fibre与fiber、colour和color、draught和draft等。
二、基于内容分析的概念扩展法
(1)上位概念扩展法
上位概念扩展法是分析检索对象的学科归属。例如,西瓜和瓜果园艺、兔和家畜等。
(2)下位概念扩展法
下位概念扩展法又称概念分析的树形展开法。例如,运用下位概念扩展法对课题“发电厂烟气净化”进行扩展,可以得到:


(3)隐含概念扩展法
所谓隐含主题,是文献或课题中未用显而易见的方式表达,因而需要认真进行“由表及里、由此及彼”的深入分析才能找出的主题。
隐含主题的一个重要特征,是它与显见主题有密切的关联性。隐含主题大体有以下几种情况:
a.隐含主题是显见主题的更确切的表述。有些课题的实质性内容往往很难从课题的名称上反映出来,课题所隐含的概念和相关的内容需要从课题所属的专业角度作深入分析,才能提炼出能够确切反映课题内容的检索概念。下面是几个隐含主题分析的示例。
【例1】“大气环境容量的研究”中的“研究”一词,隐含着各种具体的研究方法,例如,可能是蒙特卡洛模型方法或粒子模型方法。
【例2】“垃圾的处理”中的“处理”一词隐含着“回收”、“再生”等具体的处理方法。
【例3】“大型机械电子渗漏仪”,其中“电子”(electronic)一词,在该专业中往往是用“传感器”来表示,即用“sensor”、“transducer”或“load-cell”等来表示。
【例4】“一个取代高残杀菌剂的理想品种”,如果仅从字面上分析,使用“杀菌剂”和“品种”作为课题的主题,是不够确切的。这个课题隐含了“高效低毒杀菌剂”或“高效低毒农药”这两个概念,它们就要比“杀菌剂”和“品种”确切得多。
类似地,诸如“工艺”、“分析”、“应用”,以及诸如“有机物”、“无机物”、“重金属”、“轻金属”、“高分子材料”等外延十分宽的概念,这一类课题一般都应转换成具体的方法或材料、化合物来表示,以提高课题检索结果的专指度。
b.隐含主题与显见主题是不同需要者对同一情报内容的不同观点或不同的用途。例如“F117A潜隐战斗机”的显见主题是“隐身飞机”和“F117A飞机”,隐含主题是“武器研制”。
c.隐含主题是显见主题的上位概念或下位概念。例如,“由于铂的存在而使反应加剧”的显见主题是参与反应的“化学物质名称”、“铂”和“催化活性”。隐含概念是“催化剂”。又如,“兰州市图书馆的书目数据库系统”显见主题是“兰州市图书馆”和“书目数据库”,隐含主题是“公共图书馆”和“图书馆自动化系统”。
d.隐含主题是显见主题的衍生主题。例如,“加压素治疗休克引起的冠心病”,显见主题是“休克”、“药物治疗”、“加压素”、“临床应用”、“冠心病”和“化学诱导”,隐含主题是“加压素”和“副作用”。又如,“碳化电炉钢渣混凝土”的含义是以电炉还原渣为胶结材料,以沙石为骨料,通过二氧化碳气体养护制成的一种新型混凝土,它的生产完全利用废渣、废气、废液,所以其显见主题是“钢渣混凝土”,隐含主题有“钢渣”、“二氧化碳”、“废物综合利用”。
对于多数课题,同时使用显见主题和隐含主题,可以提高检索的查全率。
