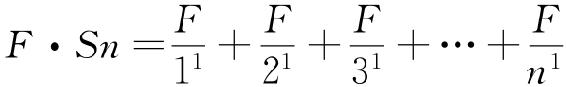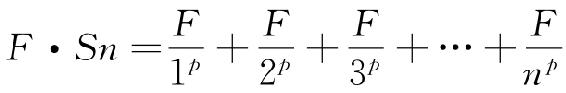第三章
形式—语义平衡与进化过程的经济
上一章论述了我们研究的三个不同方面。首先我们分析了几个长篇言语样本中词语的频率分布,并发现了其中一些规则,这些规则用一些相对简单的数学方程式容易加以描述,这可以称为我们研究的形式方面,因为它是指词语的外在且可辩的形式。其次我们分析了20 000个最常用的英语词语的词典意义的频率分布,这些词语由桑代克统计的,它可能是该领域的杰作,而且我们又发现了意义分布的规则,该规则可作简单的数学描述,这可以称作我们研究的语义方面,因为它最终处理的是词语的“意义”而不管其形式。第三,我们根据最省力原则在理论上分析了我们的数据,首先是分析了一组假定的相对的统一化之力与多元化之力,并最后建构了一个机械的钟铃类比,它的功力不仅最小化和因时平均分布,而且还可以由我们发现的用于描述词语的那些方程式加以描述,这就是我们研究的理论方面。
现在我们将尝试,在我们探究具体的人类言语经济学以及一般的人格经济学时,把我们研究的形式方面、语义方面以及理论方面更加密切地融合起来。
显然,在做此类研究时,论证的轻松与成功的机遇两者都在很大程度上取决于出发点与处理方式。
至于处理方式,我们将使用上一章所用的精密科学中同样熟悉的归纳—演绎法。更具体地讲,如果我们最省力原则是正确的,我们在理论上主张我们有望在一些关键时刻所作的发现;接着我们在经验上断定那些关键时刻的实际状况,希望能够据此核实我们理论观点的有效性。我们将同时以此方式阐释所论证的该原则的细节内容并且还用事实来加强论证。
至于出发点,我们将接着上一章继续论证。也就是说,我们将首先论述我们的机械钟铃类比,它有n个钟铃和一个敲钟精灵。然而,为了避免该类比固有的死板,也为了使它更符合日常现实,我们将把n个钟铃改成工作台上n个不同的机械工具,同时将这个敲钟精灵改成一个有血肉之躯的工匠,他将必须用自己的工具尽可能经济地完成工作才能活下来。按这种方式我们先前的钟铃类比将会变成一个工具类比,它的新主人即这个工匠将要面对的是生存问题,该问题与我们日常生活中将工具匹配工作以及将工作匹配工具所遇到的那些问题很相似。
为了帮助论证,我们将问题限定在固定工作的情况上,其中只有工具是变化的。在这个方面,我们将看到工匠在执行他必须履行的固定工作时为了尽可能节省功力需要改变自己工具的数量、形式、组合与用途。在这些工具的形式与功能的各种变化中,将会出现两个主要的经济原则,(1)简略法则(the Law of Abbreviation)和(2)效益递减法则(the Law of Diminishing Returns),后者随后会导出三个推论出来的经济原则:①多能经济原则(the Principle of Economical Versatility),②置换经济原则(the Principle of Economical Permutation),以及③特化经济原则(the Principle of Economical Specialization)。我们会发现这些原则将在工具类比和言语流中发挥作用[1]。
但是,既然我们已经阐明了接下来归纳—演绎分析所用的处理方式和出发点这两个方面,仍有几个观点是归纳—演绎分析本身可能会采用的。一个是更加狭义的观点,我们据此主要关注言语方式的法则。每当我们试图表明言语流就其最细微处是鉴于主要的经济急切需求而组织起来的,这种狭义的观点每次都会得到尊重。
还有一个更加广义的观点,这个观点的本质在我们进行如下反思时显得很清楚:工具类比不仅可以特别用作言语方式的替代物,而且可用作所有其他人类行动的替代物,这些行动可识解为旨在生存而履行工作的活动。根据这个更广义的观点,言语过程仅仅成为一个更大行为体系即功能的形式中一个特别情况而已,我们为了分析研究已经选择了这个特别情况,因为对它作定量处理还是相当容易的。
通过采用这个更广泛的观点,甚至冒着有时似乎是闯入外部资料的危险,我们能够提出本书的基本理论建构,所以我们接下来章节中出现的大量数据只是这些基本经济原则的进一步阐释和延伸而已。因此,我们把钟铃类比转变为工具类比作为探究言语实体的形式与意义这些具体问题的第一步,与此同时我们也迈开了更广泛更一般的调查研究的第一步,这最终会涉及普通的形式语义平衡这些问题,以及遍布整个生物社会领域进化过程的一般经济问题。
我们在上一章结尾部分提出一个钟铃类比,其中几个相同钟铃等距离安置在一个直板上。木板一头有个敲钟精灵往返在这些各个钟铃间,他的行走顺序是往返所用的功力消耗比率将尽可能近似一个常量。从这个钟铃类比的本质中我们发现了这个方程式N×If=常量(近似值),它代表了我们称作为最小功力因时平均分配。尽管这个钟铃类比有利于机械地阐释词语分布的经验方程式,其结构与操作明显存在的死板显然使它不适合用作言语过程的全部类比,言语过程显然不断改变形式、内容以及组合。因此,我们来建构一个新的机械类比,我们称之为工具类比,该类比将具有钟铃类比的所有功能却没有后者的僵化死板的局限性。
我们的钟铃类比是由一个敲钟精灵、n个钟铃、一块直板以及一块黑板构成的。除了这块黑板现在已成多余的,我们能够对其余设备稍加改变后用作工具类比。因此,敲钟精灵成了有血有肉的工匠;n个相同钟铃熔解成符合工匠需求的各种规格和重量的n个不同工具;直板不变除了它现在用作一个工作台展开在工匠面前,台面上挨个摆放着n个工具。在这个工作台上依次单线条放置工具的原因是,我们希望保持一维属性,因为言语也是一维属性的。在以后章节中,当我们遇到面积或体积的问题时,我们将在工匠的作坊中对维度进行必要的修改,而不必改变我们的数学方程式1。
既然我们已经搭建了工具类比的平台,我们将给我们的工匠作些说明。首先,他必须通过用他的工具尽可能经济地为我们完成某些工作才能得以生存。除此之外,我们别无所求。因此,我们不在乎他使用多少工具,也不在意他如何改变工具的大小、形状、重量以及用途,也不在意他如何在木板上排列这些工具,只要他以最小的功力总量完成了具体的固定工作。当然,如果他选择以任何方式改变其工具,他必须自己动手改变:总之,功力总量将不仅包括实际使用工具的功力也包括获得工具、维护工具、改变工具以及必要时处置工具所必需的功力。因此,这位工匠必须事先仔细考虑他的问题,因为,跟其他人一样他每天只有有限的功力任由处置,因而必须最大经济地消耗功力。这些就是我们的说明!
现在我们来让工匠开始从事他固定工作的事务,给他原材料以及许多相同手工艺品的大定单,他可用所拥有的工具制造出这些定单的产品。既然我们的定单解决了工匠的工作及原材料问题,只要他着手去做,那么从技术上看他是在固定的工作条件下作业,因此他只需关注如何排列、设计以及使用工具以便他的功力总量W尽可能地减少。我们接下来观看他的作业。
第一节 排列的“最小方程式”
为了使事情简单化,我们说工匠使用一次某特定工具的功力只是将工具由所在木板位置搬运到工匠的腿上再搬运到木板的原位这一次所用的功力。这个定义多少与我们先前钟铃类比中敲钟精灵的往返行程相对应。此外,我们在观看这位工匠搬运工具时将会发现,工具使用频率连同它们重复使用间隔长度将最终接近钟铃类比方程式,我们现在急切需要称之为基本的排列“最小值方程式”(“minimum equation” of arrangement)。
这个基本的“最小值方程式”不仅表述简洁而且又容易记住,因为该方程式建立在一个寻常事实的基础之上,即将某特定物质m的物体沿着既定距离d移动所必需的功力w等于该物质乘以距离的乘积,或者:如果我们认为存在一个持续的阻力或摩擦力[2],那么w=m×d。因此,如果我们认为某特定工具的距离d就是送到工匠的腿上且返回的往返行程,那么使用这个工具一次的功力将会是m×d。而且,如果作坊里在某特定测量间隔内使用某特定工具r的相对频率由f表示,并且如果我们一开始就忽略该工具获得、维护、改变以及处置时的功力,那么我们可以说在那个间隔Wr内该工具的功力—使用总量等于它的f×m×d的乘积,或者:
Wr=f×m×d
显然,在这块木板上的n个不同工具中每个都有自己的值Wr,该值取决于其f,m和d各自的值。而且这些不同值Wr的总和将代表在测量间隔期间的这些n个工具的功力—使用总量w。总之,这些n个工具在某特定测量间隔期间的功力—使用总量w等于每个工具的f×m×d的乘积之和。无论这位工匠如何排列他的n个工具,经济地还是非经济地,这都是正确的。
然而,既然这位工匠必须最大经济地使用工具,他必须以所有n个工具f×m×d的乘积之和将是最小值的方式来排列其作坊的n个工具。按其定义,这就是“最小值方程式”,我们将在我们全部研究过程中不断重复遇到它,“最小值方程式”描述的是我们这位工匠作坊里这些特定工具可能有的最大经济。
“最小值方程式”的意义很清楚。因此,如果两件工具有同样质量m不同频率f,那么使用越频繁的工具越是就近排列,这样工匠无需走远就可拿到。另一方面,如果两件工具有相同频率f不同质量m,那么越重的工具离工匠放置的越近,以便他无需走远就可拿到,以此类推。在固定频率、固定质量以及固定工具数量的静态条件下,这些不同工具根据“最小值方程式”沿着木板排列将会固定下来,并且代表了这些特定的n个工具可能最经济的排列[3]。
但是,既然我们已经描述了“最小值方程式”的意义,那么至于我们这位工匠n个工具的排列及使用的某些后果问题便出现了。尽管这些后果有很多,但是我们将限定于简短提及(1)“紧密排放”的问题(the Question of “Closing Packing”),(2)规模简略原则(the Principle of Abreviation of size),(3)质量简略原则(the Principle of Abreviation of Mass),以及(4)使用频率要素(the Factor of Frequency of Usage)。那么我们将从工具问题转向词语。
一、“紧密排放”的问题
我们工具“最小值方程式”的一个重要后果是“紧密排放”,即这些n个工具将会沿着木板尽可能紧密地排放,仅有移动及放回原处的空间。这是正确的,因为“紧密排放”总是在减少这些工具的距离d,于是因而减少使用它们的功力,不论该作坊里这些工具有多大的重量。“紧密排放”的作用很重要,这一点我们即将见到。
二、规模简略原则
紧密排放的一个作用就是,工具规模s越小就会越紧密地排放在一起,因此,距离d越短,结果大体上越省功力。所以,存在一个规模要小的经济。
由于工匠可完全自由地重新设计他的工具,所以总是存在减小工具规模的隐形经济。当然,我们稍后将详细了解这一点,只有在作此改变的功力少于后来使用改造后的工具所能节省的功力时,规模减小或任何形式的改变对于工匠而言才是经济的3。那么,对于某特定人来说,也可能有一个更低门槛的规模,在这个规模之下工具变得太小以至于用起来的功力增加了,然而,在这个动态过程中,在该限定条件下,存在一个冲动要减小或简略工具规模。于是,这种简略规模的冲动或力量是“最小值方程式”以及“紧密排放”经济的一个直接后果。
但是我们适当注意到,这个所谓的简略之力并不是对于木板上所有n个工具同等起作用。因为在“紧密排放”下,距离最近的工具规模减少一英寸,将会给其余所有n-1个工具节省一英寸距离d,可是第n个工具规模减短一英寸只会给这个最后一件工具本身的距离d减少一英寸。
因此,简略之力的重要性往往与工具到工匠之间的距离成正比,某特定工具离工匠越远,其规模减少一定量时的相对经济也就随之减少。所以,该名工匠在重新设计工具时将会根据所有这些工具与其本人的远近相应地减少它们的规模。
综上所述,我们结果有望发现,在我们工匠的作坊里,作为多年重新设计的一个后果,工具规模往往与它们到工匠的远近距离成反比例(即,工具越近,规模越小)。我们因而将规模与远近之间的反比例关系称作规模简略原则。
三、质量简略原则
减少工具的质量m也是经济的,这将根据所讨论的与规模减小有关的限定条件而定,由于w=m×d,质量减少,功力w因而也将减少。所以在动态过程中我们一直在表明,存在一个朝着减少质量的方向而运行的力量。然而,当我们探究这个力量偏向简化特定工具时,我们发现存在两个因素。
