第三节 检索语言
1 检索语言简述
1.1 检索语言的涵义
众所周知,语言是人类所特有的、用来表达意思的交流思想的工具。所谓检索语言是一种人工语言,它是用来表达文献信息外表特征和内容特征的一种思想交流的人为工具。具体而言,检索语言是一种专门的语言,它是文献信息检索工具的编者和文献信息检索者,共同使用的经过约定的人工语言。用这种语言表达文献信息的外表特征如:书名、篇名、作者、页码、出版地等,其表达内容特征如分类语言、主题语言。
1.2 检索语言的功能
检索语言的功能有以下几点:
(1)简单明了而又规范化地标引文献信息的外表特征和主题内容。
(2)对内容相同及相关的文献信息加以集中或揭示其相关性,使得大量分散的文献信息存贮系统化、组织化,便于进行有规律的文献信息的检索。
(3)便于将标引语言与检索用语,进行相符性比较。
1.3 检索语言的作用
文献信息的存贮和检索是两个联系紧密的过程,这两个过程中,对文献信息都要进行标引的处理,才能实现文献信息检索工具的职能。而在文献信息存贮与检索的过程中,要有四种人参与,即有文献著者、文献信息检索工具编者(即文献贮存者)、文献信息检索者、信息用户。这些人的专业知识、经历各异,居住地区和语言习惯差别很大,使用自然语言进行文献存贮和检索,就会产生巨大障碍,影响了学术思想的交流,如果不采取措施,克服语言上的差异,就没有共同的语言来确保对文献信息标引处理的一致性,就会出现存贮进去,而取不出来,即使检索出来,也只能是一些残缺不全的文献。因此,为了使文献信息检索顺利完成,必须在存贮时,对文献信息的外部特征和内容特征要用一种语言进行描述,而信息检索时,对信息的要求,也必须使用与存贮中相同的描述语言加以表达。为此,这四种人必须使用一种人为统一的语言,才能进行文献信息的思想交流。这样的人工语言,就要在自然语言的基础上发展完善。它们在文献信息存贮过程中用来描述文献信息的内容和外表特征,从而形成了检索标识;而在信息检索过程中也要用这种统一的人工语言来描述检索提问,从而形成了提问标识。当提问标识与检索标识完全匹配或部分匹配时,即可命中信息。显见,检索语言保证了这四种人在文献信息的传递、交流中,顺利有序地进行思想交流。
1.4 检索语言同义异词的名称
由于近些年来,文献数量猛增,人类的信息传递与交流日益频繁,尤其是检索工具和数据库增长过快,才提出检索语言这个新概念。然而,类似这种检索语言的概念,早就存在,如分类法。我国在两千年前就已存在。虽然是新概念,但其中叫法却不统一。常见的名称有:情报语言、情报检索语言、文献语言、索引语言、标识语言、标引语言、信息语言、信息检索语言、文献存贮与检索语言等等。总之,名目繁多,而其实质均为检索语言。
2 检索语言的种类
检索语言种类很多,可从不同角度加以划分。
2.1 按描述文献特征划分
(1)描述文献外部特征的检索语言
这种语言是以文献上标明的,显见的外部特征,如题名、著者姓名、文献序号、文献出处、页码等作为文献的标识和检索的依据,供人们进行标引和检索。
(2)描述文献内容特征的检索语言
这种语言包括分类法(体系分类法、分面分类法)、主题法(标题法、单元词法、叙词法、关键词法)。
内容特征语言与外部特征语言相比较,它在揭示文献信息特征与表达信息提问方面,具有更大的深度,在用来标引与检索信息时,更需要依赖标引人员与检索人员的智力判断。内容特征语言的结构与使用规则,也远比外部特征语言复杂。因此,对内容特征语言的研究,成为检索语言研究的主体与核心。
2.2 按标识组配方式划分
(1)先组式检索语言
该种语言是指描述文献信息主题概念的标识。在检索之前,即存贮时,就已经事先固定好了的标识系统。如体系分类语言、标题词语言等。
(2)后组式检索语言
该种语言是指描述文献主题概念的标识,在检索之前,即存贮时,并未固定组配,而是在检索时,根据检索的需要,按照组配规则临时进行组配的标识系统。如叙词语言、单元词语言等。
2.3 按结构划分
2.3.1 分类检索语言
该种语言是以分类号作为文献概念标识的标识系统。包括体系分类语言、组面分类语言、混合分类语言等。
2.3.2 主题检索语言
该种语言是以主题词(标题词、单元词、关键词、叙词等)作为文献主题概念标识的标识系统。如标题词语言、单元词语言、叙词语言等。
3 检索语言的构成
检索语言由描述文献信息外表与内容特征的两大语言范畴构成。其语言由词汇系统和语法两部分组成。词汇系统是用以表达文献或提问特征的词的集合。一个标识(如分类号、主题词、著者姓名、序号、代码等)就是检索语言中的一个词。语法则是运用单个或多个标识来正确表达文献主题或提问概念的一套规则。
检索语言还必须具备下列三个基本要素:
其一,有一套用于构词的专用字符;
其二,有一定数量的基本词汇来表达各种基本概念;
其三,有一套专用语法规则来表达各种复杂概念标识系统。
字符是检索语词的具体表现形式,它可以是自然语言中经过规范化处理的一系列名词或名词性词组,也可以是给以特定含义的一套数码、字母或代码。
基本词汇是指组成一部分类表或词表中的全部检索语词标识之总汇,如分类号码的集合就是分类语词的词汇。分类表、词表等也可以说是检索词词典,是把自然语词转换成检索用语的工具。
任何一种检索语言,不管其是语词的、还是符号的,都是表达一系列概括文献信息内容的概念及其相互关系的概念标识系统,它们全都建立在概念的逻辑基础之上。
下面仅简要介绍概念逻辑的基本知识,为防患今后应用检索语言时产生概念模糊、逻辑混乱的差错。
其一,概念的内涵与外延
内涵是它所指事物的本质属性;外延是它所指的一切事物,即概念的适用范围。
其二,内涵与外延的反变关系
内涵越浅,本质属性越少,而外延就越广,适用范围就越大;内涵越深,本质属性越多而外延越窄,适用范围就越小。
其三,概念的关系:相容与不相容关系
相容关系:同一关系即如电子计算机与电脑;属种关系如文学作品与小说;交叉关系如彩色电影片与宽银幕电影片;整体与部分的关系如人与人体的心脏;全面与某一方面关系如机械与机械设计。
不相容的关系:并列关系如社会科学与自然科学;矛盾关系如金属材料与非金属材料;对立关系如导电机与绝缘体。
检索语言在表达各种概念及其相互关系时普遍应用了上述概念逻辑原理。并且有效地利用概念的划分与概括和概念的分析与综合,这两种逻辑方法来建立自己的结构体系。
4 分类语言
分类语言是运用概念划分的方法,按文献信息内容所属学科、专业性质的逻辑次序,以号码为基本字符,用分类号表达文献信息的主题概念,用以存贮文献与检索文献的标识体系。目前,世界上的检索工具中,应用分类语言数量最多。
分类语言按其号码构成原理,又可分为体系分类语言和分析——综合分类语言,其中,体系分类语言最为常用。
4.1 体系分类法(语言)
所谓体系分类法是一种直接体现知识的等级概念的标识系统。它根据一定的观点,以科学分类为基础,文献信息内容的学科性质为对象,按照知识门类的逻辑次序即从一般到具体,从简单到复杂,从粗到细,进行层层划分,产生众多的类目,并将每个类目付与分类号码作为此类标记。这些类目又层层隶属,等级概念又相并列,组成一个严格有序的直线式的知识门类的等级体系,形成了层累制的先组式的文献存贮和检索的周密的标识系统。
4.2 分类的概念和作用
分类法中的类又称类目,是指具有共同属性的一组文献资料。文献分类是按照文献信息中所含知识信息的学科属性,对文献信息进行区分,进一步根据文献的知识信息内容之间的内存联系组成科学的分类体系。其目的是将同一学科或学科门类的文献信息集中在一起,便于从学科的角度进行检索和利用。
分类法的具体表现形式是分类表。分类表是由一系列分类号和类目名称集合而成。分类号是知识信息概念的具体标识符,其字形有文字型(罗马字母、希腊字母、汉字等)、数码型(阿拉伯数码、罗马数码)和以上两种合成混合型。它能反映事物概念的派生、隶属、平行等关系。便于检索者对知识信息“鸟瞰全貌”、“触类旁通”,随时可以放宽或缩小检索范围,提高检索效率。
4.3 分类法及其原理
一部分类法实质上就是一套概念标识系统。