三、基于检索结果的概念扩展法
对初步检索结果进行分析,往往能够得到与课题相关的新的检索概念,将这些概念经过重新组合,就可以达到扩展检索结果的目的。
【例5】课题:微细孔和微细狭缝的电火花成型加工技术。
检索策略1:(微+细+狭)*(孔+缝)*电火花*成型*加工
经过检索得到密切相关文献3篇,从中得到另外一些相关检索概念,并据此重新拟定检索策略:
检索策略2:(微+细+狭+窄+小+针)*(孔+缝)*(电火花+放电)*(成型+加工+钻)
【例6】课题:X射线法分析脉冲载荷的结构应变响应。
检索策略1:X射线*(结构响应+脉冲载荷+应变)
得到检索结果5篇,对检索结果分析后,从中得到另外一些相关检索概念,并据此重新拟定检索策略:
检索策略2:(X射线+X光+X线)*(结构响应+应变+载荷+应力+变形)
得到检索结果34篇。
4.3.2 检索词的选择、处理方法
4.3.2.1 截词方法
当某些英语检索词词干相同、词义相近,但词尾或词中间有变化时多数英语单复数变化和英美不同拼写形式,可以采用截词符,或称通配符扩展检索词。截词符一般包括“?”、“*”、“$”和“%”等几种。具体采用什么形式,各个系统都有明确的规定。例如:在DIALOG系统中,截词符号有“?”,“??”和“???”等多种。如果键入检索词“fib?”时,系统将检索含有“fiber”,“fibers”,“fibre”,“fibres”,“fiberboard”,和“fiberglass”等词的所有记录。因而,单个“?”置于词干后,表示以单词空格为界的无限截词。如果键入“fib??board”,系统将查找含有“fiberboard”和“fibreboard”的所有记录。因而,多个或单个“?”置于单词中间或者多个“?”置于词干后,表示有限截词。
使用截词方法时需注意四个问题:一是截词符要紧接在词干后面,截词符和词干之间不能有空格。二是避免将检索词的词干截得过短,一般应在三个字母以上。截词过短,不仅结果不相关的比例大,而且系统开销也大。三是截词应该使用得合理。一般不可能出现词尾变化的单词,例如,management,protection等,其后不必再使用截词。四是从希望出现的单词中取尽可能多的公共字母作为词干,以提高查准率,比如在对manage、managing、managed、management和manager作截词运算时,词干应使用“manag*”,而不应使用“man*”。
4.3.2.2 检索组面的构成
运用上述方法得到的词,首先应加以选择,即注意选用本专业的通用术语(应避免使用冷僻词和根据中文术语白译生造的词),然后以概念为单位,构成组面facets。
例如,课题“农产品”的概念组面和检索词为:
概念组面1:“农产品”farmproduce,primaryproducts,produce
概念组面2:“推广”generalize,spread,popularize
课题“集成电路的应用”的概念组面和检索词为:
概念组面1:“集成电路”integrated circuit
