人体基因的重大发现
全色盲基因
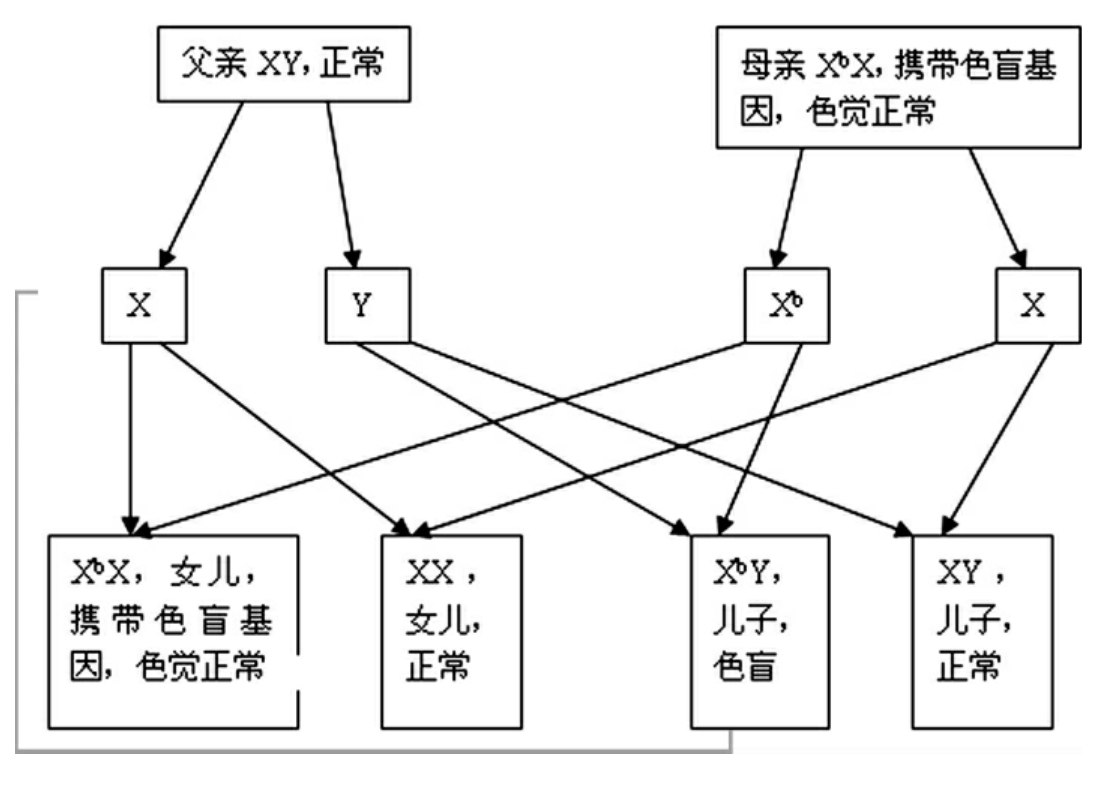
色盲遗传规律
20世纪70年代科学家们发现,在太平洋的一个小岛上,居住着一群奇特的居民。这个岛属于密克罗尼西亚联邦,岛上每20个人中就有一名全色盲者,而在世界范围内,则是每50000人中才有一名色盲患者。这个岛上的色盲人与一般的色盲人不同,他们不仅不能正确识别颜色,而且完全看不见颜色。他们看这个世界,就像看黑白电视机一样。
这一奇怪而有趣的现象,吸引了科学家们的注意。经过30年的探索,科学家们终于找到了引起全色盲的基因。尽管目前还没有找到治愈这种病的办法,但是科学家们可以帮助人们避免出生色盲患儿。由于先天性全色盲症一般属于染色体隐性遗传,同代发病率为24.4%。根据这种病的遗传规律,科学家们就可以告诉岛上居民,应禁止近亲结婚,提倡与岛外居民通婚,尽量避免引发孩子再患全色盲的危险。
先天性近视眼基因
原上海医科大学的一位教授,利用小鼠模型进行数量遗传和多基因定位研究。他发现,先天性近视眼患者的眼球比正常人大。为寻找原因,他利用小鼠模型对此问题进行了深入研究。经过近一年的研究,他首次发现了两个控制小鼠眼球大小的基因:eye1和eye2。其中,eye1位于第5号染色体上,eye2位于第7号染色体上。研究结果表明,有eye1和eye2基因的小鼠眼球比没有这2个基因的小鼠的眼球平均增重0.5毫克。由此说明,这2个基因的有无决定了小鼠眼球的大小,有这2个基因眼球就大,反之则小。虽然小鼠模型不能完全等同于人,但小鼠模型和人很相似,所以这为寻找先天性近视眼的“元凶”提供了强有力的实验依据。
此外,据近来报道,科学家们已发现控制人类眼睛形成的基因。这个基因起名叫Pax6。如果Pax6基因出现异常,将影响眼睛的正常形成。
与心血管病有关的基因
以哥斯达黎加大学教授为首的研究小组,经过5年的研究发现,人类的心血管病同人种的遗传基因有一定关系。拉美土著人种比纯种欧洲人更易患心血管病。他们通过对两类人种遗传基因所表达的凝血酶原、类半胱氨酸等心血管变异因素的对比分析证明,类半胱氨酸的增多能损害血管内皮,引发血栓疾病,而凝血酶原偏低则是引起血管出血症的重要原因。这个小组的研究结果显示,拉美土著人遗传基因所表达的类半胱氨酸及凝血酶原含量同欧洲人相比差异甚大,如哥斯达黎加医院血库中的血液类半胱氨酸含量高达68.3%;哥斯达黎加人凝血酶原的含量为零,而德国人的含量较高。因此,心血管病已成为哥斯达黎加人健康最主要的杀手之一。
加拿大的科学家经过6年的实验,终于找到了一种心脏病致病基因,从而为预防和治疗人类心脏病带来了希望。
加拿大安大略癌症研究所的一个科研小组在实验中发现,带有一种叫做P56LCK基因的人容易患心脏病。这种基因能够通过感冒病毒进入心脏,导致心肌坏死。为了证实这一推测,研究人员在6年时间里从人体内逐步分离和确定出P56LCK基因,并在白鼠身上进行实验。结果发现,一旦注入感冒病毒时,体内不存在P56LCK基因的白鼠的心肌遭到严重损害,它们多数死亡,其余则患上慢性心脏病。因此,这进一步证明P56LCK基因是一种心脏病致病基因。