体系分类法采取对文献论述的事物概念进行层层划分、层层隶属的办法来形成一系列专指的分类标识,按照科学体系将分类标识组织成具有隶属、并列关系的概念等级标识系统。
组配分类法(即分析——综合分类法)是在体系分类法的基础上创造而成。其构成原理基于概念的可分析和可综合性。通过概念组配可以将有限的类目扩充,组配成无限的主题概念,组成分类标识的各个因素,亦可以随着检索者的需要变换位置,有很大的灵活性,因此,较之体系分类法,它更适合对文献信息的知识信息的检索。不过此法使用有限。
4.4 分类表的组成及其功能
4.4 .1分类表的组成
分类表大体上由下列部分组成:
(1)编制说明:包括列类原则、体系结构标记方法等。
(2)基本大类:用户据此可以对某一分类体系有一个总的了解。
(3)简表:它是分类表的骨架,起着承上启下的作用。对文献进行分类时可先用简表作引导,再查找到详表中的适当细目。
(4)详表:也称主表,是分类表的正文部分,是文献存贮者和检索者详查的对象和依据。
(5)辅助表:又称复分表。它们用以细分详表中的有关类目。其功能是减少分类表的篇幅,并且有一定的助记性,一般它附于详表之后,或附于之前。
(6)类目索引:本索引将各个类目的类名按字顺排列,并指出相应的分类号,为此,有助于确定分类号,更便于从某个主题去查找有关类目。
4.4.2 分类表的功能
分类表在文献信息存贮和检索的过程中,其功能主要反映在下述两个方面:
(1)分类表是标引文献信息和组织分类目录的依据,又是文献信息资料分类排架的依据。
(2)分类表是检索者从学科、专业角度检索文献信息时的依据。
4.5 分类语言的优缺点
4.5.1 分类语言的优点
(1)科学系统性
分类语言是以学科分类为基础,较好地体现了学科的系统性,符合人们认识事物的规律和处理事物的习惯,因此,人们很容易从学科和专业角度检索文献信息。
(2)简明性
分类语言是一系列分类号的有机的集合体,而分类号由数码,或字母、数码相混合,其知识信息概念是以分类号为其标识,分类号简单明了便于记忆,进行检索时还可克服语言文字上的表达困难。
(3)严密性
由于分类语言是以科学分类为基础,分类法中能把整个学科体系的内部联系起来,产生各自派生、隶属、平行等关系,再将其层层展开,可见每个类目之间的各种关系十分严密,形成统一的科学整体。
(4)兼用性
此种语言可用于图书、期刊分类与排架顺序。还可用于单编资料的分类,以及兼用于有关数据库内文献信息的分类与排序。
4.5.2 分类语言的缺点
(1)间接性
检索工具编者,将有关文献的主题概念,转化为分类号,存贮于检索工具中,检索者将所需文献信息的主题概念转化为分类号,再到检索工具中依号查找。由于相互转换,很容易发生误差,就有可能发生误检或漏检。
(2)单维性
又称单面性。分类法能够较好地反映学科知识信息的单维的纵向的(或线式的)关系。而当今各学科知识是相互交叉、相互渗透,知识之间有着横向联系的多维性的知识空间,分类法却不能反映多维性的知识空间。因此,使用分类法检索时也极易发生漏检。
(3)局限性
分类语言是一种先组式检索语言,具有相对的稳定性,不能随时修改和增删,难以反映新兴学科和科学技术发展的内容,因此难以标引和检索新兴学科和科学技术发展的文献信息。同时,分类语言仅对知识信息的主题概念提出大范围的类目,不能标引和检索专指度很高的文献信息,可见,分类语言不可避免地存在这种局限性。
4.6 国内外主要分类法(语言)简介
4.6.1 我国主要的分类法
中华人民共和国成立之后,我国图书馆界广泛地使用了《中国人民大学图书馆图书分类法》(简称人大法)、《中国科学院图书馆图书分类法》(简称科图法)、《中国图书馆图书分类法》(简称中图法)及其《中国图书资料分类法》,这几部分类法均以马克思主义、毛泽东思想为指导思想,以辩证唯物主义和历史唯物主义为编制依据,其分类体系是以科学分类为基础,采取从总到分,从一般到具体的逻辑系统,各分类法部类的设置大同小异,部下各类不同的设置各有特色。
(1)《中国人民大学图书馆图书分类法》
《中国人民大学图书馆图书分类法》简称《人大法》,是中华人民共和国成立后编制的第一部新型的图书分类法,1952年由张照、程德清主持编成初稿,1954年正式出版第一版,1955年出版第二版,1957年出版第三版,1962年出版第四版,1982年出版第五版。《人大法》出版后,曾被许多图书馆特别是政法经济方面的高校图书馆所采用,新华书店和《全国总书目》、《全国主要报刊资料索引》也曾使用过《人大法》。
《人大法》第六版于1996年3月由中国人民大学出版社出版。该版是在第五版的基础上修订而成的,从1991年4月《人大法》第六版修订委员会和修订工作小组成立至1995年6月正式定稿,直至1996年3月出版。《人大法》第六版的修订原则是,坚持“三个不变”:即17个大类不变,体系结构基本不变,标记制度基本不变。
此分类法由4大部类、17个大类,1个复分表和2个附表组成。《人大法》严格地采用层累制,号码采用纯阿拉伯数字。以数字的位数表示类目的等级,每一位类号代表一类。如遇两位数字表示一类,则在其后面加注小圆点“.”,表示仍是代表一类,如“11.历史、革命史”、“12.地理、经济地理”等。对全部类目等级列举展开。这种类号的等级排列层次分明,能从数位上看出类目间的相关性和一致性。
(2)《中国科学院图书馆图书分类法》
《中国科学院图书馆图书分类法》简称《科图法》,是由中国科学院图书馆1958年正式编辑出版,1959年增编索引,1979年出版社会科学修订二版。该法很适用于自然科学有关图书分类。总体结构分为5大部类,下分25个大类。《科图法》是体系分类法,类目采取层层划分、详细展开的方式,形成一个等级分明的类目体系。
《科图法》类目表中还设置了内容范围注释、例注、交替类目注释、参照类目注释、名称注释、复分与仿分注释、特殊分类方法注释以及同类书排列方法注释等。
《科图法》采用阿拉伯数字单纯号码。号码分为两部分:第一部分采用整数顺序数字,从00~99分配到5大部、25大类及其主要类目中;第二部分基本上采用小数层累制,即在主要类00~99两位数字以后加一小数点“.”,小数点后基本上按小数体系计算,以容纳细分的类目。另外,还使用了一些灵活的配号方法,如:八分法、双位制、借号法等。
《科图法)第三版还设有7个通用复分表。
(3)《中国图书馆图书分类法》
《中国图书馆图书分类法》简称《中图法》,由北京图书馆等组织全国力量编辑,1975年出版第一版,1982年出版第二版,1988年出版第三版,1999年出版第四版。它是我国图书信息界为实现全国文献资料统一分类编目而编制的第一部大型文献信息分类法。该法是由5大部类、22个大类、6个总论复分表,30多个专类复分表,4万余条类目组成的一个完善的分类体系。部类设置采用五分的办法。即马列主义、毛泽东思想作为一个基本部类列于首位,正确体现了整部分类法的指导思想,对于一些内容涉及面广,类无专属的文献统归为“综合性图书”,作为一个基本部类列于最后;哲学、社会科学和自然科学按其知识内容的逻辑关系列为3个大部类予以排列。
该法的标记制度采用了汉音拼音字母与阿拉伯数字相结合的混合小数层累制,以字母顺序反映大类序列。对类目的排列采用不同字体和行格等形式来表示类目之间的关系。
为了照顾类目的发展和标号的完整性,辅助以数字号码以补充类号的不足,还采用了一些辅助符号来构成组配类号。
《中图法》结构如下图:
五大部类 二十二大类
马克思主义、列宁主义、毛泽东思想……A马克思主义、列宁主义、毛泽东思想、邓小平理论
哲学…………………………………………B哲学
社会科学……………………………………C社会科学
D政治、法律
E军事
F经济
G文化、科学、教育、体育
H语言、文字
I文学
J艺术
K历史、地理
自然科学……………………………………N自然科学总论
O数理科学和化学
P天文学、地球科学
Q生物科学
R医药、卫生
S农业科学
T工业技术
U交通运输
V航空、航天
X环境科学、劳动保护科学