概念组面2:“应用”application
当检索概念组面超过三个时,不同的组合将产生不同的检索策略。例如,有三个组面〔A,B,C〕的课题,这三个组面的组合可有以下类型:
(1)A,B,C
(2)AB,AC,BC,BA,CA,CB
(3)ABC,ACB,BAC,BCA,CAB,CBA
例如,课题“农产品质量安全”的组面构成有以下三种组合形式:
概念组面组合1:农产品*质量*安全
概念组面组合2:农产品质量*安全,农产品安全*质量,质量安全*农产品
概念组面组合3:农产品质量安全,农产品安全质量,质量安全农产品
4.4 检索策略构成和调整方法
在实际检索过程中,仅需一个检索词就能满足检索要求的情况并不很多。通常我们使用多个检索词构成检索策略,以满足由多个概念组配而成的较为复杂课题的要求。
何谓检索策略?目前国内外专家还没有取得一致意见,有各种各样的说法。归纳起来,主要有3种:①所谓检索策略,就是在分析情报提问实质的基础上,确定检索途径与检索用词,并明确各词之间的逻辑关系,对查找步骤做出科学安排;②检索策略是为实现检索目标而制定的全盘计划或方案,是对整个检索过程的谋划和指导;③检索策略是反映用户检索意图的方针和计划,也是用户检索目标的体现。尽管检索策略没有一个公认的定义,但上述三种表达方式已经概括了检索策略的本质和内容,即检索策略是为实现检索目标而制定的检索方案。正确的检索策略既能优化检索过程,提高查全率和查准率,又可减少检索时间和节约检索费用,取得最佳的检索效果。检索策略构成就是运用计算机信息检索系统可以接受的方法,包括布尔逻辑运算符、截词符等方法,表达课题检索要求的过程。
4.4.1 组织检索策略的步骤
(1)明确课题需求、选择数据库
(2)主题概念分析
(3)编制检索式
(4)检索效果评价和调整检索策略
4.4.2 分析课题需求,选择数据库
(1)开始某一项科学研究需要对课题进行全面的文献普查,选择年限较长、收录较广的相关专业的二次文献数据库,在全面回溯检索的基础上,选出相关的文献,再获取一次文献。
(2)为解决某个技术难题,查找关键性的技术资料,对这样的课题,可选择工程和技术类数据库或专利数据库。
(3)为贸易与技术引进、合资谈判,了解国外市场、产品与公司的行情。查找科学数据库以了解技术的先进性,查找市场、产品、公司等商情数据库及对手的情况。
(4)为申报专利或鉴定成果,查找参考依据,以选择国内外专利数据库为主。
(5)为撰写论文查找相关文献等,以期刊论文、学位论文等学术研究性的数据库为主。
(6)明确课题所涉及的学科范围和专业面,根据数据库的主题收录范围进行选择。
(7)对文献的新颖性程度有要求,选择数据更新周期短、速度快的数据库。
(8)用户对检索的查全与查准要求不同,为满足查全要求,就要普查多种数据库;为快速满足查准要求,应选择主题范围最专指的数据库。
因此,选择数据库时,我们一般遵循以下几条原则:
(1)按照课题的检索要求和目的,选择收录文献种类、专业覆盖面、年代跨度对口的数据库;