一个因素是距离,因为远端工具减少一盎司要比近端工具减少一盎司将给一次往返旅程节省更多功力。因此,随着工具一次次地使用,将会倾向于简略远端工具的质量。
然而——这是第二个因素——由于方程式Wr=f×m×d,近端频繁使用的工具减少一盎司比远端稀少使用的工具减少一盎司对于功力总量而言将会更加经济。那么频率要素也很重要。
如果我们选择结合距离与频率要素用于表述质量简略原则时,我们可以说是根据工具的功力总量Wr(=f×m×d)的多少而相应地减少这些工具的质量。总之,往往根据f×m×d的乘积来简略这些工具的质量,而不管具体情况下的频率、质量或距离。质量简略原则的一个作用就是趋向于使所有n个工具各自的功力总量Wr相等。
四、频率要素
至此,我们已经默认,n个工具各自使用频率总是固定不变的。然而根据我们的说明,该工匠可自由地以任何形式改变工具,包括工具的使用频率,其实,如果改变频率能够节省功力,他将被迫改变使用频率。改变某特定工具使用频率的一个方法就是重新设计这件工具,以便它因而可以执行某个或某些其他工具的任务,从而增加它自身的使用频率。
就频率要素的经济而言,显然最经常使用那个最容易用的工具最经济,即其m×d的乘积是最小的(如果为了简便起见而忽略其规模s)。因此,在重新设计工具时重新设计最容易用的工具是最经济的,这样该工具可以吸收其他不太容易使用的工具的任务从而增加自身更多的使用频率。(该表述是以新的说法陈述了我们早先的统一化之力。)但是,尽管我们发现无数个后果出自增加最容易工具使用频率所带来的经济,没有什么后果比由其产生的增加频率与减少质量之间存在互惠经济这个后果更重要。因为如果(1)在增加最容易工具的使用频率时存在经济,并且(2)在减少最经常使用工具的质量时也存在经济,那么(3)它将遵循①越频繁使用的工具越是根据简略原则而打造得更容易使用,而且②越是根据简略原则打造得更容易使用的工具,使用得越频繁。总之,更大频率的更易使用,更易使用的频率更大,诸如此类。
此外,当最容易工具的频率增加(同时其质量减少)时,由于“最小值方程式”的急切需求,该工具就会被移到离工匠更近;而且工具被移到离工匠越近,减少其规模的简略之力就会越大。因此在经过足够多时间允许我们工匠探索更经济地重新设计和重新排列工具的可能性同时又产生同样效果之后,我们可望在他的作坊里发现下面这个一般条件。
随着我们沿着工作台从工匠处往前走,我们将经过由更小、更轻以及更多频繁使用的工具到更大、更重以及更少使用的工具。换言之,在距离d一方与规模s和质量m另一方之间存在正比例关系,即它们三个往往共同增加。然而,在这三个要素(即d,s和m)与频率f之间存在反比例关系,即随着d,s和m的增加,f将会减少。在d,s,m与f之间的整个关系,我们理论上可以期望发现它存在于任何一套工具中,因为在动力过程中存在所探讨的各种论述过的力量,我们因而将这种关系称为简略法则,这一点我们稍后将发现可在言语中检测,简略法则恰巧就是言语中的一个基本法则。
五、小结:形式语义平衡与“最小值方程式”
我们来简要回顾,随着时间流逝以及随着工匠已经重新设计和重新排列工具以便将其执行任务时的功力最小化,这位工匠的排列n个工具的工作台上已经发生的一些事情。
正如我们早先所见,重新设计与重新排列这些工具的整个问题可以用“最小值方程式”表述,在这个方程式中,只要改变工具所增加的功力给接下来使用中所减少的功力远远抵消掉,所有n个工具的f×m×d的乘积之和就会减少到一个最小值。这个因素引发我们推测,在时间过程中这些不同工具在f,m,d以及s方面如此加以改变以至于我们从工匠处开始沿着这块木板行走应当发现有一个关联或趋势促使m和s增加以及f减少。这种关联我们已经称为简略法则。
作为这个简略法则的一个后果,一个更深层的因素在行经木板时值得关注。
由于该工匠的诸多重新设计,每个工具在形式和功能上都能从本来状态改变得无法识别。有些工具形式已经改变但是用法保持不变,按定义这就是形式变化。有些工具保留了形式而用途却已改变,按定义这就是语义变化。而有些工具可能形式与功能两者都已改变,而另外一些工具两者可能都未变化。
然而,无论这些改变是什么或不是什么,这些工具在该作坊历史中不时承担一定任务,它们都在承担或不承担某些任务,这根据“最小值方程式”是对该作坊功力总量最小化的反应,该方程式直接或间接地指所有形式、功能和组合。因此,我们可以说该作坊随时都在力求维持定义所言的作坊中工具形式或用途的形式—语义平衡[4]。
第二节 词语简略法则
现在该是用检查词语情况来检测我们工具类比的有效性,我们将词语及其频率与重要性这一方面与工具及其频率与重要性另一方面等同起来4。把我们前文的论证经过必要修改后应该有望发现在词语长度与词语使用频率之间存在一个反比例关系,我们认为,在另外一种恒常情况下使用较长词语的工作量比使用一个较短词语的要大得多,我想这是很正确的。
一、定量研究数据
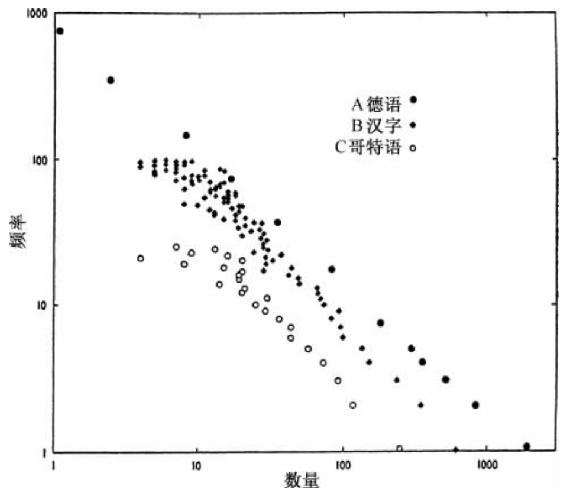
长话短说,我们将在表3-1中呈现两组数据,一组(A)是由R.C.埃尔德里奇分析美国报纸的数据,我们在图2-1的相关分析中提到过该数据;另一组(B)是普劳图斯拉丁词语的频率列表,我们在表2-2中讨论过该数据。我们给表3-1的每组数据呈现了词语的出现次数以及出现该次数的不同词语的数量。我们给A组数据呈现了根据平均音位数量计算的平均长度(大体而言,音位就是言语声音,后文将对此加以界定;sit的音位有s、i和t)。我们给B组数据呈现了根据平均音节数量计算的平均长度5。
表3-1
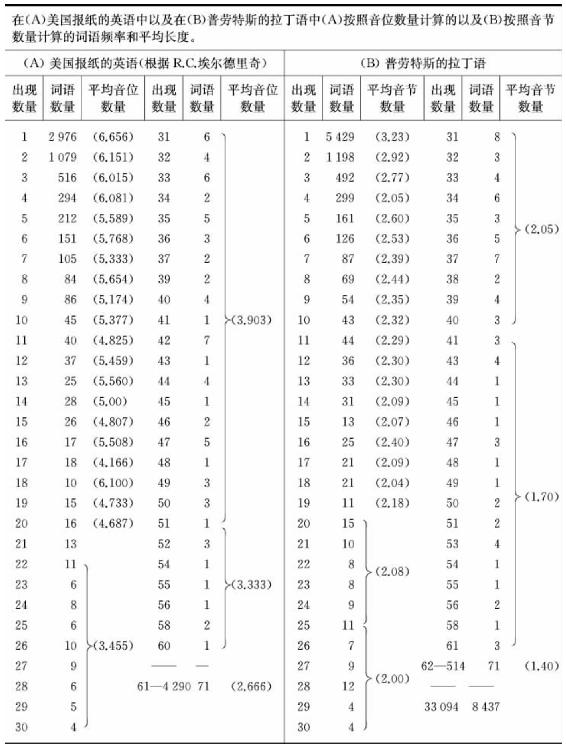
我们在表3-1的两组数据中发现了词语长度与词语出现频率之间明显存在反比例关系,正如我们基于工具类比在理论上所预期的那样,我们的工具类比也因而得以证实。
鉴于表3-1两组数据的明确关联,仍然只有两个问题,第一个问题是这种关联是否也存在于其他语言之中,第二个问题是在一个非常大的样本中这种关联多大程度上会存在。
至于第一个问题,我们能够汇报相同的关联可见于汉语的北京话词语中,关于这一点的原创论文已经发表了6,并且相同的关联也见于(未发表)美洲印第安语言的努特卡语(Nootka)、达科他语(Dakota)以及大平原克里语(Plains Cree)之中,这些语言的词语—频率分析将在后文进行论述。此外,相同的关联从主要的西欧语言的频率列表中也清楚可见7。事实上,这个关联对于比较语文学的学生而言如此明显以至于没有什么可以吸引他们对此作进一步的定量研究。
至于第二个问题,是指简略法则在非常大的样本中可能的运作情况,我们借用E.L.桑代克博士的话来讲,他对于稀罕出现的词语的长度作了精彩研究,汇报了如下惊人的发现:“我们已经发现有证据表明甚至在一百万个词语中出现低于两次的词语中存在的频率差别与音节或音位数量是相关联的。”8因此,这种关联适用于聚集了差不多一百万个连续词语的样本,或者适用于那些长度是《尤利西斯》四倍的样本中。那么,这似乎表明我们的研究在经验上是相当可靠的[5]。
二、形式及语义变化的机制
鉴于先前数据,如果只是简要地探究维持上述(词语长度与词语使用频率之间)反比例关系这是非常自然的事情,因为我们很容易了解,就单纯可能性而言,较长的词语也可能使用得更频繁。尽管这些机制已经在早期发表的论著中作了非常详细的论述9,而且尽管我们本书后文将再次论述这些机制,我们或许可以指出,我们工具类比的形式及语义变化也是改变词语长度的机制。
作为形式变化的例子,我们只需引用phone,gas,bus,paratroop作为telephone,omnibus,parachuteroop的变体等此类例子即可。这些在技术上称作截断(truncations)。
作为语义变化的例子,我们只需引用一些较短词语作为替身的例子,如car代替automobile,或者juice代替electricity,在这里,更短形式的代替词表达了更长词语的专门意义,并且因而发生了语义变化(即,在语义变化后,car与juice意指他物时分别用来表示“automobile”和“electricity”)。这些被称作代换(substitutions)。
每种语言显然正在经历形式及语义变化,这些变化总体上朝着缩短较长词语的长度或者增加较短词语的频率而进行。此外,据我们所知,每门语言都表明词语的长度和使用频率之间存在反比例关系,这种关系正如我们早已说明的那样并非是先验的必需,因为较长的词语可能是高频词语。因此,虽然我们没有假定在这三段中穷尽这个主题,我们还是很放心地把形式及语义变化视作至少是简略法则的两个运作机制,简略法则是言语的基本法则。
然而,简略法则不是言语运作过程中唯一的法则。作为本文论述的指南我们首先再次回到工具类比。
第三节 工具的效益递减法则
到目前为止我们还没有关注用来描述工匠工作台上的工具数量n的多少。即便现在我们也不会关注n的绝对大小而只是关注n的数量或增或减所造成的后果,因为我们记得工匠如果能够通过n的数量变化而减少作坊的总工作量的话,他可能会改变工具的数量。
显然,随着n的数量增加,工具将会沿着木板排放得越来越远,结果导致最远处工具的距离d变得非常大。而且既然d的增加将会增加新工具的工作量(即w=m×d),那么显然n的增加将取决于可以称作“效益递减法则”。因此,工具数量n的增加是不经济的,同时相反地,n数量的减少是经济的。
这个n是更大还是更小的问题,我们在前文章节中根据统一化之力与多元化之力已有论及。
目前我们将论述n数量可能发生经济的变化所依据的几个原则:(1)多能经济原则,这个原则我们早已预示了;以及(2)置换经济原则与(3)特化经济原则,后两个原则是新提到的。所有这三个原则既简单又明了。
一、工具的多能经济原则
我们现在转而论述工具的多能经济原则,只是探究在什么条件下要增加某些工具的多功能(即不同用途的数量)以便将其他工具从木板中废除从而减少n的规模。这方面的情况显然是(1)工具在木板上越远,废除它就越经济,以及(2)工具离工匠越近,通过吸收远处工具的任务来增加该工具的多功能就越经济。因此,一般来说,越近的工具会是吸收性工具而越远的工具将会是被废除的工具,这里由“最小值方程式”的本质决定的。
但是现在我们来假定距离最近的10件工具将被设计成可吸收10件最远工具的用途,而后者将被消除(为了方便起见我们认为木板上每件工具只执行一项任务)。
于是问题出现了,这10件距离最近的工具又是如何各自分别吸收10件距离最远工具的功能?在这方面我们记得,随着我们从工匠处开始沿着木板前行会发现工具使用频率随着它们离工匠距离的增加而减少;这不仅对于最近10件工具的频率是正确的,而且对于最远10件工具的频率也是正确的。于是便产生了另一个问题,是最高频率的近处工具吸收最高频率的远处工具的用途(以及从而吸收其频率)还是某个其他方案更经济。
我们从前文论述中得知,根据工具离工匠远近相应地增加工具频率才是经济的。因此,根据工具的频率相应地增加其频率才是经济的。所以,前10个工具中最近(因而最频繁的)工具吸收后10件工具中最近(因而是最频繁的)工具的用途和频率才是最经济的,其余工具依此类推,直到第10个最近工具吸收了木板上最远工具的用途和频率。
在上述距离最近的10件工具吸收了最远10件工具的用途和频率之后,我们发现这些最近10件工具的多功能和频率发生了怎样的变化。至于它们的多功能,我们知道这些10件工具中现在每个都有2个不同用途而不再是1个用途,它们因而具有同等的多功能。但是至于它们的频率,我们知道每个工具都是根据它们与工匠的远近成正比例地增加其频率,因此距离最近的那个工具要比第10个近处的工具增加了更多的频率。
如果我们打算继续进一步作理论论述,我们应该很快就会得出理论上只有唯一一个具有多功能的工具,而所有其余n-1个工具都从木板上废除了。由于物质的物理化学属性现实很无情,实际上我们工匠或许很难设计出这样多功能的工具。因为尽管我们能够不难想出一些多功能的工具(比如瓶塞钻开瓶器—折刀—文件螺丝刀这样的精巧设备)能够执行许多不同任务,我们凭直觉感到多功能增加过程不能无止境,因为有一个我们可以称作因应多功能不断增加而不断增加的阻力,这种阻力使得无限增加多功能也是不经济的(即,将工具的多功能由10个用途增加到11个,相比由1个增加到2个,要花费更多的劳力去制造和使用[6])。我们假定这就是因应多功能不断增加而不断增加的阻力并来探讨该阻力对于我们作坊工具多功能带来了怎样的后果。