综合性图书…………………………………Z综合性图书
(4)《中国图书资料分类法》简称《资料法》,目前有四个版本,其中第一版、第二版、第三版分别于1975年、1982年、1989年由科学技术文献出版社出版,《资料法》第一至三版曾属于《中图法》的系列版本,由《中图法》编委会统—管理,具体由中国科学技术情报研究所(后改名为中国科技信息研究所)组织有关科技情报部门在《中图法》的基础上编制而成。《资料法》第一至三版与《中图法》第—至三版两者在体系结构、类目设置、类目注释、标记符号、复分表等方面基本相同。为了发挥《中图法》不同版本的作用,提高不同版本的实用性,1988年《中图法》第二届编委会作出决定:《资料法》在与《中图法》保持两者体系结构一致性的前提下,应与《中图法》在编制上有所不同。其区别在于:分类深度不同。《中图法》主要用于图书分类,起分类检索和分类排架的双重作用,类目的系统划分一般控制在六级左右;《资料法》主要用于文献资料的分类检索,类目的系统划分一般控制在八级左右;组配方法有所不同。《中图法》在指定的类目下采用组配方法。《资料法》为适应文献资料的专深检索和边缘学科文献分类的需要,则可较广泛地使用组配方法;附加符号的使用有所不同。《中图法》可采用国家、地区、时代附加符号。《资料法》除能采用上述附加符号外,还可采用民族、时间附加符号与联合符号。
1996年6月原国家科委信息司下发《关于修订(中国图书资料分类法)第三版的通知》,专门组建了《中国图书资料分类法》编辑委员会,并征求19个部委情报信息所和有关单位对各专业类表的修订意见,在中国科技信息研究所成立了《资料法》修订编审组,从1996年下半年起,《资料法》第三版的修订工作开始启动。《资料法》第三版的修订内容主要体现在两个方面:①在类目体系方面,在保持与《中图法》体系结构一致的基础上,除吸收《中图法》第四版新增加的类目外,重点修订和增补了自然科学与工业技术方面的类目。②增强了《资料法》的组配功能,以适应网络环境下机检的需要。《资料法》第四版于2000年2月由科学技术文献出版社出版。
《资料法》第四版的大类体系与《中图法》第四版的大类体系基本一致。《中图法》第四版编有22个基本大类,《资料法》第四版编有38个基本大类,两者并无实质上的区别。因为《资料法》第四版将《中图法》中“T工业技术”大类所属的16个二级类目(TB/TV)类作为基本大类。38个大类的展开采取层层划分、详细列举的方式,形成一个等级分明的类目体系。有些类目的展开可达8级以上,类目表共设置约5.6万个类目。
《资料法》第四版所采用的标记符号的种类、标记制度与《中图法》第四版相同,即采用字母与阿拉伯数字相结合的混合号码。基本上采用层累标记制,为了适应类列的展开,也采用了八分法、双位制、借号法等灵活的编号方法。
A 马克思主义、列宁主义、毛泽东思想、邓小平理论
B 哲学、宗教
C 社会科学总论
D 政治、法律
E 军事
F 经济
G 文化、科学、教育、体育
H 语言、文字
I 文学
J 艺术
K 历史、地理
N 自然科学总论
O 数理科学和化学
P 天文学、地球科学
Q 生物科学
R 医药、卫生
S 农业科学
T 工业技术
TB 一般工业技术
TD 矿业工程
TE 石油、天然气工业
TF 冶金工业
TG 金属学与金属工艺
TH 机械、仪表工业
TJ 武器工业
TK 能源与动力工程
TL 原子能技术
TM 电工技术
TN 无线电电子学、电信技术
TP 自动化技术、计算机技术
TQ 化学技术
TS 轻工业、手工业
TU 建筑科学
TV 水利工程
U 交通运输
V 航空、航天
X 环境科学、安全科学
Z 综合性图书
《资料法》结构图
4.6.2 国外主要图书分类法
(1)杜威十进分类法(DeweyDecimal Classification and Relative Index)
其简称DC或DDC或杜威法,又名《十进制图书分类法》,是美国图书馆学家麦威尔·杜威(Melvil Dewey)所创制的,初版于1876年,1996年已出版第21版。其书名原为《图书馆编目排架用分类法及主题索引》,总共42页,1885年2版,更名为《十进图书分类法及相关索引》,才奠定了《杜威法》的体系。
这是一部在国际上出现最早、流行最广、影响最大的图书分类法。它受到英国科学家培根的知识分类的影响,据以将其知识分类体系进行倒排,采用十进制的等级体系。该法将所有学科归纳成9个大类,这9个大类表示9个专门的主题范畴。各类中的类目均按从一般到具体,从总论到具体的组织原则。把涉及全部知识而不能归入任何一门学科的图书入为第0类称总论,其序列居于其他学科知识门类之首,一级大类之下,以圆点相隔再分小类,称子类,每个一级大类再分为10个子类,依此逐级分类,形成一个层层展开的等级体系。第18版起,该分类法采用了一些分面综合手段,增强组配性能。以下是《杜威法》十个大类:
000 Generalities(总论)
Philosophyand related disciplines(哲学及相关科学)
200 Religion(宗教)
300 Social sciences(社会科学)
400 Language(语言)
500 Pure sciences(纯科学)
600 Technologyand applied sciences(技术或应用科学)
700 The arts(艺术)
800 Literature(Belles-lettres)(文学)
900 General geographyand history(普通地理和历史)
又如600类之下又分为:
600 技术或应用科学
610 医学
620 工程学
630 农业
640 家政
650 管理与辅助服务
660 化学工业
670 制造业
680 各用途产品制造
690 建筑工程
在620类目之下,又分为许多小类目,如:
620 工程学
621 应用物理学
621.1 蒸汽工程
621.2 水利工程
621.3 电力工程
随着科学技术的迅猛发展,该分类法的一些问题日益突出,如其分类体系陈旧,类目简繁不均等等,但是,其历史悠久、影响广泛,《杜威法》仍是世界图书分类史上的一个里程碑。
(2)国际十进分类法(Universal Decimal Classification)
《国际十进分类法》(UniversityDecimal Classification)简称UDC。由比利时两位学者鲍威·奥特勒(Paul Oiler,1868—1944年)和亨·拉芳(Henri I Fontaine,1854—1943年)在DDC《杜威法十进分类法》的基础上编制而成的,初版于1905年,现已出第三版,它是一种半组配式的体系分类法。目前它有23种不同语言的版本,成为世界图书情报的国际交流语言并用于组织网上资源,是世界上最为广泛使用的分类法之一。从60年代末起,被称为世界性图书信息的国际交流的分类检索语言。这种分类法由主表、辅助表及辅助符号三大部分组成。主表把知识信息划分为10大门类,大类划分沿用《杜威法》的基本大类结构,详表有近203个类目,它是世界上现有各种分类法中类目设置最多的一部,尤其科技部分设类更为详尽。
UDC基本大类设置如下:
0总类
1哲学
2宗教
3社会科学、经济、法律、行政
4(语言学)(该类1964年已并入第8类,现空类)
5数学、自然科学
6应用数学、医学、工业、农业
7艺术
8语言学、文学
9地理、传记、历史
UDC类目区分程度比DDC详细,按照从一般到特殊的原则,逐级进行区分,形成层层展开、详细列举的等级类目体系。例如:
6 应用科学、医学、技术
62 工程技术
621 机械工程总论、核技术、电气工程、机械制造
621.3 电力工程
621.39 电信技术
621.394 电报
621.394.6 电报设备
621.394.62 收报机
621.394.625 记录接收器
621.394.625.2 穿孔记录、穿孔纸带
621.394.625.4 记录装置、定向设备