(2)当需要查找最新文献信息时,选择数据更新周期快的数据库;
(3)当还需要获取原文时,选取原文获取较容易的数据库。
4.4.3 布尔逻辑运算符
所谓布尔逻辑检索,指采用布尔逻辑表达式来表达用户的检索要求,并通过一定的算法和实现手段进行检索的过程。布尔逻辑表达式是采用布尔运算符(逻辑与“and”、逻辑或“or”、逻辑非“not”等)来连接运算分量检索词,以及表示运算优先级的括号组成的一种表达检索要求的一种算式,简称提问逻辑式。布尔逻辑式的原理与检索方法取自于布尔代数与集合运算。根据系统的服务方式和检索要求,其实现算法也不同。
常用的布尔逻辑运算符有三种,它们是逻辑或“or”、逻辑与“and”、逻辑非“not”。
一、逻辑或“or”
布尔逻辑或运算符“or”在布尔检索表达式中通常用“+”来表示。例如,检索词A和B的“or”关系(Aor B)在提问逻辑式中通常表示为A+B。A+B在检索中的含义为,查找信息源中凡含有检索词A或B的所有信息均为命中对象。这种或关系可用文氏图表示。阴影部分为命中部分。or运算符的基本作用是扩大检索范围,增加命中文献量,提高检索结果的查全率,or运算符还有一个去重的功能。即,将A、B中均含有的信息源只命中一次,达到去重的效果。
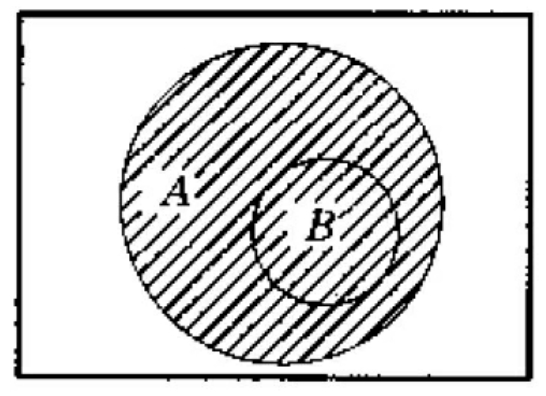
A包含B的或关系
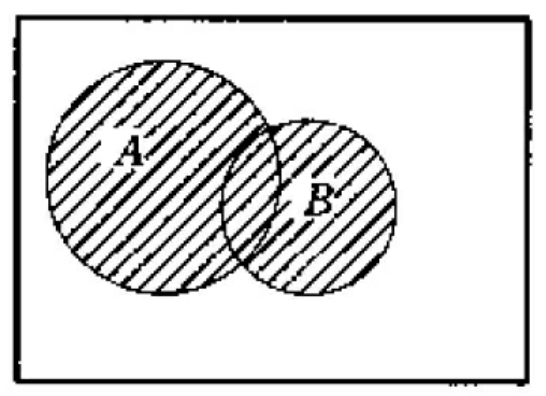
A和B相交的或关系
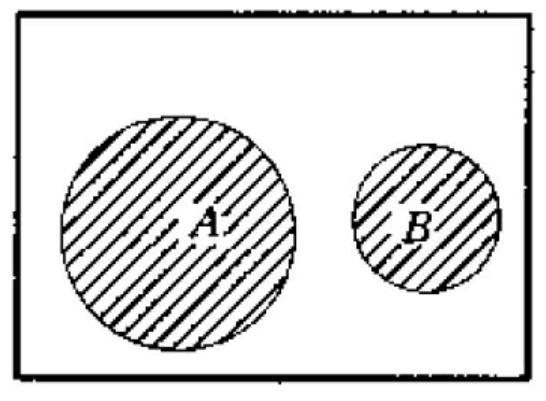
A与B相离的或关系
例如:我们在中国学术期刊(CNKI)的中文期刊全文数据库中,利用专业检索书写检索式“篇名=图书馆or篇名=数字化”,可以检索到82949篇有关“图书馆”或“数字化”方面的文献。如果我们输入检索式“篇名=图书馆”可以检索到74082篇文献;而我们利用检索式“篇名=数字化”检索到10060篇文献;那么(74082+10060-82949=1193篇)文献到底到哪里去了呢?经过进一步检索得知,其中篇名中既包含“图书馆”又包含“数字化”的文献在检索式“篇名=图书馆or篇名=数字化”的检索查找中有效地去重去掉了,而这1193篇文献正是篇名中既包含“图书馆”又包含“数字化”的文献,它既在检索式“篇名=图书馆”中包括,又在检索式“篇名=数字化”中包括,而在检索式“篇名=图书馆or篇名=数字化”中只出现了一次。
那么篇名中既包含“图书馆”又包含“数字化”的检索式怎样书写呢?请看下面介绍的“与”逻辑运算。
二、逻辑与“and”
逻辑与运算符“and”在布尔检索表达式中一般写为“*”。例如,检索词A、B的与运算关系(A and B)的逻辑表达式可以表达为A*B。A*B在检索中的含义为,只有同时含有A、B两个检索词的信息才为命中信息。这种关系的文氏图表示如下图所示,阴影部分为命中对象。
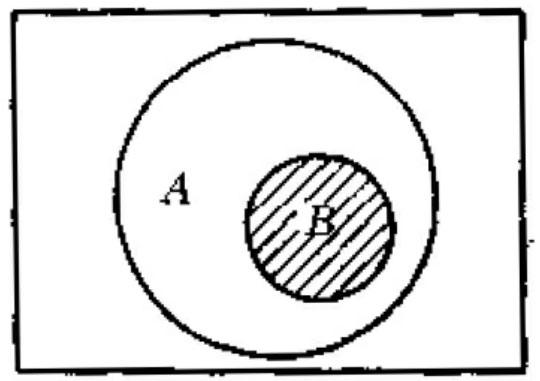
A包含B的与关系
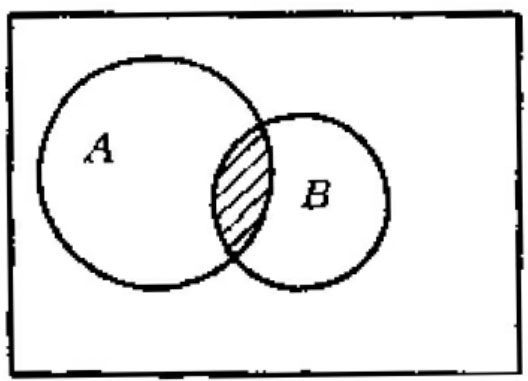