因应多功能不断增加而不断增加的阻力所产生的一个后果将会是,距离越近且越容易的工具比越远的工具可能具有更多的多功能,因为这些近距离的工具任何情况下都是更加经济的工具。更具体地说,距离越近的工具在成为更经济的工具时将会比更远距离的工具相应地更有能力抵消不断增长的阻力。因此,我们从工匠处开始沿着木板前行,将经过由多功能最多的工具到多功能最少的工具(也就是说,从执行最多不同任务数量的工具到执行最少不同任务数量的工具)。
前文论述中,兼容性工具的频率的增加往往与它们到工匠的距离远近成正比例。因此,每件工具平均使用频率将会随着该工具到工匠距离增加而减少——这种关系我们称作工具的多能经济原则。正如我们在图2-2中所见的,这个工具的多能经济原则在词语的不同用法或意义的数量上也有对应物,我们在这些词语中发现,词语每个意义的平均出现频率随着词语的频率而降低。
由于我们没有确切了解机械工具的因应多功能不断增加而不断增加的阻力的实际比率,所以我们不能更加精确地假定工具多功能及其相关的使用频率之间存在的关系。目前我们只需了解,我们的效益递减法则往往通过把工具的多功能和使用频率按照它们与工匠距离远近成正比例地增加来减少n的规模,频率的增加速度要比多功能的增加速度快得多。显然,有时候,多功能的增加会变得不经济,结果n将会趋向稳定。
多能经济原则很重要,因为它为理解普遍存在的置换经济原则提供了一个方法,置换经济原则与多功能经济原则在形式与效力上十分相似。
二、工具的置换经济原则
我们已经发现了工具的多功能(以及频率)是按照与工匠的距离远近成正比例增加的经济。由于多能经济原则,n的规模可能会减少。现在我们来探讨存在的另一个经济,也是与工具离工匠距离远近相关联的经济。这第二个经济我们命名为工具的置换经济原则。
该原则,使得n有可能进一步减少,这个解释起来并不困难。工匠能够一起使用两个或以上的工具去执行某特定任务而不愿使用远处的工具去执行该任务(例如,大头锤和凿子齐用,或者尺和铅笔齐用,或者锯子和砂浆桶齐用)[7]。通过这种方式两个或以上的工具一起可以吸收另一个工具的任务,这样的话另一个工具就可以废除了,结果n就会减少。
现在问题来了,即哪些工具应该结合起来吸收用途,哪些工具又应该因用途如此被并后而废除。答案很清楚,因为这只是对我们工具多功能的论述作出一个释义而已:工具应该按照与工匠距离远近成正比例地置换,这些工具的置换应该吸收最远处工具的用途——用最容易的最近处的置换吸收将被废除的远处工具的最频繁的用途。
此刻,我们必须小心对待我们的论证,以免我们理论上最初的几个工具在置换时吸收其余工具的所有任务——这个可能实际上几乎不可能发生。因为正如物质的物理化学属性的无情现实将阻止单个工具无止境地增加多功能,同样的物质现实也将阻止工具特定置换无止境地增加多功能。用两个或以上工具置换某单个工具,我们可以假定存在一个阻碍置换多功能不断增加而不断增加的阻力。该假定意思是工匠必须采用工具最大不同的置换以吸收那些最大数量的即将被废除的工具的用途。此外,该假定也将意味着,长期来看,距离越近的工具比越不近的工具将会进入更多数量不同且更频繁使用的置换,这一点我们马上会更清楚地发现。
可是,首先根据定义我们认为,为了让置换一次执行一个“置换任务”,置换中必须一次搬运一件工具到工匠的腿上然后再放回原处,而且我们认为,将这些工具运到工匠的腿上再放回原处的总功力是使用一次该置换工具执行某特定任务(即某特定“置换任务”)的功力。我们也将认为,每个置换工具只能执行一项任务。为了进一步简化我们的问题,我们最终认为,木板上所有n个工具差不多具有相同的物理量值(或者,如果有区别,越小的工具将会是越近的),而且我们还认为,每个工具的频率与其距离成反比例。总之,我们认为,我们的工具代表了相当长的一段时间内服从于简略之力以及“最小值方程式”的其他力量所产生的效力。
鉴于以上假设以及使用置换的功力的定义,有n个观点一目了然:(1)置换附近工具比远处工具显然更经济。的确,工具放置得离工匠越近,用置换的方式使用它们就越经济。(2)如果可能,被吸收的最高频率的任务显然应该用最简单的置换方式来完成。(3)置换如果比新型专门用途的第n+1个工具花费更多的功力,置换显然将无利可图。
至于上文第一个观点(1)是关于按照离工匠远近的顺序选择置换工具所产生的经济,我们不仅发现①工具越近置换就越经济,而且还发现②越近的工具比稍远的工具越能进入更多不同且更主要的置换之中,这种置换相当合算。因此,例如,用某特定规模的置换一起使用最近处的四个工具比用同等规模的置换使用次近处的四个工具更方便,因为使用位于木板远端的工具会导致所耗功力增多,这个工作量是在24个不同可能置换的每个置换中一起使用最近4件工具所必须的,该工作量要少于在2个可能置换中一起使用后4件工具中任何2件时的所耗功力(如果我们认为功力与序列—距离成正比的话);因此,越近的工具不仅能够经济地引起更便捷的置换,而且能够引起更加广泛的不同置换。由于读者将会发现这个观点对于理解词语、短语、分句以及句子时十分有意思,我们将作如是概括:工具放置得离工匠愈近,它能够有利可图地进入不同置换的数量将会愈多。显然,工具按照与工匠距离远近所进行的经济置换的程度与其经济多功能的程度是相匹配的。
但是置换经济原则与多能经济原则两者之间的匹配,在我们转向所吸收任务的相对频率这个问题以及提出(2)何种特定的工具置换能够最经济地履行所吸收任务的时候,将会更加显著。我们在此可见,最近处因而也是最便捷的置换能够最经济地履行所吸收的最高频率的任务,正如我们曾经看到在多能经济原则下最近处且最方便的置换情况一样,因而我们知道按照工具与工匠的远近增加工具的频率才是经济的。因此,我们可以说①某特定工具将会进入许多不同置换,并且②这些置换将会③按照工具与工匠的远近成正比例地得以频繁使用。
然而,(3)正如我们前文已经暗示的,任何置换所需功力若多于新型专门用途的第n+1个工具时,使用该置换显然都不会经济。这对于任何实际一套n个工具在n增加时都有两个重要的后果:①木板的某处将有一个临界点,越过此点没有工具能够有利可图地进入任何置换;于是我们说,这个临界点把更近的可置换工具与较远的不可置换工具分隔开;②由于存在这个临界点,某特定数量n的不同工具能够履行的不同任务数量是有限的。因为,我们假定对于单个工具不断增加的多功能及其置换存在一个不断增加的抗力。当这些n个工具在其履行的用途方面进入饱和状态(我们称之为特定n个工具的用途值Z,而且它意指单个以及被置换的工具的完全饱和状态)时,最终将会到这个临界点。一旦到达这个饱和点,增加这些n个工具的不同用途的数量若超过上述Z值的唯一途径就是增加工具的数量n。
因此,我们可以总结为,除了我们最初的简略经济原则(其中,重要性与频率成反比例),我们进而还有两个经济原则:(1)一个原则是,工具的多功能随着它们与工匠距离的增加而减少;以及(2)另一个原则是,n个工具能够经济地进入不同置换的用途的数量、规模以及频率随着离工匠距离的增加而减少。n的实际规模在最后分析中将受控于所履行任务的数量Z以及对应多功能和置换而存在的实际抗力。对于某特定Z,n便是最小值。
然而,还有另外一个经济原则:工具的特化经济原则。
三、工具的特化经济原则以及年龄问题
工具的特化经济原则能够立即由先前的置换经济原则推论出。任何置换的相对频率一旦增加到其任务由一个新型独特的第n+1个工具来执行更经济的时候,那么采用这件第n+1个工具将会是经济的。这件新型工具将被界定为特化工具,因为它执行的任务要不然只能由两件或以上的工具置换才能履行的。
当然(1)置换的频率一旦增加,该置换的成分工具将会移到离工匠更近,因为存在“最小值方程式”的迫切需求,因而取代这些工具的序列一直到它们已经摆放在那些将会更靠近工匠的成分工具的新位置与老位置之间。另一方面(2)在特化工具已经被采用替代工具的置换之后,那么现在被遗弃的置换的成分工具其频率将会降低到先前置换的频率程度;于是根据“最小值方程式”的迫切需求,这些频率减少的成分工具将会移到离工匠更远。总之,随着置换使用得更频繁,其成分工具将移到离工匠更近;然而一旦置换停止使用,那么这些成分工具的频率将降低到先前置换的频率程度,并且因而在木板上后退到离工匠更远。
成分工具频率和位置的这种改变在我们简略经济原则来看是很有意思的。显然,只要上述置换成分工具频繁使用而且放得离工匠近,它们的大小将会根据简略原则减小到与它们相邻工具减小后的规模相当。然而,一旦这些工具离工匠越来越远——无论是以什么原因——那么它们缩小后的规模将比它们新邻居的规模小。
因此,一旦我们发现一件工具(或一个词语)的规模比同一频率范围内的邻居小,我们可以推断出,这个小于平均规模的工具(或词语)是一个更加旧的工具(或词语),它的用途日益减少(因此,我们将称之为衰老的工具)[8]。
这个已经取代先前置换的新型第n+1个特化工具将会在木板上分配到与其频率相称的位置。由于该新型工具还未受到强大的简略之力的支配,其规模可能比相邻工具的规模大。因此一旦我们发现一件工具(或词语)的规模超过同等频率的平均值,我们不仅可以断定它是一个更加新型的工具(或词语),而且可以断定其用途很可能变得越来越多(我们因此称之为新生工具)。
因此,作为特化经济原则的一个后果,工具的年龄与规模之间将存在一个相反的关系,即年龄越大规模越小。任何一家工具作坊都存在这种相关性,这足以表明特化经济原则的效力。
四、小结:动态过程中形式—语义平衡
假如工具的简略、多功能、置换以及特化经济原则毋庸置疑确实存在,而且假如我们的工匠总是经济节约的,那么随着时间流逝,所有上述原则将会一直同时影响我们一套工具的数量、规模、形式、功能、排列、多功能、置换以及频率,以便将执行任务的功力最小化。根据定义我们认为,这些原则在对一套工具如此影响时是企图保留或恢复形式—语义平衡(或者有机平衡);我们还认为,受此影响的工具为了保留或恢复形式—语义平衡而在动态过程中不断变化。由于执行任务涉及的所有成套工具总是处于动态过程中,我们可以有望随时发现任何一套工具中都存在这种倾向或相关性,这些工具是为了履行固定任务根据固定程度的标准加以组织的。
因此,我们可以有望发现,一般来说越频繁使用的工具往往会是更轻、更小、更旧、更多功能的工具,同时由于与其他工具置换更彻底地整合了其他工具的功能。
现在如果我们置身事外再审视上述斜体字的概括,我们发现这套工具的一个深层属性与几个不同工具的相对守旧性相关联。因此我们发现最频繁使用的工具往往是工具系统里最轻、最小、最旧、最多功能以及最彻底整合了的工具,也将会是最有价值的工具,即该工具如果永久遗失,重新设计及重新装备相对而言将会花费最大代价。因此,保存这个最高频率的工具是最经济的。扩展上述论证可知,保存任何特定工具的价值与其相对用途频率是成正比例的。(例如,如果没有可以替代的工具,木匠应该更加格外精心地保存自己唯一的锤子与锯子,而不是庞大的、专业的、昂贵的却很少使用的车床。)[9]
既然我们已经阐述了工具类比,那么我们就回到词语中。
第四节 词语的效益递减法则
我们现在回到检查工具类比的言语方面,我们必须揭示词语事实上是否表明(1)多能经济原则(a Principle of Economical Versatility)、(2)置换经济原则(a Principle of Economical Permutation)以及(3)特化经济原则(a Principle of Specialization)及其伴生的新生与衰老的概念将会合理地证明我们的结论(4)意义深远的动态过程中形式—语义平衡(Formal-Semantic Balance in Dynamic Process)。但是在开始这个艰辛的论证历程之前,我们应该阐明两点。
第一点是,我们呈现的数据不能说成代表固定言语任务的任意事例,而应该视作可变的任务与工具的更加必不可少的条件。我们无需担忧这一点,因为我们将在我们检验的实例中发现上述四大原则。我们将在第五章明白,为什么同样这些原则也会在可变的任务与工具的条件下起作用。
然而,第二点并不能简单地处理,因为它是指我们工具类比在任何条件下在词语中的可应用性。词语等同于机械工具说起来容易,可是还存在这样一个问题,即言语过程中是什么等同于机械工具的专门用途。总之,词语借助专门用途执行什么具体任务?