致癌基因与抑癌基因
经过科学家们的不懈努力,迄今发现癌基因有2种类型:一种是病毒癌基因,来自于病毒;另一种是细胞癌基因,或称原癌基因,来自于宿主细胞。
关于病毒癌基因,早在1911年专家茹斯从病鸡身上分离到鸡的肉瘤病毒,他将这种病毒注入幼鸡体内,几天以后鸡就会出现肉眼可见的纤维肉瘤;如果用这种病毒在体外感染胚胎或纤维细胞,24小时就可以诱发出表型转化,出现肉瘤。
近年来的研究已经证明,白血癌病毒和鸡的肉瘤病毒都是RNA肿瘤病毒,都具有致癌基因。例如,鸡的肉瘤病毒,具有癌基因V-SRC,它编码一种蛋白质激酶,能使细胞质膜上的蛋白质磷酸化,促进细胞的无限生长,从而形成肿瘤。此外,人们还发现一些致癌性DNA病毒,如乳头瘤病毒、多瘤病毒和猴空泡样病毒等均有致癌作用。据研究,人类的恶性肿瘤约有5%是由病毒引起的。
细胞癌基因是在1969年由美国学者希布纳和托达罗首先提出的。他们认为在所有细胞中都包含致癌病毒的全部遗传信息,这些遗传信息代代相传,其中与致癌有关的信息称为癌基因。在通常情况下,癌基因处于被阻遏状态,只有当细胞内有关的调节机制遭到破坏的情况下癌基因才表达,从而导致细胞发生癌变。到了20世纪80年代初,由于重组DNA技术和哺乳动物细胞转化技术的发展,人们陆续发现在脊椎动物(包括人类在内)的细胞中都有类似病毒癌基因的同源DNA顺序,这些顺序称为原癌基因或细胞癌基因,它来源于正常的细胞基因。原癌基因是细胞固有的基因成分,正常情况下它不仅对细胞无害,而且具有重要的生理功能。当吸烟、病毒感染、紫外线照射时,原癌基因就有一种突变或异常的形式表达,此时原癌基因就成了癌基因。
癌细胞
无独有偶,人们近年来又发现有抑癌基因。
意大利米兰欧洲肿瘤研究所的一个研究小组发现,一种被称为PML的基因能阻止肿瘤细胞的生成。进一步研究结果显示,当一个细胞出现变异迹象时,PML基因很快就会“感觉”,并被激活,继而它又会作用于P19和P53两种基因,这两种基因有抑制肿瘤细胞形成的功能。因此,在PML基因产物增加时,基因P53和P19被激活,肿瘤细胞随之死亡。
从以上我们可以看出,虽然目前科学家们还没有找到彻底治愈癌症的有效方法,但人们已有了许多预防癌症的有效措施。
肥胖基因和苗条蛋白
现在人们的生活水平提高了,许多人都在注意减肥。人们过去通常认为肥胖主要与饮食和环境因素有关系。其实,肥胖是一个复杂的生理和病理过程,与多种严重危害人类健康的疾病有密切关系。近几年来,人们认识到肥胖也与基因有关系。