A和B相交的与关系
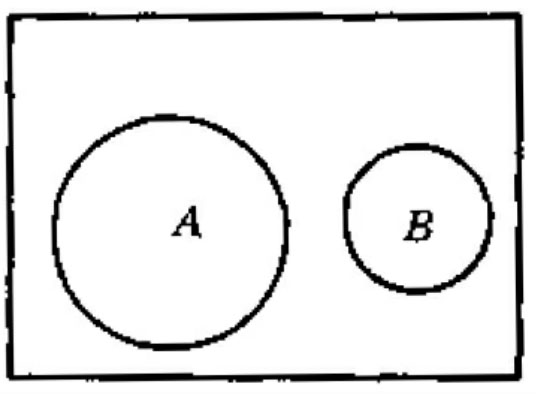
A和B相离的与关系
结合1中提出的在CNKI的中文期刊全文数据库中检索篇名既包含“图书馆”又包含“数字化”的文献,我们可以这样书写检索式:“篇名=图书馆and篇名=数字化”,通过检索,我们可以得到1193篇命中的文献。
又例如,我们需要查找篇名为“农作物转基因”方面的文章,检索式:篇名=农作物and篇名=转基因;我们可以检索到38篇文献;而我们利用“篇名=农作物转基因”的检索式查找到的文献只有29篇,这比用检索式“篇名=农作物and篇名=转基因”检索到的文章少了9篇。大家想一想这是为什么?这是因为用上述的检索式查找到的文献中包含有诸如“农作物转基因途径和产业化发展策略”方面的文章,当然就比直接用检索式“篇名=农作物转基因”查找到的文章数量多。
从上面可以看出,通过对检索词之间的逻辑与运算,增强了查找的专指性,缩小了查找的范围,提高了所需文献的查准率。
下面,如果我们要查找篇名有关“农作物”中不含“转基因”方面的文章,又该如何书写检索式进行查找呢?这就需要用到下面的“非”逻辑运算。
三、逻辑非“not”
逻辑非算符“not”在检索提问表达式中通常写为“—”。“not”除了作为两个运算量之间关系运算符外,还可以作为单运算符只对一个检索项起作用。例如,Anot B可表示为A—B和—B*A。A—B的文氏图表达见下图。
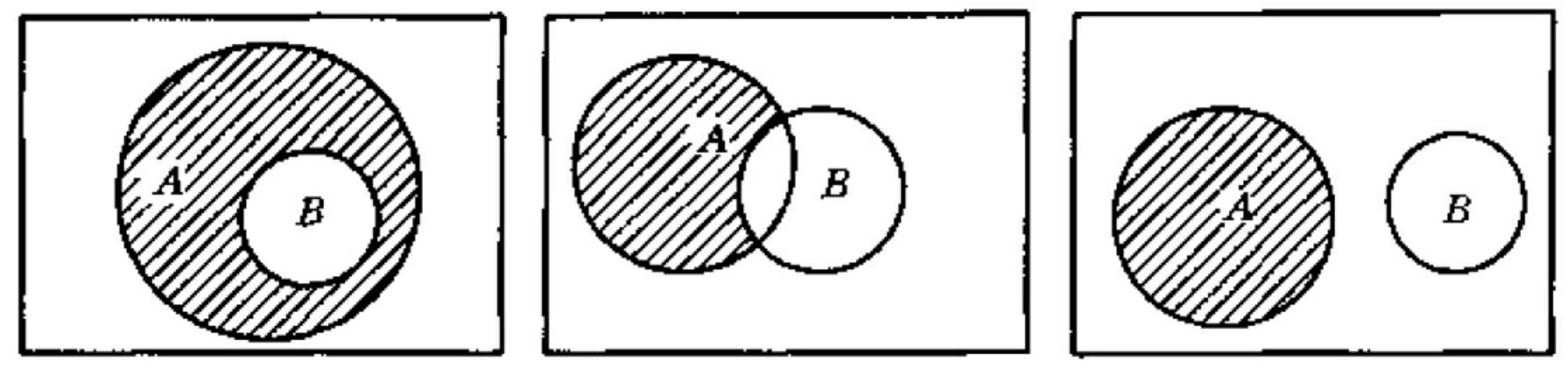
由图可以看出,逻辑非运算是一种排除性运算,—B就是排除了检索项B以外的其他所有项。所以在使用中要谨慎,否则会造成滥检。例如,在中国学术期刊全文数据库中检索除了农业这一主题以外的所有文献。此时,你检索得到的文献数量将会有上万篇。因此,逻辑非运算必须与逻辑与运算同时使用,若逻辑非运算符前有运算量(检索词),则此时的“非”运算默认为“与非”运算。因此,在实际检索中,常常在一个检索中间结果中使用“非”运算,用来排除指定的其中某类文献,以达到提高检索的查准率。
例如,我们要查找有关篇名为“转基因”方面的文章,而且要检索到不是农作物转基因为主题的文献资料。检索式:篇名=转基因not篇名=农作物转基因;我们可以检索到6119篇文献。又比如,我们要检索主题为“计算机网络病毒”的文章,检索式:主题=计算机网络病毒not主题=计算机病毒;我们可以查找到30篇相关主题的文献,如果我们只用检索式“主题=计算机网络病毒”进行检索,则会检索到84篇文献,因此,使用逻辑非运算可以去除一些相似文献,从而减少查找结果的盲目性,查找到的文献更符合检索要求。
4.4.4 位置算符
位置算符用来规定概念相互间的临近关系,包括在记录中出现的顺序和相对位置。位置算符都用“()”括起,常用的有:
一、相邻位置算符
(1)(W)——“WITH”
(W)表示A、B两个概念必须相邻,且词序不变,可表示为A(W)B。