我们都知道,某特定情况下不同词语激起听者不同反应,因此我们可以推测,激起听者特殊反应的任务代表了词语的具体用途。词语的这些不同的具体用途似乎是词典编纂者称作的词语的词典“意义”。因为如果我们拿本词典审视其中不同的词典“意义”,我们会发现它们大体上分作两类。一类“意义”只不过是一个或更多个词语用途的详细说明,这种“意义”可称为用途界定,英语a,he,and,it的“意义”就是这种。另一类“意义”只不过是用来代替所言词语另一套可选词语,非常像用来代替某特化工具的工具置换,因此,如果你推敲词语castaway,就会考虑用一些替代词语“thrown away”,“cast adrift”,“shipwrecked person”,“outcast”。
由是,词语的词典“意义”似乎与我们普遍的工具类比中机械工具的用途相对等。我们说词语的词典“意义”是指见于词典里的意义10。
在采用词语用法这么简单且实际的观点时,我们可能没有使自己钟爱那些认真研究意义以及意义的意义这些古老问题的学生。然而,有关意义及界定的全部问题,我们大体上可以为上述勤奋学生指出,在严谨科学中界定实体是为了研究属性,而且在研究属性之后借助论证过的知识可以回到该实体并对之重新界定。因此,我们上文使用词典“意义”仅仅初步界定在词语流中什么可对应机械工具的用途——这个初步界定在我们整个研究过程中将会导致出对一个真正古老问题的各种更佳界定。
然而,即便这个初步界定在我们接受之前也必须证明其价值。因为词语的词典“意义”的行为方式是否类似于机械工具用途的行为方式,这还是个问题。
一、词语的多能经济原则
如果词典意义与词语的关系等同于机械用途与机械工具的关系,我们应该有望在某特定连续言语实例中发现,词语的不同词典意义的数量将与它们各自相对频率成正比例。因为,毕竟那就是我们在理论上所预期的不同频率工具的不同用途数量的情况,该情况已经根据工具多能经济原则作出分析。
正如我们在图2-2中已经阐明,桑代克英语频率统计中连续20组千词组的词语中平均不同意义数量,若按照频率降序排列,将根据序列平方根成比例地下降。这反过来意味着词语不同意义的数量也将根据其频率的平方根而下降,如果我们是正确地假设桑代克分析中20 000个最高频词语大约根据调和级数而分布。这些数据的理论解释在第二章中已作呈现,其中我们证明了为什么-0.5斜率可以预见。
就最省力原则以及工具类比而言,我们记得-0.5斜率或线性分布都不是必须的。非线性分布或许已经合理地符合了我们的理论预期,由于我们不知道相对于渐增的多功能存在着渐增的抗力这个法则的本质。我们已经发现词语意义的序列频率呈线性分布,该频率分布的斜率是词语斜率的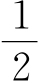 ,这个事实表明,对词语而言可能存在“抗力法则”,该法则对于阻碍意义多功能增加按照与该增加成正比例地起作用。我们在第二章中从理论上给听者心智而不是给言者心智设置了各种抗力(即听者的经济),而且我们将在第五章发现支撑此观点的深层原由[10]。
,这个事实表明,对词语而言可能存在“抗力法则”,该法则对于阻碍意义多功能增加按照与该增加成正比例地起作用。我们在第二章中从理论上给听者心智而不是给言者心智设置了各种抗力(即听者的经济),而且我们将在第五章发现支撑此观点的深层原由[10]。
在离开词语多功能的这个话题之前,我们来想象一下我们为此目的而使用桑代克数据可能遇到的一些反对意见。其中一个反对意见可能是,桑代克博士处理的是词汇单位(即非屈折形式的词语)而不是完全屈折形式的词语。然而,由于英语词语屈折变化程度较低,该反对意见影响力不大,而且词汇单位序列—频率分布与完全屈折形式词语的序列—频率分布差别不大。另一个反对意见或许是,我们在图2-2中只呈现了连续千词组按序排列的词语的意义平均数量而不是不同单个词语本身的意义平均数量。这第二个反对意见不是完全没有道理,遗憾的是词语及其意义的序列—频率分布没有现成可用的。然而图2-2中的相关性清楚明白,而且桑代克博士选择以500词和1 000词为单位这个事实在本研究看来是十分任意的。想象不出有什么理由可以假定,如果选择更小的单位这种相关性会有可能消失。
除了上述反对意见,桑代克博士数据就本研究目的而言相当令人满意。首先,他从大量英语实例中统计并确定了哪些是20 000个最高频词语,并且将之作为其词典的核心。接着他和欧文·洛奇(Irving Lorge)博士查阅了《牛津英语词典》(The Oxford English Dictionary)发现20 000个词语的所有史上不同意义是由词典编纂者从整个英语文学范围内加以确定的。于是桑代克确定所有这些20 000个词语的不同历史意义中有哪些是真正运用于他所统计的具体言语实例中。这些真正使用的意义单独列入《桑代克高级词典》(The Thorndike Senior Dictionary)。那么,我们反过来发现图2-2中的相关性几乎不能武断地确定为偶然之事[11]。
令人遗憾的是,没有现成的更多其他语言数据。不过,鉴于以上这组数据的广泛性和明确性,我们可以说词语的不同“意义”(或激起不同反应的种类)的数量似乎与其频率的平方根相等。
这与工具多能经济原则相一致。到目前为止,我们的工具类比已经得以证实。
二、词语及其他言语实体的置换经济原则
言语流中置换经济问题是言语结构的真正核心。因为,正如我们将由机械工具所作的扩展论证中发现,置换经济原则不仅可见于词语置换成为(1)表句词以及成为(2)更大组群,而且可见于(3)词素置换成为词语,以及可见于(4)音位置换成为词语。为了更加全面地看待该原则,我们将反过来分别论证这三类置换,就最后两类置换[即(3)和(4)]而言,我们照样将说明简略原则也在其中发挥作用。
(一)词语的置换经济原则
如果工具的置换经济原则在稍作修改后适用于词语置换,我们应该大体上发现,一个词语进入的不同置换的数量连同这些置换的出现频率将与该词语的频率成正比。或者换言之,一个词语使用得越频繁,该词语往往会更多地应用于不同置换中,并且这些置换往往会更加常用。此命题如果成真的话当可在实证检测中加以核实。
然而,在我们可以进行实证检测之前我们必须首先思考识别两个或以上词语的置换(为了方便起见我们因而称作表句词)的客观标准这个问题。因为要是没有某种这类客观标准,对置换原则不可能进行真正的实证检测。
在某些情况下,我们大概都会赞同特定连续词语是表句词,例如,brother-in-law,hot-dog以及hit-and-run driver。所以,至于短语glad-to-meet-you或者how-are-you大概也是表句词。然而在许多情况下恐怕更加难以定夺。因此在“Is your brother in jail?”这个句子里我们是否可以说brother in jail是个好比brother-in-law这样的表句词吗?那么,果真若此,father in the kitchen或者mother at the Women's Club又会怎么样呢?