我们经常会遇到这样的现象:为什么吃同样的东西,有些人胖,有些人瘦呢?这暗示了可能与不同人的遗传基因差别有关。通过对小鼠的研究,科学家们发现5种单基因突变可以引起小鼠遗传性肥胖。其中最受重视的是肥胖基因,命名为Ob基因。1994年底弗里德曼成功克隆了小鼠的Ob基因,并确定了其所编码的蛋白质。Ob基因位于小鼠的第6对染色体上,它仅在白色脂肪组织中得到表达,编码的蛋白可作用于下丘脑,产生抑制摄食、减轻肥胖、减少体重的效应。所以有人称这种蛋白为“苗条蛋白”或“瘦小素”。如果把“瘦小素”移植到老鼠身上验证,就会发现老鼠体重会下降12%,这说明人体如果有了“瘦小素”以后,就有可能既可满足食欲,又不会长胖。但在人身上的作用究竟如何呢?这还需要进一步的试验。Ob基因既然编码“瘦小素”,又为什么叫肥胖基因呢?因为Ob基因发生突变或者“瘦小素”发生变化以后,都能引起小鼠或大鼠发生肥胖。至于人类的肥胖症是否与肥胖基因突变有关,尚待科学家们进一步的研究。
人类性格基因
我们知道,有的人性格开朗,有的人沉闷,有的人爱生气……人类性格的这种差别,根源到底是什么呢?有人会说,这是由遗传和环境决定的。但是,这又是怎么决定的呢?一般的观点是,人的外貌是由遗传决定的,而人的性格则是由环境所造成的。然而,我们不禁要问,难道人的外貌就没有环境的作用?难道人的性格和遗传就没有任何关系吗?
近年来,科学家们在寻找人类性格基因方面迈出了重要一步。在美国、以色列等国及欧洲就发现有15%以上的人具有暴躁、好奇、冲动、好走极端等性格基因,发现这种基因后,科学家们就可以对症治疗或设法缓解病人的症状了。性格基因最突出的是自杀基因,这个基因与家族遗传有关,比如作家海明威是自杀的,其父母、兄弟也都是自杀的。
科学家们还发现了“忠诚基因”。美国埃默尔大学的科学家们最近发现了一种与普通老鼠不同的大草原田鼠。这种田鼠对配偶极为忠诚,它们全都对“妻子”从一而终,这引起了科学家们的注意。他们通过DNA分析,发现大草原田鼠的DNA链中有一种基因,专门负责使它们一辈子只忠诚一个配偶,并且对孩子悉心照料。进一步研究,科学家们把这种基因注入普通老鼠体内,结果发现,普通老鼠也具备了大草原田鼠的这种特点。
科学家们对首次发现这种基因十分兴奋,因为他们不但在老鼠身上取得了实验成功,而且在灵长类动物身上也很奏效。这足以证明在人体上也有同样的情况发生。因此,从理论上来说,人的性格可以先天定。
绘制生命图谱
人类基因组计划就是“解读”人的基因组上的所有基因。由于我们人类的基因组是23条染色体,但因为X与Y染色体不同源,所以人类基因组计划的最终目的就是分析这24条(22条常染色体和X、Y性染色体)DNA分子中4种碱基的排列顺序,并了解它们的功能。但是,人类基因组共含有3×109个碱基对,24条DNA分子连接起来约1米多长。这么长的DNA分子,就像要搞清“长城”上的每块“砖头”(碱基)一样,要把如此巨大的DNA分子的碱基序列全部准确无误地读出来,那将是一个非常困难的任务。