例:Document(W)Indexing——Document Indexing
(2)(nW)——“nWORDS”
(nW)表示A、B两个概念之间最多可插入n个单词,词序不变,可表示为A(W)B。
例:Information(1W)Technology——Information ofTechnology
Application(2W)Computer——Application Technique ofComputer
(3)(N)——“Near”
(N)表示A、B两个概念之间最多可插入n个单词,而且词序可变,可表示为A(nN)B。
例:Agriculture(N)Develop——Agriculture Develop或者Develop Agriculture
(4)(nN)——“nNear”
(nN)表示A、B两个概念必须相邻,且词序可变,可表示为A(N)B。
例:Agriculture(nN)recovery——recoveryofthe Agriculture
二、句子算符(S)——“Subfield”
(S)表示A、B两个概念必须出现在同一句子或同一字段内,而且词序可变,可表示为A(nN)B。
例:Computer(S)Science——The computer science is developing
二、字段位置算符(F)——“Field”
(F)表示A、B两个概念必须出现在同一字段内,如篇名字段、文摘字段、叙词字段、自由词字段等,但词序不限,夹在两词中间的词的个数也不限,可表示为A(F)B。
4.5 计算机信息检索的过程
计算机信息检索的过程就是用户利用数据库获取所需信息的过程。用户将情报提问转换成计算机检索系统能够识别的检索式,即规范化。但也有例外,如:统一语言系统、自然语言检索和全文检索已无需规范化,由计算机进行匹配运算,最后输出检索结果。由于计算机进行的匹配运算是字符匹配运算,用户必须对信息的存储有所了解,特别是检索标识,才能提高检索效率,发挥计算机信息检索的优势。为了保障用户的检索需求,使计算机检索人员提高检索效率,以便能准确地检索出符合用户需求的文献,达到全、新、准的效果,计算机信息检索分为四个主要步骤。
4.5.1 选择数据库
根据用户的信息要求和检索课题的具体内容来选择数据库。对普查型的课题选择的数据库尽量要全;对攻关型的课题选择的数据库尽量要专;而对探索型的课题尽可能要新。
4.5.2 确定检索词
可反映主题内容的检索词(单元词或多元词,规范词或自由词),即确定、说明各种概念意义的检索单元,这直接关系到检索语句的切题与匹配,是检索策略制定中的关键一环。这里所说切题,是指采用国际上通用的各学科术语;合理应用标引多元词和表达较深内涵的下位词;对检索词进行字段限定、词序和相对位置限定、范围限定、加权限定、组面限定;要注意不同数据库中近义词的区别;用专指性高的检索代码等办法来提高检索词的切题性。所谓匹配是指计算机只识别与数据库索引文献中的索引单元完全或部分一致的检索词,所以检索词在切题的基础上还必须要求进行匹配。一般采用规范词匹配,如美国国防文献中心叙词表《DDC Retrieval and Index Terminology》,联机匹配用上机查询数据库中有关的索引单元及其在数据库中出现的频率,以选出合适的检索词。