UDC类目的明细度也高于其他分类法,是目前展开最广泛的一部分类法,比较适合于专指度高的检索语言。
UDC的标记制度采用等级分明的阿拉伯数字结合多种辅助符号,列举和组配混合式结构。通过对事物整体概念的逐层分析,对所谓的特定概念的立类、列类,同时将不同的特定概念进行组配,使之较好地反映多主题、复合主题的文献信息,用以解决任何复杂文献信息的主题标识,提供多途径检索。
5 主题语言
5.1 主题语言概述
5.1.1 什么是主题语言
主题语言又称主题法,它是一种描述(或表述)语言。它是使用自然语言中的(经过规范化处理的)名词、术语为基本词汇,以及规范化的名词性词组和句子,描述文献信息所论述或研究事物的主题概念,以主题词作为标识的一种文献信息的检索语言。
文献信息的主题是文献研究、讨论、阐述的具体对象或问题。它可以是自然现象、社会生活现象,也可以是各种学科、人物、事件和地区等。
主题词是主题语言的核心,它是用以表述或描述文献信息主题概念的名词、术语。这些名词、术语取自于自然语言之中,有的经过规范化处理,有的本身就是自然语言中的一个部分。
5.1.2 主题词的规范化
所谓规范,就是对自然语言中有语义关系的语词,按照文献信息检索的要求进行优选,并且限定语词的内容含义,保证语词的单义性,即是说,一个主题词只能表达一个概念。对主题词规范化处理,包括下列几项:
(1)词义规范:包括有同义词、近义词、多义词的规范化处理:
其一,同义词的规范:同义词即多词一义词,常见的如学名与俗名、全称与简称等。同义词规范采用优选方法,保证一个主题词只对应一个概念,即把非通用概念的同义词规范成通用概念的主题词。如:
电脑(不规范主题词)
电子计算机(规范化主题词)
其二,近义词规范:近义词即词义相近的词。一般选择较概括的通用的词做主题词。如:
格言(不规范化主题词)
谚语(规范化主题词)
其三,多义词的规范:多义词即同形异义词,可用范围注释对其词意进行限定。如:
杜鹃(植物);杜鹃(动物)
(2)词类规范:名词或名词性的词、词组可以做主题词。其余词类则不能单独作为主题词,必要时,可与名词或名词性的词、词组共同构成主题词。可数名词则用复数形式。如:
Microcomputers;Testing
(3)词性规范:词性规范主要指词组的正叙式、倒置式、并列式的处理,以免使之排检发生歧义。
其一,正叙式:将事物名称过程的名词或名词性的术语作为主题词。如:
种子、休眠
其二,倒置式:将事物或过程名称放在前面,后面加上进一步表示特性的修饰性词语,中间用逗号分隔,这样便于同一类事物的文献信息相对集中。如:
汽车,设计
汽车,消防用
其三,并列式:将既有联系又各自独立的事物或概念并列起来。如:
Roads and Streets
5.2 主题语言的优缺点
5.2.1 主题语言的优点
(1)直观性
主题词来源于自然语言中,标识比较直观,符合人们的辨识习惯,便于记忆,主题词在词表中按词的字顺排列,序列明确,易于查检和利用。只要会使用字典、词典,一般都能很顺畅地使用这种语言。
(2)专指性
由于主题词是从揭示特定事物着眼,而不是泛泛而论,用主题词的语词作为标识,而这些语词一般都是经过规范化处理的,一个标识与一个概念严格对应,使得主题词对文献主题的概念,描述得更为具体,更为深入,更具有专指性。
(3)灵活性
通过词与词之间的概念组配来揭示文献中形形色色的主题,是主题语言的主要特征。尤其是后组式的组配原则,便于人们按照检索需要,自由组配检索概念,具有很大的灵活性。
(4)网罗度高
一个主题词表达一个泛指的事物概念,若干个主题词合乎逻辑的组配,可形成高度专指的概念特征,用于标引文献时,即可达到高度的概念网罗度。
5.2.2 主题语言的缺点
(1)分散性
由于主题语言是用语词来表达文献信息内容特征的,这些语词按字顺排检,这种排检的规律却无逻辑性。因此,检索时,使用主题语词查找不同事物具有同一属性的族性检索,其主题词却分散地排列在不同的字词之中。如,我们查铁和钢的有关文献信息时,却分散在T、G两个字顺段里。显然,由于其分散性,查寻时很不方便。
(2)不统一性
由于主题词来源于自然语言,而自然语言多样化,又随着科学技术飞速发展,新学科兴起,新技术广为应用,主题词、语又不断随之增补和删减,加之国别、地区有异,使用语言标准有别等条件的限制,致使主题词语不够统一,影响了主题语言使用效益。
5.3 常见主题语言简介
5.3.1 标题词语言
(1)简述
标题词语言又称标题法。它是以规范化处理的自然语言,即用已规范化的具有固定组配的科学技术名词、术语及其词组、短语,来标引文献信息的主题概念,并将其标题词语的标识按字顺顺序排列,成为文献信息存贮和检索体系。标题词语言是一种最早出现的主题语言,它与体系分类法一样,均属于先组式的文献信息检索语言。可称谓传统主题法。
(2)标题词语言的结构
标题词的结构通常由主标题(又称一级标题)和副标题(又称子标题,或称二级标题)词语组配而成,这种结构称为两级标题。两级标题是按“事物——事物的方面”的原则组成,即是说,主标题(即一级标题)主要表述主题的“事物”和少量的“过程”,而副标题(二级标题)主要描述事物的“方面”、“过程”。可见,主标题为事物的主体,“事物的方面”为副标题,用以进一步限定、修饰、细分主题词(换言之,副标题为主题的说明语)。有时形成三级标题而不多见。
主标题与副标题之间的关系反映概念之间和等同关系(同义词、学名和俗名,新名与旧名);等级关系(属种、部分与整体);相关关系(交错、矛盾、反对、因果)等关系。
标题词首先按主标题词字顺排列,可使同一主题内容文献信息集中在一起,然后再按副标题词的字顺编排,这样可体现出两级标题的“事物——事物的方面”的组成原则。形成了检索工具的主、副标题的排检的系统。
(3)标题词的参照系统
为显示事物概念之间的相互关系,标题词法中用见(See)、参见(See also)和标题词范围注释来处理反映主题事物概念之间的同一关系、属种关系和相关关系,使反映某一事物的同义概念、属种概念、相关概念的若干文献有机地联系在一起,增加了检索途径,有利于提高文献信息的查全率。
其一,见(See)的参照作用:“见”用来把不作标题词的自由词引见到作为标题词的规范化词汇。“见”所指引的标题词有如下几种:
A同义概念:如“土豆”见“马铃薯”。
B下位概念:如“通讯”见“电信”。
C上位概念:如“合金”见“金属与合金”。
其二,参见(See also)的参照作用:“参见”用来把标题词引见到其他相关标题词,使检索者或用户能够从更多的检索入口,查到相关的文献信息。
如:“荧光屏”参见“磷光体”。
其三,主题注释的作用:“注释”是说明标题词的意义、用法和所属学科等。主题注释有以下几种:
A用于说明主标题词的意义和使用范围。例如:
ACCELERATORS
(Use for general subject of particle accelerators and for specific particle accelerators not elsewhere classifiable.See inverted headings for specific types ACCELERATORS,BETAON)
括号内的注释为:“加速器”这个标题词用于一般粒子加速器,对于特殊类型的加速器,用倒置主题词,如“加速器,电磁感应”作为电磁感应加速器的标题词。
B指导二级主题词的选择。例如:
CHEMICAL PLANTS
(For subheadings,see BUILDINGSand/or INDUSTRIALPLANTS)
即“化工厂”这一主题词下的副标题词,与“建筑物”和(或)“工厂”这两个主题词下的副标题词是一样的。
C说明主标题还有更专指的标题。例如:
AIRCRAFT
(Use for general subject,for specific aircraft,See inverted headings,as AIRCRAFT AMPHIBIAN,etc.)