为了解决测定人类基因组全序列这一难题,科学家们采取了两步走的策略。第一步叫做“作图”;第二步就是“测序”。“作图”就是“基因定位”,即确定每个基因在染色体上的位置及其碱基序列。如果把基因组比作是哥伦布刚刚发现的美洲大陆,作图就是绘制新大陆的地图。我们都知道地图有很多种,有自然区划图、行政区划图等等,每种地图的用途不同,其比例标尺与精细程度也不同。绘制人类基因组图谱,也由于对染色体描写程度的不同,因而其显示的作用也有区别,对科学家们来说需要绘制四张基因图。因此,人类基因组计划分2个阶段进行,第一阶段叫DNA序列前计划,主要是绘制遗传图谱和物理图谱;第二阶段叫DNA序列计划,主要是“测序”,绘制序列图谱和转录图谱。序列图是搞清人类基因组图谱最基础的核心内容,这张图谱最重要,也是最“值钱”的一张图。
遗传图——标记DNA分子的基因位点
在电视剧里常常播放这样的故事:人们中间流传着一批宝藏埋藏在某个地方,有些人想得到它,那最需要的是什么呢?当然是藏宝图了,因为有了这张藏宝图,就可以知道宝藏放在什么地方,以及寻找宝藏的路线。因此,人们为了获取藏宝图而争斗不已。在基因组的研究中,遗传图谱就相当于基因组的“藏宝图”,这张“地图”标定得越细,对基因组中的角角落落就知道得越清楚,也就越容易找到所要的“宝藏”——基因。
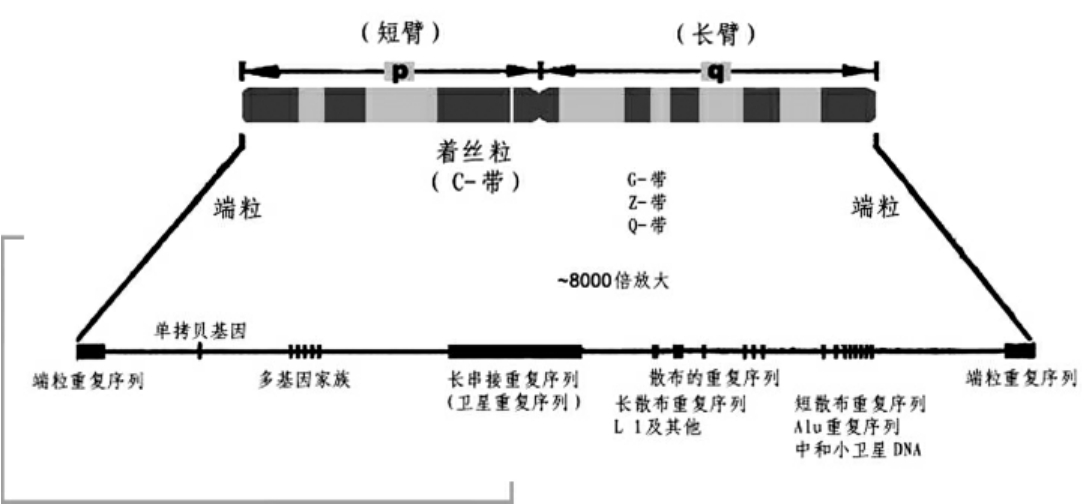
遗传图
遗传图谱也叫连锁图谱或遗传连锁图谱。它是以某个遗传位点具有的等位基因作为遗传标记,以此为“路标”,以遗传学上的距离(也叫遗传距离,其单位以厘摩表示),为“路标”之间的距离。遗传距离是以两个遗传位点之间进行交换,发生的基因重组的百分率来确定时,重组率为1%,即1个厘摩。根据遗传距离就可以绘制出基因在染色体上的遗传图谱。在前面介绍的连锁遗传中我们曾提到,在同一条染色体上的2个基因,它们发生互换和重组的机率越大,说明它们之间的遗传距离越远;相反,遗传距离就越近。遗传距离不是一个具体的计量单位,而是人们设想的相对距离单位,以此作为遗传标记的距离。我们知道,在人类基因中,有些基因是稳定遗传的,目前已搞清它们在某条染色体上所在的位置,这样可以利用这个基因作为标记基因的位点。如ABO血型基因、Rh血型基因和人类白细胞抗原(HLA)基因等都可作为标记基因位点。然后,利用这些基因检测与其他基因是否有连锁关系,如果有连锁关系,说明它们在一条染色体上,再根据重组率确定它们之间的遗传距离,这样便可以绘出染色体遗传图。
不难看出,建立人类遗传图的关键是要有足够多的遗传标记。但目前人们所知的这样的遗传标记信息量不足,而人类的基因组又很大,不能像做细菌的遗传图那样,仅仅根据有限的遗传标记就可以完成,这样,就限制了人类基因组的遗传分析工作。所幸的是随着DNA重组技术的发展,科学家们开展了以限制性片段长度多态性的分子标记工作,并已实现了遗传分析的自动化。1991年,遗传标记开始了用自动化操作。