在检索过程中一定要重视制定检索策略和分析检索策略。
制定检索策略。它包括怎样选择合适的数据库、选择与确定每个检索项、如何组配好符合自己题意的检索逻辑表达式等方面的问题。要根据科技人员的需要制定检索策略。因此检索人员一定要对检索课题的检索需要了解得比较清楚。最好的方法是检索人员与专业人员(用户)结合起来,共同讨论分析检索课题的实质、关键所在,选出合适的检索项,列出恰如其分、符合题意的检索表达式。
分析检索策略(分析主题)。它是信息检索工作中的灵魂,分析主题准确与否就完全决定了你能否真正做到既不漏检又不面宽地检索到你需要的资料。它有两条原则:
(1)分析主题获得的是反映文献(或提问)主要内容的概念的组面,不是文献篇名字面的罗列和堆砌。也就是说在选择主题词和组配检索逻辑式时,不要犯字面上组配的错误,要用概念组配。
(2)选择主题词时,有专指性主题说明的概念,就要用它来标引或查找,不能用上位词(广义词)来组配,同样也不能用下位词(狭义词)来替代。
4.5.3 编写检索式
检索式又称检索提问式,是将检索词经过组配形成的检索语句。通常使用逻辑算符和截词算符在分析检索提问的基础上,确定检索的数据库、检索的用词,并明确检索词之间的逻辑关系和查找步骤的科学安排。
选择合适的检索用词:对于分析出来的每个概念组面,用具体的检索用词来表示,如“学校活动”这个概念可以用具体的“班级活动”、“课外活动”、“学生活动”等检索词来表示。选择合适的位置算符:对于每一个概念组面选择出来的检索词,为表达位置关系,可根据各系统的规定,使用位置算符,如,Wn、W/n等。同时还要注意:概念组配的逻辑关系不要搞错,正确使用布尔逻辑AND、OR、NOT算符;英文检索词的不同表达方式尽量使用截词技术;正确使用各种位置算符;后缀与前缀代码的限定使用;逻辑算符与位置算符的先后处理次序;括号的使用。
4.5.4 用户提问式同文献数据库相匹配
经计算机进行处理、变换、比较与逻辑运算,找出切合用户需求的文献记录。
4.5.5 打印输出
将检索到的文献记录,根据用户的要求由计算机进行编辑输出。
4.5.6 评价
用户对检索出的文献目录进行检查与评价,看是否查全、查准,以便检索人员修改检索式或改选文献库。这是一个反馈过程,是必不可少的。
用户评价检索系统结果与检索系统性能,往往会考虑下述三个问题:
(1)内容
也就是检索结果在多大程度上解决了用户的问题或满足了用户的需求。这决定于两个要素:一是库存的质量,即库中有多少能满足用户需求的信息;二是检索系统的质量,它能否将用户所要的信息都能找出来。
(2)耗费
包括时耗与费用,时耗又可分为检索速度和检准率。存储方法与检索算法对检索速度有很大的影响,已存在若干好的方法,但是不存在万能的存储方法与绝对最快的检索算法。
(3)人机界面
即人机进行对话与检索答案的提供方式和形式。