AIRCRAFT用于一般的飞机。特种飞机则见倒量定语的飞机,如水陆两栖飞机等等。
(4)标题词的选词与规范
标题词主要来自于科学名词、术语,而科技名词、术语成千上万,甚尔难计其数,如果标题词不加选择,全部采用,必然会使文献信息检索工具篇幅更加膨胀,造成编制巨大困难,检索很不方便、快捷,因此,必须严加选择,控制词量,实现用词规范化。
其一,选词的原则:
A主标题必须是描述“事物”或少量“过程”的名称,副标题必须是表达事物或过程方面的性质、部分、现象、方法、操作等名词。
B适度专指性。标题词必须是直接而精确地表述文献的主题概念。不收集泛指名词(如零件、设备等),而这些专指性名词也不能全部采用,要有选择地归并。
C通用性和准确性。通用性是指选用的科技名词必须是通用词。但这种通用词必须要以准确性为前提。否则,不能选用。
其二,标题词的规范化
由于标题词来自自然语言,这些语言并没有统一的规范化,如语义、词形的状态等方面多种多样,因此,选词后还要加以规范化地处理。
A语义规范。即对同义词、近义词、多义词等语义规范化处理。如:同义词中选取通名、准确、专指性很高的词语作为标题词。
B词的形体规范:如汉语中简体、繁体、异体的几种字形,应以通用的简体字为标题词所用字形。
(5)标题语言词表
标题语言中对词汇的规范化以及参照系统的建立,均通过标题语言词表加以体现。它是标题词语言存贮和检索文献信息的依据。该表由下列三个部分组成。
其一,编制说明。说明编表经过,收录标题词的学科和专业范围,选词原则及规范化措施,标题词款目的著录格式、辅助符号的含义,及其排列方法等。
其二,主表。是该表的正文,包括全部的标题词、非标题词,按字母顺序排列,并有显示词间关系的参照和注释。
其三,附录。包括副标题词表以及附录。
(6)标题词语言的特点
其一,它以事物为中心集中了文献,不过从学科、专业的分类角度而论,却又将同类文献分散开来,可见,它只适用于以主题角度进行文献信息的检索。
其二,它用标题词语直接标引文献的主题概念,其直观性很强。
其三,它按字顺排列文献标识系统,容易掌握,检索快捷。
其四,它属于先组式检索语言,虽然其专指性较高,但不如后组式的专指性,加之,其标题词有相对稳定性,难以及时反映出因科技发展而产生的新学科、新概念。
5.3.2 单元词语言
单元词语言又称单元词法。它脱胎于标题词语言,改革了标题法的先组式,成为主题语言中后组式语言的先驱。这种语言现已发展成叙词语言,单元词法已被淘汰。我们提出来,了解其构成原理、方法、性能等,有助于深入了解叙词语言。
单元词是指最小、最基本的词汇单位,经过规范化处理,以此作为文献主题概念的标识。它不选用词组、短语来表达复杂概念,这是单元词法与标题法的主要区别。例如,对“公路桥梁”这个概念,单元词标引时用“公路”和“桥梁”两个单元词组配来表述,而标题法直接用“公路桥梁”词组表达它们。
单元词法的特点在于它的元词组配和后组式,而元词的组配顺序不分前后,而且,在检索时,将所需文献的主题概述进行元词组配,其词量增减的自由度较大。若根据检索所需文献的要求,可查出专指性很高的文献。
单元词语言尚存两个问题:
其一,标引深度的问题。检索文献时,若用词很少,其所查文献的专指度过低,检准率也低。若提高检准率,检索时用词较多,又会造成漏检,而一篇文献提供的信息量是有限度的,若标引用词过多,必然涉及价值不大的内容,即是说标引和检索用词多少才能提高检准率,仍是需要进一步研究的问题。
其二,概念或词的解析问题。单元词法是将复杂概念或词组解析为单元概念或单元词,然后进行组配标引和检索。但是这种解析在实践中存在不少问题。例如:“机械清洁问题”,可用“机械+清洁”进行标引,用这两词检索,所查出文献却为“清洁用的机械”,其义相反,确为误检。又如“蘑菇战术”解析为“蘑菇”、“战术”,用“蘑菇”一词进行检索,会产生误检。由此可见,这种解析极易产生逻辑混乱。必会产生大量的误检和漏检。
5.3.3 关键词语言
(1)简述
所谓关键词,是指在文献信息的标题(如篇名、章节名)、摘要、正文中,对表达文献主题内容具有实质意义的自然语言。即是说,这些词语对揭示和描述文献内容特征而言是至关重要的带有关键性(即可作为检索“入口”的)作用。由于它对能否检索到这篇文献起着关键性作用,所以才称为关键词。
关键词语言又称关键词法,它是属于后组式的主题语言,它是将文献原来所用的,能描述其主题概念的那些具有关键性的词语抽出,不加规范或只作少量的规范化处理,按字顺排列,提供检索途径的方法。该法一经采用,就出现了多种关键词索引形式。
在电子计算机技术引入文献检索的编辑工作后,为了提高检索工具利用率,缩短其出版时间,编辑抽取主题词时,出现了从文献中抽取的未经严格规范处理的主题词(即关键词)作为文献标识的语言,这种语言一经利用大大缩短编辑时间,因此,关键词语言适用于计算机编制关键词索引,缩短其编辑时间,同时它使用未经处理的自然语言,读者易于使用。
(2)关键词的规范化处理
关键词一般说来未经规范化处理,但是对没有检索意义的和无实质意义的词,也进行删减。如:冠词、介词、连词、代词、感叹词、某些形容词、某些动词(助动词、连系动词、情态动词),以及缺乏检索意义的名词,如:技术、应用等词加以删除。
(3)关键词索引简介
利用关键词语言编制检索工具的索引,其类型较多,常见有以下几种:
其一,普通关键词索引(Keyword Index,简称KWI),该索引又称单纯关键词索引。它用于表达文献内容特征的关键词编成索引款目,其中,对主要关键词轮流排为检索标目位置之首,其余关键词排在其后(或下面)作为限定词,与检索词组成短语,一般按字顺排,每条短语后附文献地址(即参考号码)。如美国《化学文摘》每期均编此索引。
其二,题内关键词索引(keyword in content index简称KWIC Index),亦称上下文关键词索引。索引由左、中、右三栏组成。左栏和中栏为文献题名,右栏为文献地址,中栏开头是检索词位置,也是检索的入口处,检索词按字顺排列。这种关键词索引的关键词来源于文献篇名,并将文献标题中的关键词和非关键词均予保留,并保持标题原文的顺序。每个关键词都参加轮排,一篇文献的标题中有多少个关键词,就在索引中按每个关键词重复排多少次,因此,可以在任何一个关键词下,查到这篇条目。
一篇文献的一条款目在索引中只占一行,由于受计算机打印设备功能和索引编排格式的限制,每行只能容纳80~100个字符。左栏和中栏约占60~80个字符,超过长度的部分就只能舍去,因此,常发生截词现象。
有些题内关键词索引除文献标题外,还从文摘和正文中抽取关键词作为补充,一起参加轮排。如美国《生物学文摘》的题内关键词索引,当篇名意义不完全时,常加入适当的词,包括生物体、名称、物质、化学药品、仪器、研究方法、地理位置等。
其三,题外关键词索引(Keyword out context Index,简称KWOCIndex)。该索引是把文献标题内的关键词抽出来,轮流作为标目,按其字顺排列其标题。如联合国粮农组织出版的《农业索引》中的主题索引即是这种形式。
其四,双重关键词索引(D-Kwicindex)。这种索引的编排形式,可以说是前两种的结合。先从标题中抽出一个关键词(第一关键词),独立成行(标题内仍予保留,但用斜体印刷),按顺序排列,其下所列文献篇名中各另选一个副关键词(第二关键词),用黑体字印刷,或放在篇名的行首,按字顺排列。这种索引查阅方便,易读性好,但篇幅庞大,编制成本高。
总之,关键词语言具有易用、快速、客观、节省和检索点多的优点,但也存在缺点。由于该语言是未经处理的自然语言,其同义词、近义词、多义词未加规范处理,则会造成存贮和检索之间误差很大,其漏检率较高,加之关键词多,相关关系又得不到显示,为此,也给查全、查准文献信息带来困难。