到了1994年,美国麻省理工学院的科学家们一天已经可以对基因组进行15万个碱基对的分析,这就大大提高了绘制遗传图谱的速度。至1996年初,所建立的遗传图已含有6000多个遗传标记,平均分辨率即两个遗传标记间的平均距离为0.7厘摩。过去人们一直认为,很难绘制成人类自身的遗传图,但今天人类终于有了自己的一张较为详尽的遗传图。想一想,有6000多个遗传标记作为“路标”,把基因组分成6000多个区域,只要以连锁分析的方法,找到某一表现型的基因与其中一种遗传标记邻近的证据,就可以把这一基因定位于这一标记所界定的区域内。这样,如果想确定与某种已知疾病有关的基因,即可以根据决定疾病性状的位点与选定的遗传标记之间的遗传距离,来确定与疾病相关的基因在基因组中的位置。
物理图——确定DNA分子的“里程碑”
物理图是基因组计划的第二张图。物理图是一种以“物理标记”作为“路标”,确定基因在DNA分子上的具体位置的基因图谱。它与遗传图不同的是把基因在染色体上的位置再标记到DNA分子上。物理图的制作目标与遗传图相似,只是它们所选择的“路标”和“图距”的单位有所不同。物理图的“路标”是STS(序列标签位点)。每个STS约有300个碱基的长度,在整个基因图组中仅仅出现一次。“图距”的单位是bp(1bp即表示一个碱基对)、kb(1kb=1000bp)和Mb(1Mb=1000000bp)。物理图与遗传图相互参照就可以把遗传学的信息转化为物理学信息。如遗传图某一区的大小为多少厘摩可以具体折算物理图为某一区域大小为多少Mb。绘制物理图的“路标”需要筛选大量的物理标记以及进行大量复杂和繁琐的分析。据估算,绘制物理图谱要进行1500万个分析,一个研究人员即便每周连续工作7天也要工作几百年。幸运的是,现在有了一种大型仪器,可同时进行15万个分析,研究者仅用1年的时间就能筛选出足够的遗传标记。1995年,第一张被称做STS为物理标记的物理图谱问世,它包括了94%的基因组的15000多个标记位点,平均间距为200kb(这就是所谓的分辨率)。这样,物理图就把人类庞大的基因组分成具有界标的15000个小区域。
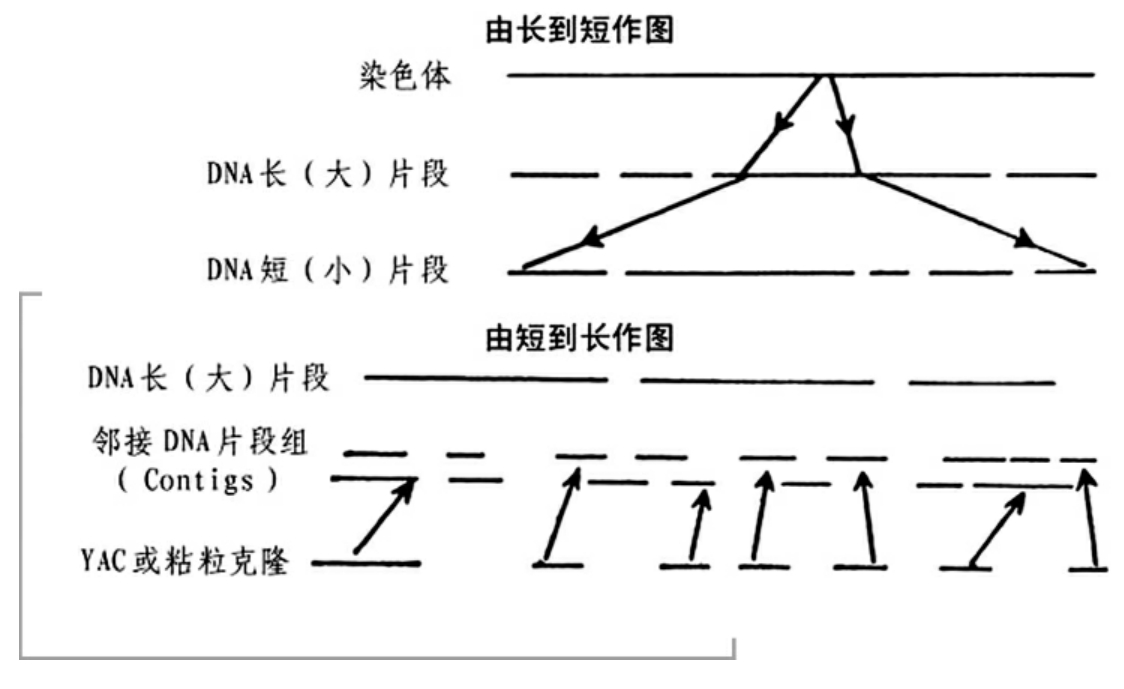
物理图
那么,物理图谱是怎么绘制的呢?
有两项技术为绘制精细的染色体物理图谱奠定了基础。第一项是利用流式细胞仪进行染色体的分离。处在细胞分裂时期的染色体是一种致密和稳定的形体结构,在温和条件下使细胞破裂,释放出完整的染色体。当染色体流过激光检测器时,按照其DNA含量的不同,可以把每条染色体分开收集起来,这样,就可以给每条染色体制作一个基因文库。第二项技术是体细胞杂交,即把人的细胞与小鼠的肿瘤细胞融合在一起。这种“杂种细胞”在培养的过程中,由于细胞分裂时人的染色体分裂慢,鼠的染色体分裂快,于是逐步把人染色体排斥掉,最后只剩下一条人染色体时细胞就比较稳定了。把这种带有某一条人的染色体的杂种细胞进行传代培养,就得到一系列细胞系,每个细胞多一条人的染色体。这样的细胞系对于把某个基因或DNA片段迅速定位到染色体上是非常重要的。例如,当杂种细胞保留了人类第1号染色体时,能够形成肽酶C;如果丢了第1号染色体,则不能形成肽酶C。所以,可以认为控制肽酶C合成的基因位于第1号染色体上。
