大学信息技术基础
-
1.1扉页
-
1.2目录
-
1.3前 言
-
1.4第1章 信息科学与计算机
-
1.4.11.1 初识计算机
-
1.4.21.2 计算机进制与信息编码
-
1.4.31.3 计算机系统与常用设备
-
1.4.41.4 学会使用键盘
-
1.4.51.5 计算机的维护与安全
-
1.5第2章 计算机操作系统——Windows7
-
1.5.12.1 初识Windows7
-
1.5.22.2 Windows7基本操作
-
1.5.32.3 资源管理
-
1.5.42.4 控制面板
-
1.5.52.5 Windows7应用程序工具
-
1.6第3章 文字处理——Word2010
-
1.6.13.1 Word2010初步使用
-
1.6.23.2 文档的基本排版
-
1.6.33.3 文档的高级排版
-
1.6.43.4 图文混排
-
1.6.53.5 页面设置与打印
-
1.7第4章 数据处理——Excel2010
-
1.7.14.1 Excel2010初步使用
-
1.7.24.2 工作表格式化
-
1.7.34.3 公式和函数
-
1.7.44.4 数据管理
-
1.7.54.5 图表操作
-
1.7.64.6 页面设置与打印
-
1.7.74.7 Excel的高级应用
-
1.8第5章 演示文稿制作——Power Point2010
-
1.8.15.1 Power Point2010基础——简单演示文稿制作
-
1.8.25.2 制作幻灯片
-
1.8.35.3 演示文稿的外观设计
-
1.8.45.4 演示文稿动画设置与放映
-
1.9第6章 计算机网络与Internet应用
-
1.9.16.1 计算机网络
-
1.9.26.2 Internet的应用
-
1.10第7章 多媒体应用技术
-
1.10.17.1 多媒体技术概述
-
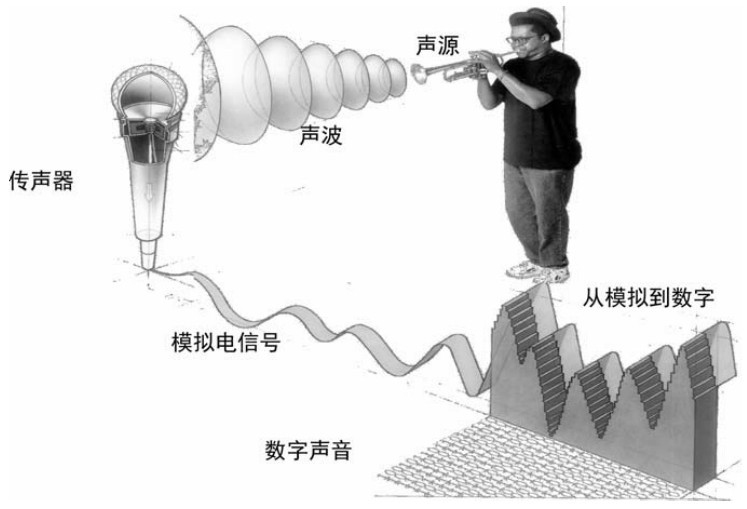
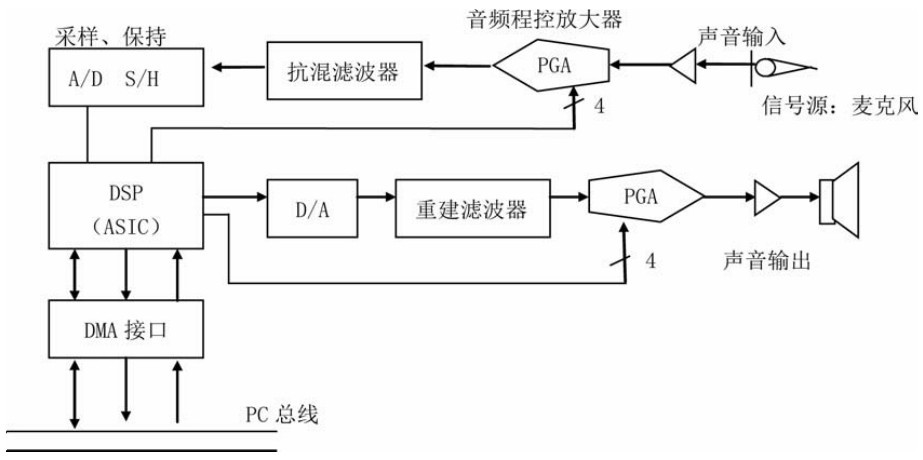
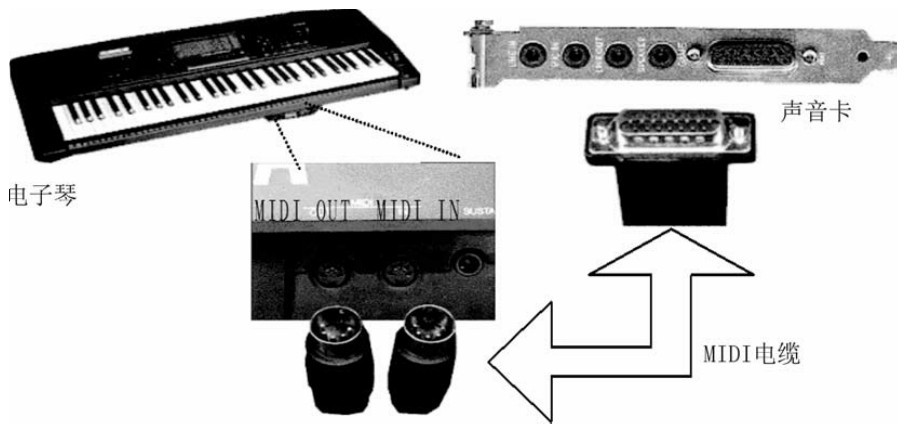
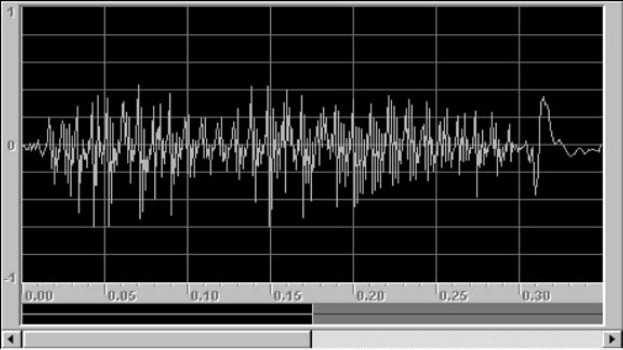
1.10.27.2 音频信息处理
-
1.10.37.3 图像信息处理
-
1.10.47.4 动画处理基础
-
1.10.57.5 视频处理基础
-
1.10.67.6 多媒体应用系统制作
-
1.11第8章 数据库技术及应用基础
-
1.11.18.1 基本概念
-
1.11.28.2 数据模型
-
1.11.38.3 数据库技术的发展历程和发展方向
-
1.11.48.4 常用数据库开发平台
-
1.11.58.5 关系数据库标准语言SQL
-
1.11.68.6 数据库技术应用实例
-
1.12参考文献