为言语流中实体的分类而建立客观标准是个古老的问题11。就表句词而言,已经表明了存在一个屈折变化标准,意思是如果一连串词语能够像一个单个实体一样有屈折形式变化,该系列词语根据定义就是一个表句词12。因此,例如,英语通常是在名词的绝对词尾处加上(e)s后缀构成该名词的复数形式,如house的复数是houses,或boy的复数是boys。现在,根据上述标准,如果说brother-in-laws是brother-in-law的复数形式,我们是将之视作表句词在其终极词尾处加上(e)s。另一方面,如果我们说brothers-in-law是其复数形式,我们是在将brother-in-law视作一连串不同词语哪怕其间有连词符号,因为复数后缀(e)s没有放在它的最终词尾处。
屈折变形这个标准总体上非常好,尽管有些语言比如当今英语极少使用屈折变化,在此情况下该标准可能常常没有什么实际用处。因此,该标准对于判定hit-and-run这类英语形容词本质上是否可能为表句词时不起什么作用,因为英语中形容词从来就不是通过屈折变化来构成复数形式。另一方面,我们千万不要忘记,也有许多语言是高度屈折变化的以至于屈折变形几乎遍及了这些语言的所有结构。由于我们只是关心置换经济原则的检测,我们为了自己的分析有权从这些高度屈折变化的语言中选择一种语言,在该语言中屈折变化的标准完全有用。
我们依靠屈折变化这个唯一标准而忽视了表句词的“意义”似乎过于随便。但是,这里我们要记住基于工具类比我们在理论上可以预见,每个表句词都会有一个或以上自己的特定意义,不同于该表句词的成分词语的所有意义。因此,例如,如果英语hot-dog是个原创的表句词,它会有自己的一个特定意义,该意义不是“dog that is hot”的意义。然而,如果每个表句词都有自己特定的意义或者有不同于其成分词语的所有意义的意义,那么这一事实对于我们屈折变化的标准将会产生重要的影响。因为无论某特定语言中表句词的实际意义是什么,以及无论其成分词语的意义是什么,该特定语言中的说本族语言者都会知道这些意义,并且他们也都会知道在他们的交流中某些特定时刻是在使用表句词还是在使用一连串独立词语,因为他们会知道自己正试图表达什么意思。因此,他们将自动知道某特定一连串言语实体是应该作为一个表句词还是应该作为一连串独立词语来加以屈折变化。所讨论的这个特殊意义将决定言者是否采用屈折形式,而所采用的屈折形式反过来给听者传递所讨论的这个特殊意义。因而,说本族语言者实际对他们高度屈折变化语言的言语成分加以屈折变化的方式将有助于将他们的言语分别分类为表句词和词语,如果这样的话,该领域一位称职的语言学家只需要记录他们的言语实例,以便发现哪些是表句词哪些是独立的词语。至于我们,反过来只需对这些记录下来的实例进行序列—频率分析,以便从实证上查明置换经济原则是否确实有效。
总之,通过对高度屈折变化的语言如此采用上述屈折变化的标准,我们将十分有利地对我们理论上的置换经济原则借助实证检测加以核实。那么,我们下一步就是选择一门高度屈折变化的语言来分析。
很少有语言比某些印第安语言更加高度屈折变化的了,其中,没有谁会超过努特卡语,该语言已经由两位著名美国学者爱德华·萨丕尔(Edward Sapir)博士和莫里斯·斯沃德什(Morris Swadesh)博士精心地记录、描述、分析并出版了13。因此,对我们而言没有比选择努特卡语能够更好地进行分析。
如果我们选择规模适当的努特卡语并对之进行两种不同方法A和B的分析,我们在努特卡语中检测置换经济原则这个问题能够得到最简便的解决。
一个分析(下文简称A分析)是在将所有表句词分解成构成成分之后对于所选实例中未置换的连续词语的序列—频率分布加以分析,这就意味着,以英语为例,短语his hot-dog将包括三个不同“词语”:his,hot和dog。此A分析对应于工具分析中n个未置换工具的序列—频率分布。
另外一种分析(下文称作B分析)是表句词加上独立的未置换词语的序列—频率分布。此B分析认为英语短语his hot-dog包括未置换词语his以及表句词hot-dog两个成分。顺便说一句,努特卡语文本是以后一种形式印刷的,十分适合作B分析。这个B分析对等于我们工具类比中置换的以及未置换的工具在执行假设的Z项不同任务时所产生的序列—频率分布[12]。
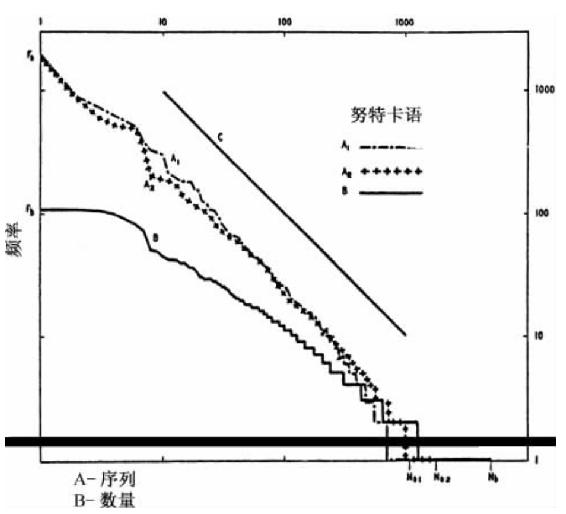
现在,我们转向具体的分析步骤。由于努特卡语印刷的形式,我们首先进行B分析。为了我们的分析研究,萨丕尔博士和斯沃德什博士选择并传递给我一些校正过的长条样文本,我们为了B分析从中选择了一个实例,该实例中连续表句词以及未置换的词语总计有10 000个。这个B分析中表句词及独立词语的序列—频率分布可见于图3-1中曲线B。要记住曲线B的全部数据是按照频率降序排列的,我们没有进一步区分词语实体的种类。
B分析完成后,我们下一步就是将B分析的序列—频率列表交给莫里斯·斯沃德什博士,他排除了其间逐渐出现的所有微不足道的误差,接着非常慷慨且不辞辛劳地将这些表句词分解成其构成成分,以便进行序列—频率研究的A分析。
斯沃德什博士在将B分析中表句词降解为构成成分时遇到了一定困难,此等困难可从英语的类似情况中得以最佳阐释。因此,例如,英语实体gosling可看作是由gos+ling两个成分构成的。第一个成分的意思是“鹅”,第二个成分的意思是“小”。那么问题出现了:即,在作A分析时(1)构成成分gos的出现次数是否应该算进独立词语goose的出现次数中,因为两者在语义以及历史上都是相关联的;或者(2)gos与goose的形式是否应当区别对待,因为两者在音位形式上是不同的。第一个做法(1)将会导致出技术上可称作努特卡语的“词素”(morpheme)序列—频率分析;而第二个做法(2)将会导致我们称作“词素变体”(varimorph)序列—频率分析(我们稍后将对这两个双引号里的术语作界定)。由于没有先验的理由确定哪种分析更佳,承蒙斯沃德什博士两个分析都做了。因而,图3-1中曲线A1代表了努特卡语的“词素”序列—频率分布,其中goose和gos的出现次数算在一起,而曲线A2代表了相应的“词素变体”分布,其中,goose和gos的出现次数分别计算。曲线B代表了B分析的序列—频率分布。
我们在审视图3-1中曲线时发现了一些有趣的关系。首先,A1和A2这两个曲线都非常接近于调和方程式的直线(这一点可以通过将两者与C线加以比较后看出,C线是以负斜率为1画出的,这是为了方便读者看得清楚)。这两条A曲线非常接近于直线是很有意思的,除了在本研究看来,它还表明努特卡语精巧的表句词结构背后还存在一个基本的直线性。
图3-1 努特卡语。(A1)“词素变体”,(A2)词素以及(B)表句词的序列—频率分布。
至于A1和A2两条曲线,“词素变体”(其中,“goose”与“gos”当区别对待)的曲线A2比“词素”分析的A1似乎有点更加接近于调和分布(harmonic distribution)。换言之,这些言语实体的形式分类比形式—语义分类导致出一个更近的近似值。幸运的是我们对于词语的全部研究到目前为止一直使用的是形式区分(即,“不同的形式意味着不同的语词”)而不是形式—语义区分,我们只在研究意义的频率时使用了形式—语义区分(图2-2)。
曲线A1的X-截面(Na1)比曲线A2的X-截面小,这一事实从后一个事实中不难理解,后一个事实是诸如goose与gos的区别在A2上保留而在A1上排除。另一方面,这两条曲线相交于中点是始料未及的,却同时表明词素在分解为其从属的形式语素变体时可能本身是遵从一个严格的原则,假如最省力原则果真正确无误的话,事实上也必将如此。
现在我们来看曲线B,它代表了表句词以及独立的词语,我们发现Fb和Fa之间的差别比nb与na1(是曲线A1的)之间的差别以及nb与na2(是曲线A2的)之间的差别要大得多。通常而言,似乎在曲线A转化为曲线B时,这两条曲线A在其频率总数上减少的程度至少等同于频率的幂。总之,词句实体在两条A曲线的任何一条曲线上出现得越频繁,那么它在表句词中就会越发频繁地得以应用。这一点我们可以从图3-1中曲线的属性上总结出来而无需进一步了解所涉及的具体词语实体。而且这一点正是我们必须能够得出的结论,这样的话我们就可以认为,就A词语分别置换为B词语而言,图3-1中数据代表了词语置换经济原则,这正如我们在工具类比中所期望的那样。因为我们只需指出,在双对数坐标图上,A在转化为B时每条A曲线的左上半部分下降的速度比B曲线下半部分向右延伸的速度要快得多。
因此,图3-1中数据提供了一个置换经济原则的肯定的实证检测。
虽然图3-1中每条曲线只在根据更高频率的A词语进入更多不同且更加频繁使用的置换中时都能够清楚地得以解释,然而为了说教的原因我们或暂时离题片刻,如果事实并非如此,那么B曲线会是什么样子呢?因此,假如大量的最稀少使用的A词语单独置换的话,那么nb未必比na1或na2大多少。这一点可能是真的,因为只出现一次的A词语至多可能进入只出现一次的B表句词中的一半,然而出现两次的A词语至多可能进入相同数量的B表句词,而B表句词可能只出现一次,此外,B曲线左上角部分可能与某条A曲线是一致的,这取决于该条A曲线所采纳的标准,直至遇到B曲线上开始置换的那个点为止,此时B曲线将会突然急剧下降。如果置换仅从A曲线的中间范围的词语发生,那么B曲线的中间部分也会出现同样的突然急剧下降。但是我们没有观察到B曲线的急剧下降,而且在B曲线的前十个或前十二个最高频率的词语之后斜率很少发生变化。因此,最高频率的A词语已被置换了。
除了B分析的前十个或前十二个最高频率的词语之外,B曲线是以非常接近于直线的方式下降,其负斜率明显小于1。这种基本上是直线的分布,我们没有在理论上从工具类比中预见到,如果不是为了机械工具应当如何置换而建立许多任意的专门规则,我们也不会预见到。然而,既然一个实质为直线的分布出现在B曲线上,我们完全可以追问事实为何如此。那么在回答时我们只能认为,正是我们在前文章节中讨论过的统一化之力与多元化之力也适用于此。也就是说,随着nb增加,频率将会根据它们固定的频率之幂而下降,假如我们认为,首先这两大力量彼此是一种乘方关系,其次A曲线是调和级数的真正近似值。或者,说的更简单点,我们可以认为nb的增加将会伴随下列事项发生:(1)A分析的词语一般将会按照其频率顺序被吸收进B分析的表句词中,而且被吸收的词语数量是与其频率的幂相对称的;(2)更高频率的词语进入带有频率逐渐变小的词语的愈发没有多大差别的更短的表句词中;而且(3)最终形成的表句词的相对频率将会是,它们的使用频率往往与它们构成成分的使用频率成正比[13]。除此之外,我们现在需要来介绍经济特化这个概念。然而在我们接下来讨论短语、句子和词素的整个过程中,记住上述三点很有帮助。顺便说一句,我们将在日后更加恰当的时刻讨论B分析的前十个或前十二个词语的自上向下的凹面[14],我们届时将会发现,该表句词是与所研究的更加“正式的”言辞相对立的“非正式”口头言语中十分普通的特征。