人们采用上述方法分别得到每一条染色体以后,便可以提取出每条染色体的DNA分子,这样就为DNA分析奠定了基础。
由于染色体的DNA分子很长,所以先用限制性内切酶切割成一定长度的DNA片段,然后对每一DNA片段再进行分析。因此在进行DNA序列分析之前,先绘制一种分辨率比较低的物理图谱——“大尺度限制性图谱”。用识别位点出现频率很低的限制性内切酶对染色体DNA进行切割,得到大片段DNA,用脉冲电泳进行分离,然后再把这些片段在染色体上的位置排出来,就会得到一系列由限制性内切酶位点分布和排列特征的染色体DNA的物理图谱。以上就是物理图谱的另一含义——“铺路轨”。这种图谱比较粗略,不能对特定基因进行精细定位。依据这种图谱可以把特定的DNA序列片段定位到100kb到1Mb的区域。
近年来,科学家们又发现了一种绘制精细物理图谱的方法。他们利用酵母人工染色体和细菌人工染色体,可以构建出每个克隆携带1Mb染色体DNA片段的文库。所谓“文库”即包括染色体上所有DNA片段的无性繁殖(即克隆)系,它含有整个染色体的遗传信息。这样,每个染色体只需要少量克隆就可以覆盖全部DNA分子。用一种短而独特的DNA序列片段(STS)作为分子标记,这种序列标记的位点可以用来把基因文库里的克隆按照其携带的染色体DNA片段在染色体上的实际位置进行排序。对这些大片段(1Mb)还可以进行亚克隆,最后得到一系列可以直接用于测序的小片段DNA克隆。
我们可以比较一下各种基因组图谱。遗传图是以各个遗传标记之间的重组频率为定位的尺度,因而是一种最粗略的图谱。物理图谱里,限制性内切酶图谱是以1Mb到2Mb为尺度的;由酵母人工染色体克隆排序组成的物理图谱分辨尺度是40kb。物理图谱的分辨与精细程度随着技术发展不断提高,物理图谱的最终形式就是DNA碱基序列本身。
人类基因组物理图的问世是基因组计划中的一个重要里程碑,被遗传学家誉为20世纪的“生命周期表”。与化学家门捷列夫在100多年前所发现的“元素周期表”相比,“生命周期表”意义同样重大和深远。在遗传图上,我们只能确定某一基因的大致位置范围。而遗传图与物理图相结合时,我们便能迅速确定这一基因在DNA分子上的确切位点了。
序列图——揭开DNA分子的内幕
序列图是在物理图基础上的进一步升华,是最全面、最详尽的物理图,也是人类基因组计划中定时、定量、定质的最艰巨的任务。