5.3.4 叙词语言
(1)简述
叙词是指有组配功能、又经过规范化处理的表示单元概念的名词或名词性的词、词组。所谓叙词语言是以叙词为标识,用以存贮和检索文献的标识系统。它是后组式检索语言,成为当今主题语言的最高形式,而且适用于计算机存贮和检索,现已占据了检索语言的主导地位。
(2)叙词的组配
叙词组配有概念相交、并列、限定三种。
其一,概念相交组配。适合概念内涵不同,而外延有部分重合的概念关系组配。此种组配表现为同级词之间(即两个表达相同性质概念的叙词)或事物与事物之间的交叉组配。由于不同概念相交就会形成新概念,这个新概念是组配前各概念的下位概念(特称概念)。例如:太阳和能两个同级概念组配,产生“太阳能”这一新的下位概念。其组配结果,提高了查准率。
其二,概念并列组配。系指同级词之间的组配。因不同概念并列也会形成一个新概念,这种新概念是组配前各概念的上位概念。例如:“数字计算机”和“模拟计算机”两个概念组配后,得到“计算机”的新概念。而“计算机”是模拟计算机和数字计算机的上位概念。这种组配后,提高了查全率。
其三,概念限定组配。适用一个概念或几个主题概念,从时间、空间和学科范围某一方面的属性进行限定的一种概念关系。这种限定关系主要表现为事物及其各个方面的关系。因此,概念限定组配是两个不同级词之间的组配。即为表示事物的叙词和他的某个方面的词组配。如:“建筑物”为主体事物,设计为某个方面,组配结果得到已被限定的“建筑物设计”这个新概念,检索文献信息时,使检到的文献专指度及其检准率得到提高。
(3)叙词语言的参照系统
叙词语言的参照系统在叙词表中是控制同义词和反义词和反映叙词之间相互关系,并借以明确词的含义及其所涉及的范围的一种规范化措施,是标识的语义系统。参照系统把各个分散的独立的叙词在语义逻辑上构成一个有机整体。一般说来,叙词语言的参照系统由叙词的等同关系、属分关系、相关关系共三类关系组成。如下列叙词参照系统表所示。
a.等同关系:是指两个词或两个以上的词所表示的概念完全相同或相近,彼此之间可以相互代替的一种语义关系。
USE——用:用于将非叙词指向叙词。
UF——代:指明他所代替的非叙词。
b.属分关系:是指概念内涵相容、外延广窄不同的叙词之间的关系。
NT——分:指明狭义(下位)叙词。
BT——属:指明广义(上位)叙词。
TT——族:指明最上位叙词(族首词)。
c.相关关系:指叙词之间彼此关系密切,而又不同于等同关系和属分关系的那种联系关系。
BT——参:指明相关叙词。
叙词参照系统表
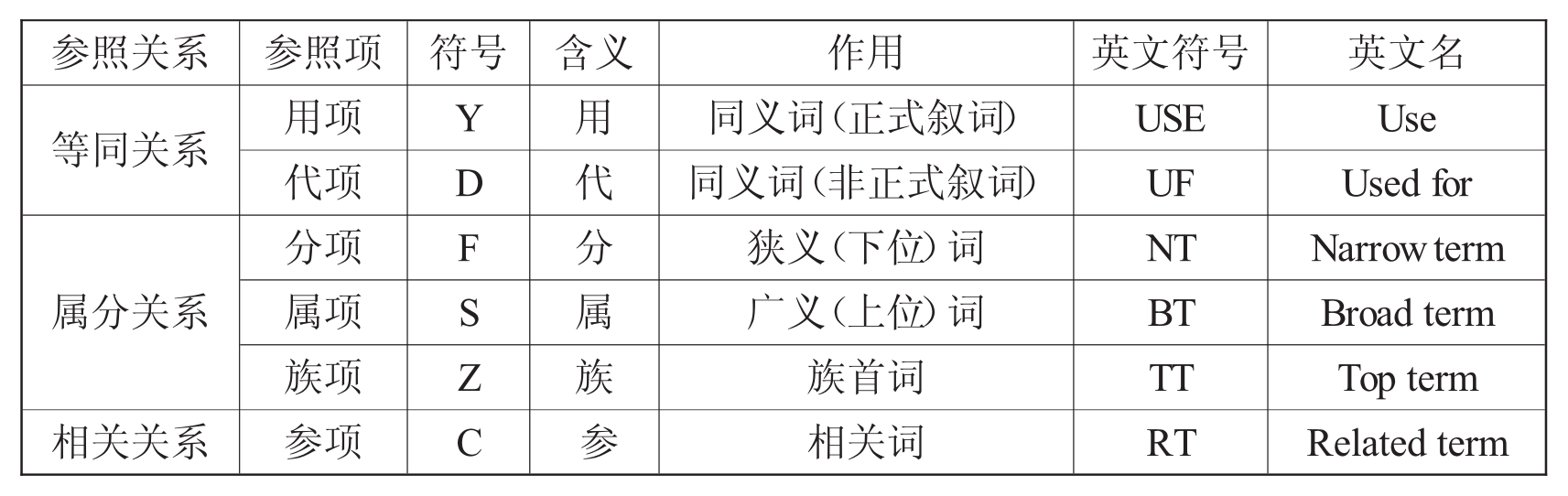
d.其他符号:
CC——磁带服务机构分类代码。
FC——输入数据库的全写形式分类代码。
DI——该词输入数据库的日期。
DT——该词输入数据库以前曾用词。
显见,在叙词之间,存在着各种语义关系,这些语义关系可由参照体系体现出来。通过参照体系,有助于读者合理选用叙词,可以扩大或缩小检索范围。
(4)叙词表
为了便于文献信息的标引和检索表示正确的标识,各国、各专业均编制有多种类型的叙词表。即有综合性和专业性两种形式。叙词表是准确查选叙词,提高文献信息标引质量和检索效率不可缺少的工具。它是由主表和辅表构成,主表内容最全,对每个叙词的著录也比较完备。辅表是为了方便主表使用而编制的各种辅助索引。国内使用较多较广的是《汉语主题词表》,国外也编制了有关综合性和专业性叙词表。现将各叙词表的组成部分和内容结构简要介绍如下:
a.字顺表(主表):在本表中,叙词和非叙词统一按字顺排列。叙词用黑体字表示,用于标引、检索文献信息;非叙词用浅体字表示,用于引导至叙词。每个款目除叙词外还著录有参照系统等项。
b.范畴表:又称叙词分类索引。它将全部叙词按其所属学科以及词义范畴,依次划分为若干大类、二级以及三级类。每个类目均被赋予一个范畴号。至于类目的排列,有的按类目名称的字顺排,有的则先按等级系统展开。所有叙词均按字顺分入最下一级的类目。范畴表有助于从学科、专业角度出发选用叙词。
c.族系表:又称等级索引或词族索引。所谓族系或词族,系指具有属分关系的一族叙词。每族中概念范围最广的叙词称为族首词。族系表即按各个族首词的字顺排列,在每个族首词下,按属分关系将该族叙词层层展开,全面反映各词所处的等级。族系表能加强叙词语言的族性检索功能,并便于检索者选用适当叙词以扩大或缩小检索范围。
d.双语种对照索引:如英汉对照索引。便于从一种文字查找另一种文字的叙词。
e.轮排表:又称轮排索引。它将叙词中的复合词,按其所包括的单词字顺轮排,便于从任一单词的轮排中迅速查获该单词的复合词。而《汉语主题词表》中无此索引。
f.专有叙词表:又称专用叙词表。如地区、人物、机构、产品等索引。这些索引一般与主表不重复,避免主表增幅,方便查寻。
应用叙词来标引和检索机读文献数据库中的文献信息,这是该语言最主要的用途,它也只在计算机检索中,才能发挥其最佳功能。
(5)叙词语言的特点
叙词语言是在分类语言、标题词语言、单元词语言、关键词语言的基础上发展起来的,因而它继承了它们的优点,克服其弊端,发展成科学的完善的检索语言。其特点如下:
a.吸取了标题词语言对科技语词的规范处理方法,吸取了标题词语言采用复合词组描述文献信息主题概念的方法使主题概念的表述更加符合现代科技述语;吸收标题词语言中标识系统采用的参照系统,并加以改进、完善,使叙词语言的参照系统更能反映叙词之间的相互关系。
b.吸取单元词语言的组配功能,并吸收组配分类语言的概念组配原理代替单元词语言的字面组配。而叙词的概念组配不仅能更准确地表达文献主题,且能避免虚假组配。
d.吸收了分类语言的基本原理来编制分类索引(范畴表)和等级索引(词族表),增强了族性检索能力。
综上所述,叙词语言具有直观性、专指性和组配性。特别是组配性,使之叙词具有优异的多维性检索的功能,不管论文文献的主题多么复杂,都能通过叙词的组配,进行极为有效的检索。
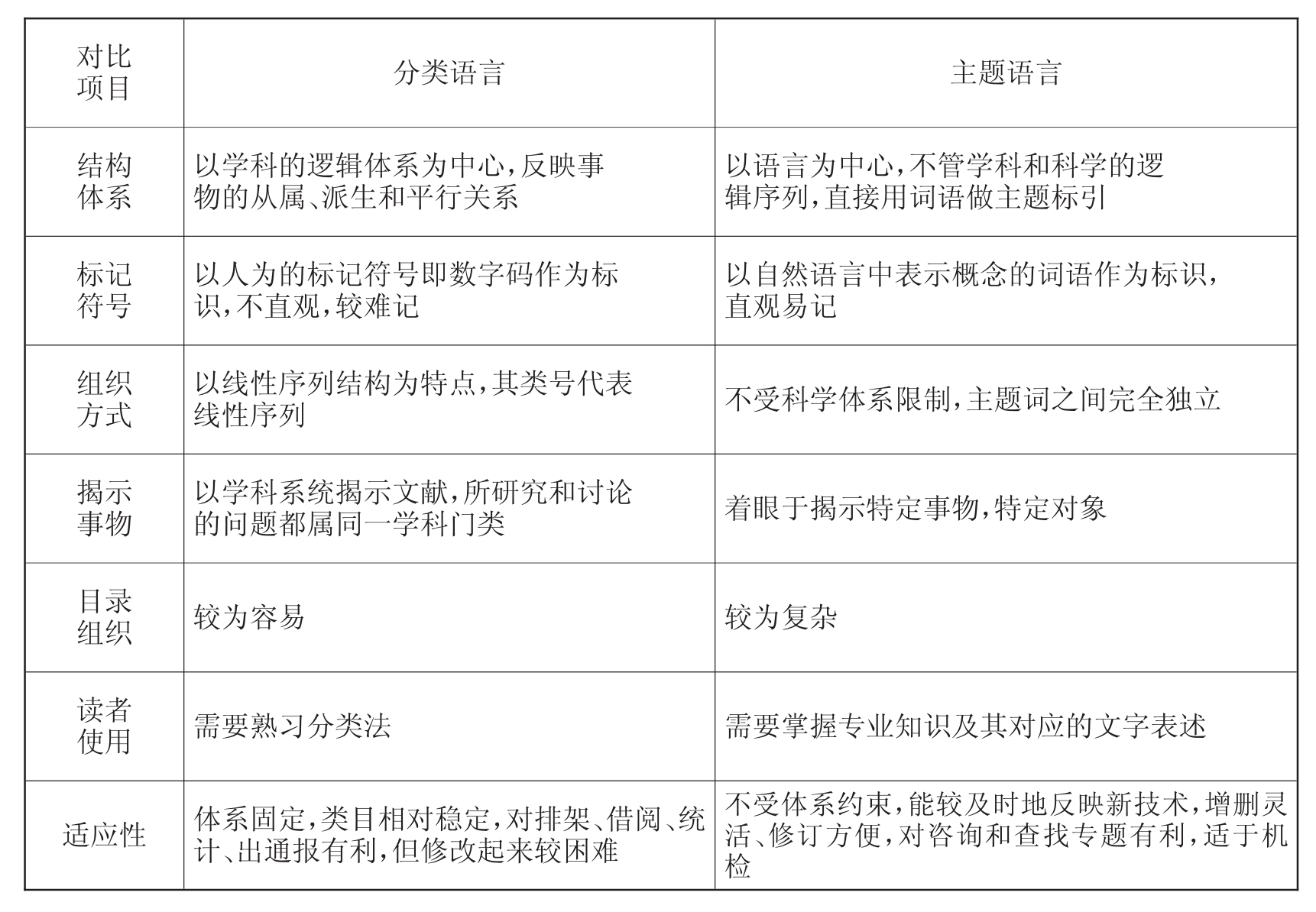
(6)分类语言、主题语言的比较
总括而论,无论是分类语言,还是主题语言,若单独用于存贮和检索文献,都不可避免地存在着较多缺陷。因此,国内外大型检索系统、大型数据库或检索工具中,都经常使用这两种语言,以便发挥其各自优势,满足检索者和广大用户的检索要求。
现将其分类语言和主题语言加以具体比较如下:(见下表)
分类语言与主题语言对比表
6 检索语言的发展
6.1 网络环境下的分类语言
分类法较全面客观地反映了知识全貌及其内在的逻辑关系,它体系结构的系统性、标识符号的通用性以及族性检索功能,是其他文献信息检索语言不具备,也无法取代的。而且,分类方法符合人类认识事物的逻辑思维方式。因此,在网络环境下,分类法仍具有强大的生命力,只是由于分类语言描述对象(信息资源)和利用对象(表引者和检索者)都发生了变化,分类语言也发生着变化。
6.1.1 更新分类法内容,适应网络环境
对于纸质文献来说,分类法主要应用于图书情报和档案机构,分类法处理的对象主要是正式出版物。而网络信息的发布打破了传统的出版程序的局限,不需要通过任何权威机构的审核与认可,信息内容更加丰富,数量更加庞大,信息的分类更加复杂。
在新的网络环境下,分类语言沿着两个方向继续发展。一是积极地调整传统分类法自身,满足信息资源的日益膨胀。2003年6月最新出的《杜威十进分类法》22版的电子版增加了大量印刷版中没有的类目,对004—006数据处理计算机科学、301—307社会学与人类学、340法律、510数学、540化学、610医药与健康、900历史与地理等作了重大的修订和补充。同时,一些网站采用了《杜威十进分类法》(DDC)、《国际十进分类法》(UDC)、《美国国会图书馆分类法》(LCC)以及其他的综合性分类法、专业分类法来对因特网资源进行组织和整理,为用户提供服务。但这些分类法为适应网络资源对原来的类目进行了必要的调整,对类目级别的深度进行了适当的控制。