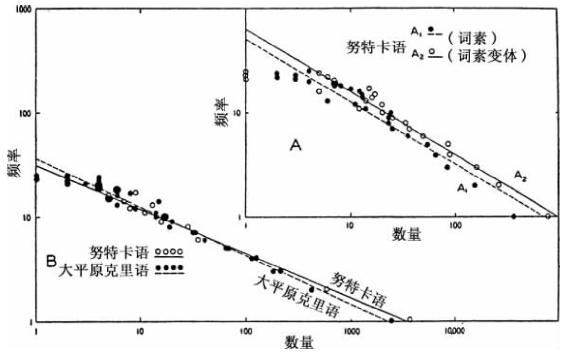
遗憾的是,其他语言没有完整的A组和B组数据。不过,数据B可从高度屈折变化的美洲印第安语大平原克里语中获得。而且在图3-2中我们呈现了10 000个连续表句词及其独立词语的序列—频率分布,这些独立词语在数量上是由笔者根据伦纳德·布卢姆菲尔德(Leonard Bloomfield)描写且出版的文本中挑选出的实例加以分析辨别14。图3-2的曲线将与图3-1中B曲线加以对比。
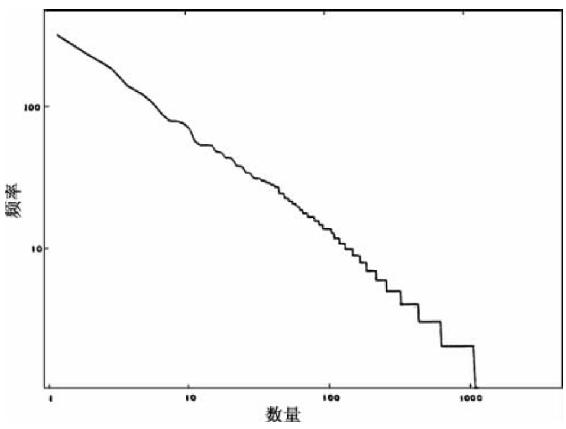
图3-2 大平原克里语。表句词的序列—频率分布。
在图3-2中我们发现图中曲线比努特卡语的例子更接近直线,尽管两者的斜率几乎相同。这就意味着,实质上的直线性也可见于高度屈折变化语言的B曲线。因此,我们不必非要用另一种眼光来看待努特卡语顶部的凹曲线,我们将在稍后陈述和讨论的口语实例中用同种方式看待可比较的顶部凹曲线。
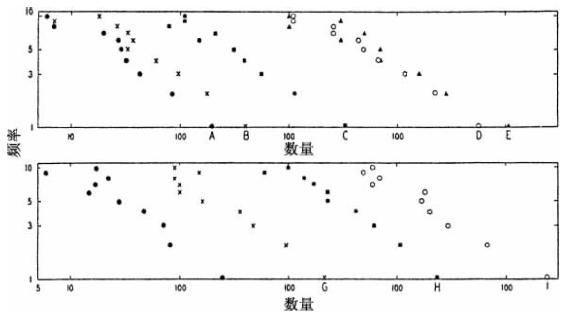
既然我们已经讨论了努特卡语和大平原克里语的B曲线的上部分,我们可以转向“阶梯”出现的下部分,因为如果B曲线基本上是直线的,相同频率f(或“阶梯”的“梯面”)的不同词语—表句词的数量N将会与它们各自频率f成线性的关系[15]。
图3-3包括一个右上角部分(A)和左下角部分(B),我们在左下角部分(B)里呈现了:努特卡语和大平原克里语的B曲线中相同频率f的不同词语—表句词的数量N,这是用横坐标轴表示,我们用纵坐标轴表示f,其中,空心点代表努特卡语而实心点代表大平原克里语。这两个部分的图形中,f的值都是从1到25,超过25的值有许多零星分布,这是意料之中的。
图3-3 努特卡语和大平原克里语的数量—频率关系。(A)努特卡语“词素变体”和词素;(B)努特卡语和大平原克里语的表句词。
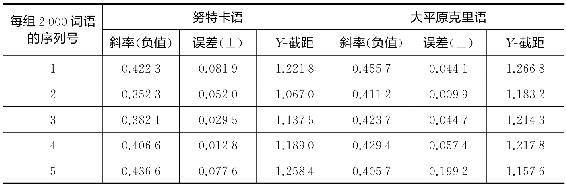
审视图3-3中B数据揭示了努特卡语和克里语两者皆呈现明显的直线性。此外,这两组数据在斜率和截距上没有多大区别。用最小二乘法计算,努特卡语的负斜率是0.424 1±0.053 9,而大平原克里语的负斜率是0.466 8±0.061 6。努特卡语和大平原克里语两者截距的逆对数分别为31.53和36.62。鉴于负斜率的均方根差的大小,我们不能断言这两组数据有显著的差异。一个可比较的相似性也见于构成上述两种语言各自10 000个样本的连续五组的2 000个连续词语的斜率中[16]。
以上两种分布遥远且明显不相干的语言之间存在上述的密切相似性,这一点没有先验的理由。事实上,除了最省力原则,直线性根本没有先验的理由,因为构建相同频率词语的数量随着频率而增加的某些语言是可能的。然而图3-3中两个B分布图中明显的直线性让人印象深刻,该直线性不仅让我们相信词语置换成表句词并非奇谈怪论,而且让我们相信语言实体的置换经济原则也并非异想天开。努特卡语和大平原克里语的斜率和截距中的一般相似性可能意味着,这两种语言的置换已经接近就我们工具类比所讨论的有限Z值。那么,图3-3中左下角B数据的论述就到此为止。
图3-3右上角标明为A的数据仍然有待论述,该数据代表努特卡语曲线A1和A2中各自的词素(实心点)和“词素变体”(空心圆)之间的数量—频率关系,正如图3-1所示以及就像图3-3中数据B那样标绘曲线图。“词素”的F值是从1到25,“词素变体”的F值也是从1到25,尽管后组数据从21到25是多变的。然而,在这两种情况中我们都发现了近似直线性。“词素”(A1)的最小二乘法负斜率是0.599 6±0.104 9,Y-截距(对数的)是1.702 82;“词素变体”(A2)的前20个点的负斜率如画线所示为0.601 7±0.069 4,Y截距是1.798 9。但是,如果对25个最小频率计算这些数据,其负斜率下降到0.471 6±0.121 2,Y-截距是1.588 3;尽管这条线与前20个点连成的线不是十分相称,然而其误差与A1的误差没有很大区别。
我们关注统计上微小细节的精妙奥秘,但是不应该将注意力从各种曲线的明显的直线性实质上转移,该直线性表明,言语流无论是分类成词语—表句词还是分类成“词素变体”或“词素”,取决于我们理论上在置换经济原则框架下所期待的有序的统一原则。
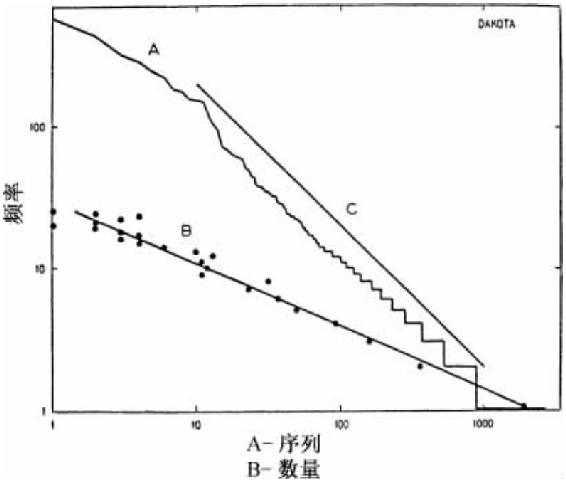
在离开美洲印第安语之前,为了图3-4更好地测度,我们呈现了选自艾拉·德洛里亚(Ella Deloria)文本中10 000个连续达科他语词语的频率分布图16。曲线A表示序列—频率分布,为了让读者看得更清楚我们画了一条-1斜率的C线;曲线B表示所有出现1到25次相同频率f的不同词语数量N。尽管曲线A上有弯曲部分,我们发现曲线B在表示样本中出现25或以下次数的不同词语的数量时是一条明显的直线。曲线B的负斜率是0.437 3±0.066 3,Y截距的逆对数是29.360。有趣的是,这些值与努特卡语和大平原克里语的对应值并没有多大区别[17]。
图3-4 达科他词语。(A)序列—频率分布;(B)数量—频率分布;(C)负1斜率的联想曲线。
回顾努特卡语的曲线A和曲线B,我们可以说所有三条曲线基本上都是直线,就25次或以下频率的词语而言确实明显如此;并且可以说曲线A和曲线B的构型都是我们理论上根据置换经济原则所预料的那类;我们还可以说大平原克里语中出现25次或以下的词语的分布图表明努特卡语曲线B在高度屈折变化语言的表句词和词语中不是独一无二自成一类的。另一方面,达科他语表明,美洲印第安语言的词语可能接近调和级数分布。
(二)词语经济地置换入更大的形态
我们使用“表句词”这个术语,在我们的使用中此术语意味着“表达一个词组或句子的言语实体”,这已经把我们迂回地引领到将词语安排或置换入“短语”、“小句”和“句子”等更大单位这个重要的主题,对于“短语”、“小句”和“句子”这些术语我们直接借用其现成用法而没有进一步加以界定。当然,这些术语并非不相关联也不是全面彻底的。因此,例如,一个句子可以包括一个或以上短语,或者一个或以上小句,或者既有短语又有小句。此外,句子本身被置换入更大的形态如段落和章节等等。
然而,我们当前兴趣不在于列举或描述这些更大的置换,而是在于探究这些更大的置换是否建立在言语实体的置换经济原则的基础上。不幸的是,这个问题的一个实际经验回答是目前不可能,因此据我所知完全没有定量的数据。但是即使缺乏此类数据,如果该原则生效我们就能够调查该原则对于短语、小句和句子的序列—频率分布的影响力。
我们首先转而论述短语这个问题,我们应该理论上预料到一些短语如at home或with me使用的频率相当高,而越来越多的许多不同词语使用频率越发减少直到我们遇到像underneath the lorgnette这类短语,其频率差不多可以忽略不计。此外,我们应该还能在理论上预料到,所有这些短语,无论是频繁使用还是非频繁使用,将会包括少量高频率词语与一些频率越来越减少的词语进行置换,事实上似乎正是如此,因为几乎所有短语的频率正好是与它们最不频繁使用的构成成分的频率相关的;短语with him要比短语with the whetlock使用更频繁,甚至是因为him比whetlock使用更频繁。尽管没有现成定量数据来检测上述理论推演的准确性,但是,由于我们对于言语的共同体验,这些推论本身并没有让我们感到荒诞。
正如我们已经对短语作出的论证,我们在细节上经过必要更改后对于小句和句子加以论证也会达到同样的效果,顺便说一下,这个论证只有通过研究言语实例中这些更大言语单位的相对频率才能经受住实际经验的考验,该研究任务量巨大,如果言语单位有充足机会去重复的话,研究任务必定确为庞大。
然而,或许可以认为,许多词语如with、without、when、where、until等等,主要都是作为更大的短语、小句以及句子单位的构成成分出现,上述词语对于这些更大言语单位的广泛用途而言拥有自身常见的高频率。总之,词语有高频率的用途是因为它们在自己从属的更大言语单位里有高频率的用途。但是,该观点并没有否定我们的置换经济原则。相反,根据置换经济原则我们可以在理论上将言语流看作是由置换的置换构成的,这反过来又是置换,等等。根据该原则,更小置换中相对更频繁的成员作为更大置换的成分将会相对更常用。正是这种存在于置换原则中的经济使得真正庞大的行为多样性来自基本上是非常少量的主要言语实体中。
然而,既然我们已经在理论上讨论了词语置换入更大言语实体,可是从词语本身的构成成分来分析词语这个任务还亟待完成,因为我们认为词语也是更小成分的置换。对于这个分析,有大量现成的定量数据。
(三)词素经济地置换入词语
我们认为一个词语包括一个或以上的词素。而且我们将采用词素的传统定义,即词素是具有可辨意义的最小言语单位。根据这个定义,词语un-tru-th-ful-ness可以说包括五个由连词符号连接的词素,因为这些成分都是最小的有意义的单位。同理,词语mousetrap有两个词素,词语cat有一个词素,可是cats或cat's或cats'各有两个词素。
至于词素是否根据置换经济原则置换入词语这个问题现在便出现了。也就是说,在相当高度屈折变化的语言如现代德语的词根、词缀和词尾方面,我们是否可以在理论上预见,一些不同的词缀和词尾将连同大量相对频率稍微较低的不同词根一起得到较高相对频率的使用?当然,根据我们对于德语或者任何其他类似高度屈折变化的语言的语感,上述理论预期并非怪诞,而且实际上在定量数据上我们稍后将陈述该理论预期确实可以实现。
在转而讨论几组实际定量数据之前,理当提醒几句。首先,有些语言如英语中有些词语难以形态化,例如,至于什么是处理千万个源自拉丁语的英语词语的最佳方式,我们可能并非意见一致,这类词语如constitution或difficult对于绝大多数说本族语的人而言在形态上其结构不是清楚的。选择那些在形态结构上总体明晰的语言来分析可能会避免这种难处。