人类基因组DNA序列图的绘制工作,可以做这样的比喻:假如说人们只穿4种颜色的衣服:红、绿、蓝、黑,人类基因组计划就相当于把世界上30亿人所穿的衣服都搞清楚,而且注明位置顺序,如所在的国家、城市、街道、楼房、房间。人类基因组DNA序列图的绘制,是在上述两张图的基础上,采取了“分而胜之”的“从克隆到克隆”的策略。科学家们根据已在人类基因组中不同区域定好位置的标记(也就是遗传图的“遗传标记”和物理图的“物理标记”),来找到对应的人类基因组“DNA大片段的克隆”。这些克隆是相互重叠的。再分别用仪器测定每一个克隆的DNA顺序,把它们按照相互重叠的“相邻片段群”搭连起来,这样便测出了DNA的全序列。
为了测定这些大批段DNA克隆的序列,要将这些DNA克隆按遗传图与物理图的标记,切成1000个核苷酸左右的小片段,再“装”到一种细菌质粒的“载体”上,送进细菌中克隆,大规模地培养细菌,再从细菌中提取这些克隆的DNA。这些克隆的DNA将作为测序的“模板”。这些DNA要求质量上很纯,数量上准确,还不能相互混杂。
在DNA模板制备好了以后,就要进入测序工作。第一步是“测序反应”。简单地说,是以要测的DNA为模板,重新合成一条新链,分别用不同颜色的荧光物质标记上。这样如果一段序列的一个位点上是A,就将代表A的荧光物质标记在A的后面。这好比一个姓T的人手中拿着红灯笼;一个姓A的人拿着绿灯笼;一个姓G的人拿着黑灯笼;一个姓C的人拿着蓝灯笼。这样在黑夜里,从灯笼的颜色我们就可知道是谁了。同样道理,由4种碱基形成的长度相差一个核苷酸的新DNA链,从结尾碱基显现出来的不同颜色的荧光,便可认定是:或A、或T、或G、或C。
测序反应做好后,第二步是上“自动测序仪”分析。自动测序仪能将长度仅相差一个碱基的DNA片段一一分开,由于不同片段“尾巴”的核苷酸已标有不同颜色的荧光染料,这样我们便可以很直观地读出A、T、G、C的排列顺序。
这些序列通过电脑加工,检查质量,再用一些特殊的电脑程序,将相互重叠的序列搭连起来。要确定每一位置上的核苷酸,至少要测定5~10次。如果中间有“空洞”,也就是有漏掉的测序核苷酸,还要将这些“空洞”用各种技术“补”起来,最后形成一个大片段克隆序列。这些序列片段再根据“相邻片段群”的重叠部分搭连起来,就组合成了一个染色体区域或一个染色体完整序列。如果将人类基因组的24条染色体的DNA序列全部测完,并绘制出序列图,这时人类基因组序列图谱才算大功告成了。
1999年12月1日,由美、日、英等国家的216位科学家组成的人类基因组计划联合研究小组在东京宣布:已将人类第22号染色体的3340万个碱基序列全部确定。这是人类基因组计划中完成的第一条染色体序列测定工作,由此,人类便打开了通向微观生命世界的大门,并为从根本上了解疾病的发病原因和人体生命活动的机理打下坚实的基础,这是有史以来人类在生物学领域迈出的最重要的一步。
转录图——书写DNA分子的生命乐章
转录图是基因组计划的第四张图。转录图就像生命的乐章,是一张极为重要的图谱。我们知道,只完成人类基因组DNA序列图谱是不够的,因为这些序列究竟起什么作用,怎么起作用,这是必须要解决的问题,否则序列图是没有意义的。只有搞清这些序列的功能,才能了解序列图的真谛。