分类语言发展的另一个方向是抛开传统的分类法,重新建立新的分类体系,即网络分类目录。它继承了传统分类法层层划分,从总到分逐级展开的基本思路,但不遵循以学科分类为基础的分类原则,不再使用分类号作为信息分类标识和依据,直接使用语词来形成网络分类目录。类目的设置是采用主题和各学科相结合的方式,类目体系在体现科学性的同时,更加注重追求实用、易用、通用和灵活等。
6.1.2 超文本技术的应用带来了分类体系的多维化
传统分类法的体系是以一种典型的线性结构来揭示类目之间的内在关系,表现出明显的单维性。尽管传统的分类法也试图采用组配方式或其他方式来改善类目之间简单的单维联系,但结果并不理想。超文本技术在分类语言中的应用,彻底改变了类目之间的线性关系,为分类语言的发展带来了新的契机。超文本技术允许我们在浏览文本信息的同时,随时可以选中其中的“热字”。热字往往是上下文关联的词汇或句子,通过选择热字可以跳转到其他的文本信息。超文本技术为多角度、多途径浏览和检索提供了技术支持,使分类法实现体系多维化有了可能。这样,就可以充分利用超文本技术,更好地揭示类目之间的多维关系。
新型的网络分类目录在类目划分标准、横向关系揭示和类目设置方面表现出明显的多维化趋势。网络分类目录打破了传统分类法划分标准唯一的限制,在同一类目下集中了依照主题对象、学科属性或资源类型划分的所有下属类目。同时,随着超文本技术的应用,对于多属性主题、交叉学科、边缘学科、总论和专论、地区和主题、资源形式和主题等横向关系的揭示会变得非常方便。而传统的分类法由于技术条件的限制,不利于充分地、客观地揭示和反映多维性的知识空间。技术的进步使得多维揭示、多角度设类成为现实,较好地解决了文献信息的集中和分散问题。
6.1.3 面向用户,分类语言更加简便易用
传统的分类是一种很专业的语言,主要应用于信息机构,这些机构的用户比较明确。而网络打破了信息获取与传递的地理障碍,使任何一个连入网络的人都有可能成为分类语言的使用者,用户的成分变得复杂多样,他们有着不同的教育背景、不同的知识结构和不同的年龄,从事着不同的职业。在传统信息环境下,人们往往依靠图书情报和档案机构工作人员的帮助来利用分类法,或者直接由信息工作人员来代替完成信息检索。网络让人们跨越了图书情报和档案机构这一中介,使终端用户成为分类法的直接使用者。这对分类语言的易用性提出了挑战。因而,网络环境下的分类法要从用户的角度出发,关注普通用户的一般思维方式、检索习惯和需求等特点,按照通用的思维方式、检索特点来调整分类法的知识体系、分类标准等,在强调类表的科学性和专业性的同时,也考虑它的实用性和包容性,关心用户使用的感受,提升分类语言的易用性,便于用户掌握和利用。
6.2 网络环境下的主题语言
主题法使用语词对信息进行揭示和组织,直接用语词表标识信息内容,可以较好地满足用户的特性检索需求,主题语言在网络环境下仍然是一种重要的检索语言。因特网的普及和网络信息资源的飞速增长对主题语言的发展产生了较大的影响,随着数字化信息资源的增多,数据库成为一种非常重要的信息组织和存储方式,主题语言作为一种语词标识系统,在数据库检索中将得到广泛的应用,主题检索是数据库检索的一种重要途径。许多数据库都提供有词表,包括各种主题词表、关键词表或禁用词表等,用主题语言进行检索有较高的查准率和查全率。
主题语言在网络信息资源的检索中表现为:
(1)传统词表在网络信息资源组织与检索中的应用。如一些网络信息检索系统采用了《美国国会图书馆主题词表》、《医学主题表》等,但这种情况并不多。
(2)关键词语言在网络搜索引擎的广泛使用。关键词语言在组织网络信息资源时具有一定的优势,关键词基本上是自然语言,造词灵活、广泛、适应性强,能够适应不同层次用户进行网络信息资源的检索,最大限度地保证网络信息标引和检索的一致性。
6.3 自然语言的应用
随着计算机技术的发展、计算机信息检索系统的广泛应用,自然语言在信息检索领域的应用开始盛行起来。传统的采用受控语言(人工语言)的信息检索系统要求检索者必须具备一定的检索理论和实践技能,熟练系统的检索功能和操作命令,掌握检索语言的特点及有关的检索策略与检索技巧等方面的知识。随着信息资源的海量化和信息需求的不断扩大,越来越多的非专业人员开始涉及信息检索领域,人们开始不满意传统受控语言的严格规范性,渴望信息检索更加简洁和易用。自然语言处理技术在信息检索领域的应用带来了一场大变革,促进了新的自然语言检索方式的产生和发展。
6.3.1 概述
自然语言指不经加工和规范的语言,自然语言直接取自文献本身,它包含词、词组或句子,没有繁琐规则的约束,未添加任何人工的东西。
自然语言有许多人工语言没有的优点:
(1)自然语言检索方便,不受人工语言的种种限制,不需要复杂的检索规则,用户能够较快掌握,易用性强。
(2)自然语言采用从文献中直接抽词的方式,避免了人工标引过程中的失真现象。全文检索技术的发展在很大程度上推进了自然语言检索的发展。目前,一些数据库和搜索引擎采用了自然语言检索,允许用户直接采用自然语言进行检索,用户可以输入类似“when did Wed searching?”等问题。
(3)自然语言很容易吸纳新的词语、概念。采用自然语言检索新出现的事物可以获得较好的检索效果,可直接使用这一新词作为检索入口,不像传统的人工语言那样,必须将该词殚思极虑地转换成另一规范词,再进行检索。
自然语言信息检索系统和受控语言系统相比较有明显的不同。受控语言信息检索系统是在文献信息和用户信息需求输入系统之前进行控制,控制的工具是人工编制的词表或分类表,而且需要对检索的课题进行主观的思考和分析,检索结果的优劣在很大程度上取决于用户对规范化词表或分类表的掌握程度及经验技巧。文献信息的输入(前控)和检索提问的输入(后控)都采用同一词表,前控和后控的程度相等。但自然语言检索系统主要是在输入系统之后,在系统内部进行控制,文献信息输入时基本上不作处理,而主要依赖后控,就是将自然语言转换成系统的提问,并对有同义、近义、相关等关系的词进行组织。同时,自然语言检索系统与计算机自动标引和自动分词等技术密切地联系在一起。
虽然自然语言的使用增加了信息检索系统和用户的友好程度,但它还是存在着一定的不足,自然语言的表达具有不可避免的词义模糊性,易造成主题相关的信息分散,也难以表现词和词之间的关系,从而影响检索系统的检索效率。因此,如果要想获得满意的检索结果,就应该对自然语言实施一定的控制,建立后控词表是一种比较有效的解决方法。
6.3.2 后控词表
后控词表专门应用于自然语言检索系统,主要是在检索输出时对同义词以及语义句法上的相关词进行控制,来实现自动扩检和转换的功能,也有人称它为只供检索的词表。后控词表主要是对自然语言中的等同关系、等级关系和大部分相关关系进行控制和提示,它是一个动态词表,可以及时将新概念和新术语加入词表中。
后控词表只对系统的输出阶段进行控制,它的控制处理相对受控语言检索系统比较简单,不需要标引人员花费很长时间去分析文献的主题概念,以选用合适的检索词进行标引、归类;用户也不必花太多的精力分析检索要求,考虑用符号标准的检索语言来表达自己的信息要求。
后控词表展现了比较完整的语义关系,用户通过浏览词表选用检索词,极大地减轻了构造检索策略的负担,提高了检索速度,节约了检索时间。后控词表把自然语言和受控语言相结合,对于提高自然语言检索系统的查全率和查准率具有重要的意义,为用户准确选词、精确检索、扩检和缩检、改变检索范围、进行相关检索提供了方便。