即使在这些形态结构清晰的语言中,词语的词缀和词尾也存在另一个困难。因为尽管对于词语的词根词素是什么几乎不存疑惑,但是对于词缀和词尾的形态成分是什么有时候却存在诸多不解。因此,就现代德语词语wartete(“waited”)和fragte(“asked”)而言,对于如何分析和比较词尾ete和te或许存在一些疑问。可以想象的出,即便德语语文学家也许一致同意这一点,他们对于昔日相同词尾所呈现的类似问题大概从未达成共识,该词尾在哥特语中有时候是jis而另一些时候会变成eis,而且该词尾可能要么是指第二人称单数,要么是指名词的单数所有格:例如,nas-jis即为“thou savest”,sokei即为“thou sleekest”(译注:它们是指动词的第二人称);kun-jis即为“of the generation”,haird-eis即为“of the shepherd”(译注:它们是指名词单数所有格)。
只要词根词素总体上十分容易隔离,我们就能够首先通过尽可能多地了解“基本词根词素”(the bare root morphemes)的分布来解决词缀分类这个问题。我们将通过检查几种语言“基本词根词素”(以及其他词素)的数量—频率来开始我们的实证分析。
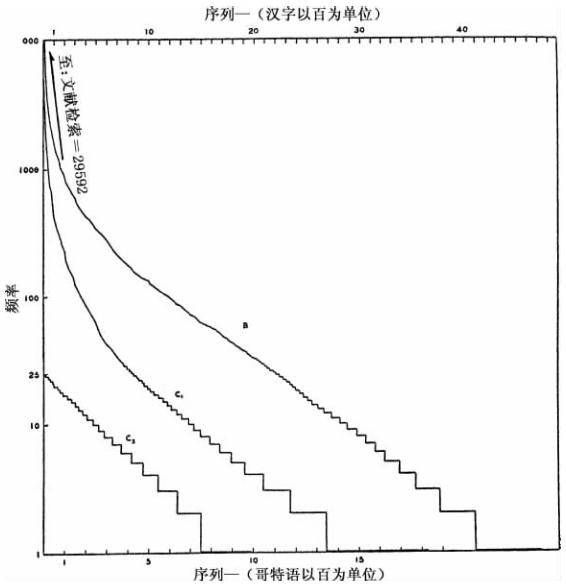
图3-5 (A)德语词干形式、(B)汉字以及(C)哥特语词根词素的数量—频率分布。
图3-5在双对数坐标图上呈现了三组数据A,B和C。A中实心圆点代表相同频率f的不同“词干形式”(如词根词素)的数量N,f值从1到1 000,这是由凯丁(F.W.Kaeding)统计约1 100万个连续德语词语后测定的(在f=5之上的圆点由各自的中项组计算所得)17。B中菱形点代表相同频率f的不同汉字的数量N,f值从1到100,这是从陈豪勤(译注:原文为chen2 hao2 chin2,此为音译)总计约4 500个不同汉字的样本中测定的18,该样本是他在上海商务印书馆出版的总数将近100万个连续汉字的著作。C中空心圆点代表相同频率f不同词根词素的数量N,f值从1到25,这是我本人从总数为58 293个连续词语的哥特语圣经中测定的19。在依次讨论这三组数据前,我们指出,每组数据以点连线基本上都是直线,而且斜率几乎相同。我们还没有计算这三组数据线的实际斜率,因为正如我们即将看见的,它们中有些点是不完全的。然而,在汉语和哥特语的例子中我们即将证实(在图3-6中)它们的负斜率将近为1。
现在至于表示凯丁的“词干形式”的数据A,我们发现,最下面的10个点代表从1到200(或者77.8%的词干形式)的频率以非常接近直线的形式下降,其负斜率在肉眼看来似乎与1相差不远。而最上面的两个点代表从201到1 000(或者总数的12.5%)的斜率,它们明显地沿着该条直线的左边下降,看起来很像是我们所讨论的这些组数据中落下了某些成员,这也不难理解,因为在此范围内某处应该放置的是凯丁排斥在外的那些最罕用的词缀和词尾。至于超过1 000以上的词干形式数量,我们没有绘图,它们的点沿着远离最低10个点形成的直线的左边而偏斜。读者如果欲知凯丁博士的研究详情,可以查看他现在已全文发表的数据。我们对其数据的兴趣仅限于这个事实,即他的词干形式(如stammformen)总而言之代表了词根词素,就相同频率f的不同词干形式的数量N而言,他的词干形式是直线性相关联的。
至于B的菱形点,是指相同频率f的汉字数量N,我们再次发现非常接近于直线性,负斜率是1。这些汉字与词根词素(这一术语不适合汉语)不一样。汉字更多代表的是在音节形态基础上的不同“意思”,两个或以上不同汉字可以由语音上相同词素表示。当前我们主要兴趣在于汉字分布的直线性和斜率。
至于C的空心圆点,代表哥特语的词根词素,我们发现其中存在一个与A或B的斜率完全不同的直线性分布。这些词根词素不仅包括词语的实际词根还包括“前缀”。将这些“前缀”包括在内是因为其中有些前缀作为词根形式有独立的用法,所有这些前缀都是出现了25或以下的次数。因此,词语fram-gahts中的前缀fram,也作为介词fram独立出现。因为在圣经的哥特语翻译的时候,前缀还是非常松散多变的,而且与我们所了解的正好相反,前缀仍然只是附着词根词素,所以我们将前缀统计在内。由于前缀数量有限,包括或排除它们并不会有明显差异[18]。
假如数据B和C的负斜率,比方说,的确是近似于1,那么相同数据的序列—频率分布在双对数坐标图上显然不会是线性的[19]。可是,如果我们在横坐标上以算术的方式绘制序列、在纵坐标上绘制对数,如同我们在图3-6中那样绘制,序列—频率分布在算术对数坐标图上将会是线性的。
图3-6 汉语和哥特语。(B)汉字与(C)哥特语词根词素(见文本)的序列—频率分布。
在图3-6中,曲线B代表了原版第73页至76页结语所汇总的几乎全部列表中汉字的序列—频率分布;详情可见第77页至116页。我们将会发现,该曲线向下呈凸面直到遇见第800个和第1 000个序列的点为止。在那个点之后,该线条明显地变成直线,而且当然是直到第1 170个序列时为止,该序列代表了f=100,这正如我们所预料的那样,自第1 170个序列点之后它与图3-5(其中绘制了“梯面”和“阶梯”)中垂直点相类似。因此,4 719个不同汉字中超过75%的都是直线式的。而且这个事实很有意思,因为正如我们在前文所指出的那样,这些汉字在语音上并非都是不同的。实际上,根据我本人已经作出的分析,当4 719个不同汉字减少至语音基础(即词素变体)时,它们的数量将缩小到1 136个[20]。只是汉字的算术对数的线性意味着什么仍然是一个公开未决的问题。无论如何,该线性是指一个规律性,一个与哥特语的没有什么不同的规律性,这一点从图3-6曲线C1中显而易见,我们现将转而讨论C1。
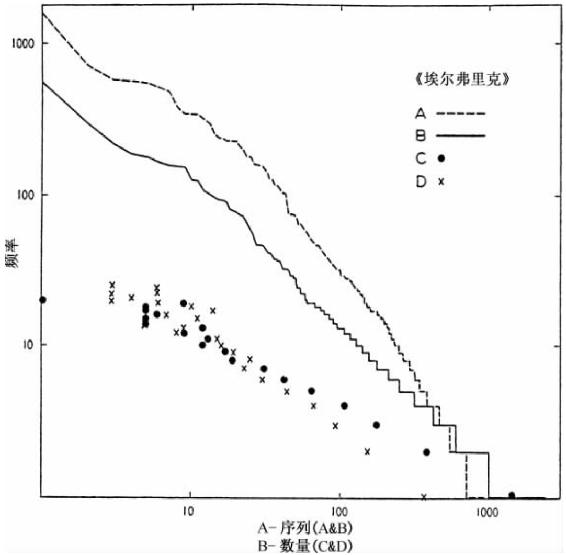
曲线C1代表下列两个词语实体的序列—频率分布,即①词根词素,包括词根和前缀,以及②“秃词尾”(the bare endings),除去词根和前缀之后的剩余部分。(从技术来看,这些“秃词尾”包括词干构成成分加上词尾,如-jis,-eis等等。)我们记得在外来专有名词或外来普通名词(如,Abrahamiis,praitoriaun)情形中,我们没有将来外词语分解为外来词根和前缀两部分,而是将之看作一个词根词素。
在词根词素加上“秃词尾”两者结合的序列—频率分布中如曲线C1所示,我们发现与代表汉语数据的曲线B在形态上存在一个普遍的相似性。
但是,如果我再仔细审视图3-6中曲线C1的较低部分(它所代表从1到25的频率并且与图3-5的空心圆点相类似),我们似乎侦查出稍微有点向下的凸面。在我看来,圣经中借用的词语和专有名词被包括在这些词根词素中却无法分解为哥特语词素,这可能是导致此处稍微有点凸面的原因,如果删除这些外来的词语和专有名词,凸面将会消失。曲线C2中呈现的是在删除这些外来的词语和专有名词后所有频率在25或以下的词根形式的序列—频率分布(我们已经任意地给第一个f=25的词根标记为序列1,这样的话C1和C2就能容易区分了)。曲线C2的确看起来相当笔直。这里我们可以说从曲线C2上省却一些“秃词尾”是不认真的行为,因此只有36个“秃词尾”出现25或以下次数(实际上只有62个“秃词尾”出现100或以下的次数)。
在我们察看到哥特语曲线底部的直线性时,该直线性在表示汉字的曲线B中也对应地存在而且它与凯丁的词干形式的直线性(图3-5)之间没有太大的差异,我们不禁为更小频率的哥特语词素的这种规律而动容。而且该规律性进一步引发出两大问题。
第一个问题是指图3-6中曲线C1的上部分,我们发现它显著地偏离了底部的直线,如果我们把“秃词尾”分解为各自形态部分,这个偏离将会更加显著。该偏离仅仅意味着“秃词尾”与底部直线性词根词素相比有着过高的相对频率,也就是说,在该条曲线底部直线性的基础上,该曲线上部的实体过多地频繁出现。就动态过程而言,“秃词尾”的过高频率可能意味着哥特语的复杂屈折变化曾是朝着随后的极度简化前进的。
不幸的是,哥特语的后伍尔菲勒斯(Wulfilus)语言学典范太微不足道且不置可否因而无法去证验这点[21]。在所有其他德语方言中曾发现此类屈折变化的极度简化,我们根据曲线C1上部分可能在哥特语中有望发现这种简化。稍后我们将审查某些这类其他德语方言的词素。
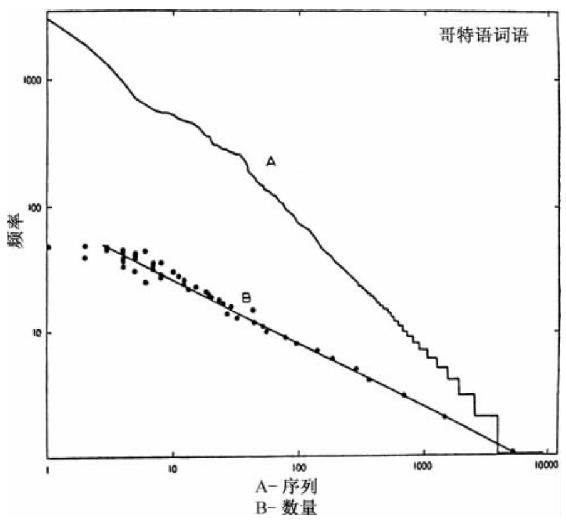
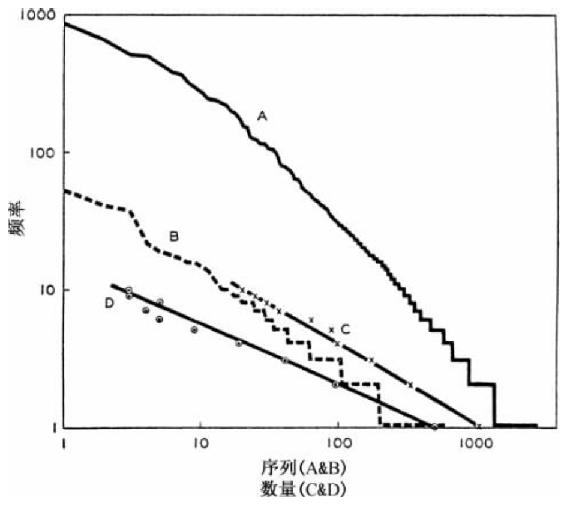
我们在离开哥特语词素之前必须调查总量为58 293个连续词语中完全屈折变化形态的9 125个不同哥特语词语的序列—频率分布,我们是从这些58 293个连续词语中获得词素分布的。因为我们记得实证检测置换经济原则不仅要分析词语的语素成分的频率分布而且还要分析词语本身的频率分布。显然没有现成的有关汉字研究的“词语”的数据。此外,凯丁的总量将近为1 100万个连续词语由于远远超过最佳规模样本的数量因而对我们没有多大实际用处。哥特语词语的哥特语频率分布既是现成的又是有用的,可见于图3-7。
图3-7中有两条曲线分别为A和B。曲线A代表总量为58 293个连续词语的样本中9 125个不同的哥特语词语的序列—频率分布。至于什么算是一个哥特语词语,我们只能说凡是在文本中印在一起以及分隔为一个词语的都算作一个词语;此外,所有在形式上不同的词语我们都看作不同词语,那些明确识别出的却没有语音意义的抄写变体除外(如,ei和e之间的传统差异,或者齿间擦音的清浊不同)。因此几乎不用篡改文本即可作出分析[22]。我们在图3-7中发现曲线A自始至终相当平直,而且除了40个最高频率词语之外尤其平直。此外,曲线A的斜率差不多是调和级数的斜率。
图3-7 哥特语词语。(A)序列—频率分布;(B)数量—频率分布。
另一方面,曲线B的横坐标轴表示相同频率的不同词语数量N,纵坐标轴表示所有从1到49的f值。没有词语碰巧出现50次,于是在50上方有大量零星散布的点。连接这些49个点的线是以最小二乘法计算并且根据方程式N·F2.025=7 040绘制的。指数2.025不能认为太多偏离2.00,这是理论上可预见的[23]。
根据图3-5、3-6和3-7中呈现的哥特语的词语和词素数据,我想我们可以合理地认为,置换经济原则适应于哥特语中词素置换入词语,同理经过必要细节修改,我们关于“词语实体”置换入努特卡语表句词的论述(图3-1)也是合理的。
然而哥特语在这个方面是独一无二的吗?