整个人类基因组虽然有30亿个碱基对,但只有2%~3%的DNA序列具有编码蛋白质的功能(约有10万个基因),而在某一组织中又仅有其中10%的基因(约1万个)是表达的,其他的基因都处于“休眠”状态,像冬眠的动物一样。我们知道,基因表达的第一阶段就是“转录”。如果能把这些表达的基因制成一个转录图,那我们就能清楚地知道不同组织的基因表达有什么差异;不同时期同一组织的基因表达又有什么不同;不同基因在不同组织中是表达还是沉默,表达水平是高还是低;身体在异常状态下(如病变、受刺激等)基因的表达情况与正常相比有什么不同……这些是科学家们最关心、最感兴趣的问题,也是人们对各种疾病进行深入研究的基础。
那么,怎样绘制转录图呢?
前面提到,生物性状是由结构蛋白或功能蛋白决定的。结构蛋白如动物组织蛋白、谷类蛋白等是构成生物体的组成部分;功能蛋白像酶和激素等在生物体新陈代谢中起催化和调节的作用,这些蛋白质都是由信使RNA编码的。信使RNA是由编码蛋白功能基因转录而来的,转录图就是测定这些可表达片段的标记图。如果说在人体某一特定的组织中仅有10%的基因被表达,也就是说,只有不足1万个不同类型的信使RNA分子(只有在胎儿的脑组织中,可能有30%~60%的基因被表达)。如果将这些信使RNA提取出来,并通过一种反转录的过程建成cDNA文库,然后再测定这些DNA的序列,最终就能绘制成一张可表达基因图——转录图。
所谓反转录是指在反转录酶的作用下,由信使RNA反转录出DNA,这种DNA便称为cDNA。这种cDNA的碱基序列与转录信使RNA的DNA序列是一致的。分析cDNA序列就等于分析转录基因的DNA序列,由此把绘制可表达基因图称为转录图。
绘制转录图,就需要有大量可表达的DNA片段,所以首先要不断地丰富可表达DNA片段数据库。到1996年夏天,科学家们已收集到40万种可表达DNA序列,但这个数目并不代表人类基因组中可表达基因的数目(6万~10万个基因克隆),因为一个全长的拷贝DNA可能产生几个重叠的可表达DNA片段。美国人类基因组科学公司称已得到了超过85万个可表达DNA片段的数据库,对应于可能的6万个不同的基因,这与人类基因组的全部基因数已相差不多了。现在,国际数据库中所贮存的可表达DNA片段的数量正以每天1000多个的速度增加着。
有了这些可表达DNA片段,下一步就是将这些可表达DNA片段在人的基因组中定位,即将这些可表达DNA片段与某些疾病的易感位点联系起来。
现在,国际合作的人类基因组计划,已公布了至少160多万个拷贝DNA片段的部分序列,科学家们称之为“能表达的标签”。这160万个来自不同组织的拷贝DNA片段序列,经过分析与拼接,至少代表了万余个不同基因的部分cDNA序列。目前,科学家们尚需把这些转录的DNA搁到人类基因组的特定位置上,从而绘出真正的基因表达图。