后控词表直接面对用户,完全采用自然语言,用户不需要经过专门的训练就可以很方便地利用,便于用户与系统的交流。
目前,对后控词表展开了一系列的研究,并且取得了一定的成果,较有代表性的有美国国防技术信息中心(DTIC)科技报告全文检索系统(http://www.dtci.mil)、美国教育资源信息中心(ERIC)数据库全文检索系统(http://www.ericae.net)、生物科学情报社(BIOSIS)的检索系统(http://www.biosis.org)等检索系统的后控词表。分别介绍如下:
(1)美国国防技术信息中心(DTIC)科技报告全文检索系统
DTIC(Defense Technical Information Center)主要为美国国防技术的研究、开发、使用管理以及美国政府机构及其合作者提供有关国防技术方面的信息(http://www.dic.mil)。随着Internet的发展,DTIC也开始为全世界用户提供种类丰富的WWW资源服务。
目前,该机构提供的最为普遍的WWW站点是公众科技信息网络(the Scientific and Technical Information Network,缩写为STINET)。用户通过该网络可以查询DTIC收录的1985年以来的科技报告数据库。STINET的词表采用类似叙词表的结构,每个词条都有其相应的用(USE)、代(UF)、上位词(BT)、下位词(NT)和相关词(RT)等参照体系。并且同样采用清晰的树形结构排列。但是,该系统只为用户提供了词表的浏览和选择功能,并未提供词表的添加和修改功能。仅仅在检索方面,为用户的选词提供了帮助,减轻了用户负担。用户却不能直接添加新的检索词和新的词间关系,无法及时地反映新概念、新术语,这必然会造成词表使用效率的下降,进而影响检索效率。况且,检索系统没有提供自动向检索提问式增加检索词和自动构造检索提问式的功能,使得选词和构造检索式相分离,增加了检索提问构造的复杂性。
总的来说,DTIC提供的全文和词表相联系的检索系统易用性较好,使用方便。词表系统结构合理,体系清晰,具备了后控词表的主要功能,是一个较为理想的网上基于词表的全文检索系统。
(2)美国教育资源信息中心(ERIC)数据库全文检索系统
美国教育资源信息中心(ERIC)数据库全文检索系统,对后控词表作进一步说明和解释。ERIC(Education Resources Information Center)是美国国家教育部、教育研究和发展署的一个联邦基金项目(http://www.ericae.net/scripts/ewiz/amainz.asp)。主要收录全球范围的有关教育方面的文献资料,并且为全世界的教育研究与工作者提供数据库信息。
ERIC数据库检索系统提供了词表辅助检索功能。即后控词表。该词表系统参照体系比较完善,包括常用的参照(USE、UF、RT、NT、BT),主要目的是帮助用户确定合适的检索用词,并方便地进行扩检和缩检。
ERIC数据库检索系统不仅将全文检索功能与词表的浏览和检索置于同一界面中,而且提供了向检索式自动添加检索词的功能。其功能多样,界面排列合理,易用性好。其不足之处与STINET的词表检索系统相同,即没有向用户提供词表的更新、维护和词表的自学习功能,无法满足用户对于新术语、新概念检索的要求。但是,从实际使用的情况来看,ERIC网上词表全文检索系统是一个让用户比较满意的后控词表检索系统。
(3)生物科学情报社(BIOSIS)提供的词表检索系统
BIOSIS(BioSciences Information Service)着重收录世界范围的生物学和医学方面的文献(http://www.biosis.org/htmls/ht-zrcd/thesaurus)。其中,动物学纪事ZR(Zoological Record)是很有特色的一个数据库产品。
ZR始建于1864年,最初由不列颠博物馆和英国动物协会的一批科学家共同创建,一直受到生物学界的普遍重视。BIOSIS于1980年作为其合作伙伴,共同出版ZR。其数据光盘版收录了从115卷至今的所有的内容,并且提供了独一无二的词表检索系统,用于精确地选择合适的检索用词。
ZR提供了两种词表系统:一种是主题词表(subject thesaurus),包括动物学、地理和古生物方面的词条以及相应的注释,按照生物等级体系排列。一种是生物体系词表(systematic thesaurus),按照生物分类体系排列,主要用于对生物名称的英文和拉丁文的对照检索。
主题词表允许用户从生物分类体系和主题等级体系入手,根据检索要求,进行泛指词和专指词的选择,并提供3种途径便于用户获取所需的词条信息:置换词和置换索引目录(The List of Permuted Terms or Permuted Index)、词条基本和详细信息(The Selected Term Details or Term Information)、扩展树形体系视图(The Expanded Trees View or Full Tree View)。
——置换词和置换索引目录。该目录主要进行相关词和同义词的参照,按照每个词条的字母顺序排列,用“see”进行指代。其格式如下:
FOLDS
Mantle Folds FOLKLORE
Mythologyfolklore and religion
FOOD
see
Ad libitumfood capacity
此目录将同一主题的词条集中在一起,提供同义词参照,为用户定位确切的检索词及其相关词提供帮助。
——词条基本和详细信息。这部分是按生物分类等级排列的术语词表,包括标题(用户所选的词)、上下位词的等级树、相关词、范围注释和“代”注释。
如:词条Diet(食物)内容如下所示:
标题为:Diet
SCOPE NOTE:Type offood eaten.For dietary——
RELATEDTERM(S)Diet in captivity;Feeding——
TREES:HIERARCHICALDISPLAYOF IMMEDIATE——
TREE 1 of1:Nutrition
Diet
Bacterial diet
……
它所提供的词条相关信息,可以帮助用户确认所选词是否正确,并得到该词的上、下位词和相关词,进行相应的扩检和缩检。
——扩展树形体系视图。以等级结构体系显示用户所选词的所有上、下位词,并用缩进树形显示词间关系。位于最左边的词是最为宽泛的上位词,该词的等级值最小;位于最右边的词是最为专指的下位词,该词的等级值最大。其结构如下所示:
假如所选的词为Habitat
TREE 1:Habitat
Level
1..Habitat
2......Marine habitat
4..............Beach
3..........Surf
现具体介绍利用其词表系统进行检索的步骤:①输入要检索的词条;②从置换词和置换索引目录列表中选择所需的检索词;③在仔细阅读关于该词条的细节说明和信息后,选择检索类型;④进行检索。
与其他全文检索词表系统相比较,ZR提供的词表系统包括了两种词表,适应动物学文献的分类和检索。其中主题词表系统又包括3种类型的目录体系,为用户检索生物学方面的词条提供了方便的检索途径。
但是,对整个全文检索系统而言,它的词表体系和全文检索是相分离的。词表仅仅作为一个简单的系统而存在。虽然它自身强调该词表是专为用户检索提供帮助的词表,但是从其使用来看,并不是严格意义上的供全文检索使用的后控制词表。