图3-8呈现了埃尔弗里克(Aelfric)古英语的四个分布图A,B,C和D。线条未中断的曲线B代表了选自斯威特(Sweet)的《埃尔弗里克布道文集》(Selected Homilities of Aelfric)(第2页第1行到第37页第98行)中10 000个连续词语的序列—频率分布,这是小马古恩(F.P.Magoun,Jr.)教授分析所得且交由我处理的21。曲线C上的实心圆点代表f值从1到20的相同频率f的不同词语数量N的数量—频率关系。曲线A代表上述成分词素的序列—频率分布,这是由我当时的学生奥托·E.舍恩—勒内(Otto E.Schoen-Rene)博士在马古恩博士的帮助下分析得出的。曲线D上的叉号代表f值从1到25的相同频率的不同词素的数量—频率分布。曲线B、C和D不释自明,它们非常类似于哥特语。(增加了曲线A是为了表明我们所有词素的序列—频率曲线绘制在双对数坐标图上的一般形态。)现在我们转而讨论其他数据。
图3-8 埃尔弗里克(Aelfric)的古英语。(A)词素的序列—频率分布;(B)词语的序列—频率分布图;(C)词素的数量—频率分布;(D)词语的数量—频率分布。
多亏我早前的学生们,才有了现成的九组英语和德语数据,当初搜集这些数据是为了更加综合地研究英语和德语的演变动力,这个项目如今已放弃。尽管限于空间不可能像图3-8那样给每组数据分别绘制单独图形,可是我们在图3-9中用对数坐标图上连续空心圆点呈现了全部数据中所有从1到10频率的相同频率不同词素的数量N(因此,读者可自行替换,记住所有情况中f=1的N值是在100到400之间)。尽管图形只给出10个最低频率,我们得赶紧补充一点,这些10个点标示了更高频率的斜率和直线性[24]。
图3-9 英语词素和德语词素。九位不同作者的数量—频率分布。
图3-9中曲线A和B是指更加古老的英语。曲线A代表12世纪《圣十字架》[纳皮尔(Napier)的文本,早期英语文本研究会(EETS),第103页]中6 900个连续词语的词素,这是由拉塞尔·F.W.史密斯(Russell F.W.Smith)为此目的挑选并且分析的,他的有关另一主题更加精彩的研究将在第七章论述。曲线B代表了13世纪英语《修女戒律》(Ancren Riwle)[詹姆斯·莫顿(James Morton)编,伦敦:坎登教区联合会,1853年]的前10 000个词语(省却来自拉丁语《圣约》的139个拉丁语插入文字,基督教注释者,以及宗教仪规礼制)的词素,这是由威廉·M.德夫林格(William M.Doerflinger)先生为此目的挑选且分析;所有诸如Paternoster,Ave Maria,credo等外来的拉丁语词语,是该文本不可或缺的组成部分,全都视作一个词语和一个词素。
至于德语研究:曲线C研究的是1874年帕德博恩市出版的《伊西多尔“驳斥犹太教”》(Isidore “Contra-Judaeos”)古高地德语(代表至迟8世纪后期德语)的4 825个词语,该数据是由莫雷·弗勒(A.Murray Fowler)甄选后分析的,他另外的研究成果我们在前文讨论过。曲线D表示《来自波西米亚的农夫》(Der Ackermann aus Bhmen)(公元1400年)中9 915个连续词语的词素,这是由肯尼思·拉杰斯泰特(Kenneth Lagerstedt)博士加以分析的。曲线E表示阿瑟·沃青格(Arthur Watzinger)博士分析的大约10世纪的《罗什忏悔录》(Lorscher Beichte)中568个连续词语[布劳恩(Braune,W.)《古高地德语读本》(Althochdeutsches Lesebuch),1928,第120页之后]。曲线F表示卡罗林·P.赖利(Caroline P.Riley)博士分析的13世纪中期伯特德·冯·雷根斯堡(Bertold von Regensburg)牧师的10 000个连续词语的词素[普法伊费尔和施特罗布尔(Pfeiffer and Strobl)编,维也纳,1880年,卷二,第24—26页;145—153页;165—173页;233—237页;265页第1行到第7行]。曲线G表示斯蒂芬(S.A.R.Stephen)先生分析的公元1445至1510年盖勒·冯·凯泽伯格(Geiler von Kaiserberg)牧师的4 628个连续词语的词素[L.达赫克斯(L.Dacheux),弗莱堡(Freiburg)编,1882年,第229—248页]。曲线H表示沃青格(A.Watzinger)博士统计的前文提及的伯特德·冯·雷根斯堡的布道(在前文所引用的书中)《五英镑的故事》(Von den fünf Pfunden)中5 030个连续词语的词素。曲线I表示斯蒂芬对于大约11世纪晚期著名的《威素布隆的布道》(Wessobrunner Predigt)和《奥特劳祷文》(Otlohs Gebet)所作的词素分析(布劳恩,在前面所引用的书中,ⅩⅩⅥ和ⅩⅩⅦ)。
总之,图3-9中这九组数据代表的是著名的语言学典范的较小样本,它们的时间跨度是从乔叟(Chaucer)直至目前的这么长时间,而且它们在地区和方言上迥然不同。它们特意不是按时间排序的。但愿读者能够审查这些数据并且努力发现任何真正重要的差别!就我所能发现的而言,这些数据基本上都是直线性的,只是斜率稍有不同,这一点可以在这些样本不同的字数总量上预料到[25]。除了上述数据,拉杰斯德博士分析了古高地德语的《班贝克的信念和忏悔》(Bamberger Glaube and Beichte),沃青格博士还分析了古撒克逊语《忏悔录》(Beichte)(布劳恩,在前面所引用的书中,ⅩⅩⅩⅩⅦ);这些研究结果与图3-9中呈现的非常相似,以至于他们的结论似乎不能为图3-9中可能会出现的拥挤状况提供合理解释。
鉴于这些数据(稍后将陈述相应的词语序列—频率分析),很难让人相信,就词语的词素结构而言我们不是在处理一个主要的动力规律。毕竟在先验上没有必要达成一致意见,因为其他词素分布也是有可能的,包括许多词素的出现频率恰好相反以及有些词素罕为出现。如果我们一方面比较图3-3中努特卡语的A和B分布图,而且另一方面,比如说,比较图3-8中埃尔弗里克的B和D分布图,我们会发现这些分布图在所有情况下都是直线性的;然而当我们历经由表句词到词语再到词素时,斜率是在有系统地增加。言语实体的置换经济原则的这个方面,我们不应该忽视。
既然我们已经表明词素也遵循置换经济原则,我们是否也可以说它们也遵循简略经济原则?答案是肯定的。词素的重要性随着词素频率减少而增加。支持这一相互关系的数据呈现在前文的出版论著中22,而且我们在本章已经提及的频率清单中的所有词素证实了这个早先的发现。总之,相同的经济原则适用于词素的以及词语的数量、规模和频率。
但是这些经济原则到词素这个语言实体时就结束了吗?或者说这些原则还会在语音体系的微小细节上产生影响力吗?而言语流是建立在语音体系的原材料之上。
(四)语音体系的经济
迄今为止我们已经审查了“词语实体”经济地置换入表句词以及词素经济地置换入词语。现在我们将转而讨论那些置换入词素(以及词语)的基本语音实体,并且想知道语音实体是否也像其他言语实体一样遵循相同的经济原则。这就给我们带来了如何界定语音实体这一问题。
我们可以将语音实体十分简单地界定为“有区别意义的最小单位”,即意味着它是在言者—听者关系中有区别功能的最小单位23。该定义的最大缺点是我们无法客观地确认言者和听者实际上可能或不可能有能力无论是有意识地还是无意识地加以区分。因此,我们将寻求一个在思辨上没有那么深奥却在操作上更加有用的单位。
通过介绍这个更加有用的单位,我们以诸如fun和run这组词语为例,它们除了各自第一个辅音之外完全是同音词。该类词的其他例子有babble和battle这对词,以及sin和sing这对词等等。我们将用“音位对立”这个术语来指称任何这样一对词语,它们意义不同但是除了一对不同的元音或辅音之外它们是同音词;这对元音或辅音,我们称之为音素。于是我们将音素界定为“有区别意义的最小单位,分隔一对不然是同音词的词语。”通过该定义我们能够隔离任何有现成词语的语言的音素。
音素显然只有借助具体语言的实际词汇事实才能得以界定,因为任何一种语音的音位区分可能在另一种语音中并非如此。因此,英语thigh和thy的音位对立向我们表明,第一个辅音(尽管写起来是相同的)发音不同,而且的确“分隔不然是同音词的词语”,因此,它们根据定义是不同的音素。然而在西班牙语中这些在语音—听觉上相同的声音没有分隔一对不然是同音词的词语,因此在西班牙语中,它们根据定义不是音素而是“音素变体”。
当然,我们不能由于缺乏合适的音位对立而赞同音素变体也不是在完整言语过程中具有意义的语音实体这一主张。相反,音素变体的不当使用可能会给言者带来麻烦[《士师记》(Judges)第七章第6页中42 000名以法莲人的悲剧命运就是个见证,他们由于不会发shibboleth这个口令的第一个辅音而被杀死]。我们或许只能说,我们赞同什么是音素(而且我们发现即便是语文学家似乎也同意什么是音素变体)。在我们已经多少探究了语音体系的动力之后,我们将不仅发现为何音素变体也能够区别意义,以及为何音位对立或许有望在语言中增多,以至于总的来说语言的音素语族就是其重要语音实体的语族。
记住上述考量,我们将在三个标题下审查语音体系的动力学:(1)置换语音实体的经济,(2)语音体系的四项基本原则,以及(3)其他各类因素。
1. 置换语音实体的经济
尽管语音实体置换入词语高度节省了人类言语的气力,但是我们得记住该置换不尽然是必须的。因此,假如我们想要10 000个不同词语的词汇,我们可能通过10 000个未置换的不同“词语语音”在生理机能上产生出那些10 000个不同词语。例如,美语元音在长度上千变万化以至于可产生出大量不同元音去充作词语语音[26]。假如在将一个音素长度延长至一个词语语音之际歇口气很有必要,言者可能特别装腔指明:“我歇口气之后将继续发这个相同的非变体的词语语音而不是一个新的词语语音。”除了长度上的不同我们还能够使用音高和振幅的不同来低声耳语或高声叫嚷[在这个起源于“韦伯-费希纳法则”(the Weber-Fechner Law)的原则范围之内]。总之,成千上万个可区别的不同词语语音的词汇在生理上和声学上都是可能的。
然而,一旦我们设想一个言语流包括上述一类未置换的词语语音,我们就能理解它难以驾驭。因此,林肯在非常短的时间内用音素置换的词语发表的《葛底斯堡演说》(Gettysburg Address)的“意义”,如果用词语语音演说很可能已经持续了好几个小时甚至好几天。既然在这种情况下,时间的跨度无论对于言者还是对于听者来说都是与物理功力量成正比例关联,那么,显然言语声音(或语音实体)置换入词语将会节省功力。因此,我们发现置换经济原则适用于表句词、词语以及词素,还可能有望适用于言语中基本的语音实体(无论怎样对之界定)。
这个置换经济因素带给我们有关最经济的数量、频率以及将要置换的语音实体的种类等各种有意思的问题。我们现在既从理论上而且如果可能的话又从实证上审查这些问题中的四点。
2. 语音体系的四项基本原则
语音体系有四大特征,是指存在四个基本的经济原则。第一个原则是某特定语音体系不同音素和音素变体的实际数量通常在20到60之间而不是成百、成千或成万。第二个原则是在广泛的可能语音体系中某些特定的元音和辅音(如a,n,m,s等)似乎都可见于大量不同语言中,因此就所使用的某些特定语音类型而言,语言似乎在某种程度上并非根据“机遇”来合理地解释。第三个原则是当不同语言碰巧使用差不多同样的语音实体时,它们往往使用这些词语的频率差不多是相同的。第四个原则是,每当在某特定语言中一个具体的语音实体在特定状况下改变它在某特定词语中的形式,它往往在同样状况下每隔一个词语中经历同样的变化[这第四个著名的事实是由19世纪卡尔·布鲁格曼(Karl Brugmann)率先精彩阐述的]。
现在我们尝试简要探究控制上述四大特征的动力学,首先想要知道为什么语音体系中不同语音实体的数量几乎是相同的。
首先,我们可以说成年人大体上拥有相同的发声器官和相同的变异范围,不管他们具体属于什么民族或种族。例如,黑人和白人差不多有相同的言语生理机能,一个人偏离标准的变异或多或少是在另一个人身上的变异复制而来的。对于生理机能的假定看法大致相同这个事实带给我们一个有趣的思考。因为如果不同民族或种族有大致相同的词汇需求,比如说10 000到20 000个不同词语,而且如果他们对于大致相同的生理机能假定都使用相同的置换经济原则,那么结果将会是各种语音体系中不同语音实体的数量大致相同。(该问题与前文根据n个不同工具能够执行的不同用途的Z值而讨论过的一个问题是相关联的。)因此,就我们所知,发现语音体系的不同实体的数量没有多大变化也就并非奇怪。而且即使不同言语群体的词汇需求碰巧变化非常大,语音体系规模的变化也不会因为置换原则的对数本质而必须相应地变大。
语音体系的第二个原则是指实际语音体系的具体语音类型。理解该原则的最简单的方法就是提出下列问题:各类语言将会从大量可能类型中采用何种特殊语音类型?而且该问题的答案,根据最省力原则,是每种语言往往会挑选那些在口头上发音和听觉上辨别都是最容易的那些语音类型。在发声器官生理机能假定相同的范围内,最简单的语音类型皆会相同,而且各类语言往往会选择一致的语音类型,如果不同群体的言语器官存在许多生理机能的差异,那么在那些群体的语音类型上可能也会存在相应的差异。此外,如果恰巧有大量难度大致相同的不同语音类型,那么一种语言可能选择某些语音类型,而其他语言可能选择其他语音类型。然而在这些资格限定中所选择的语音类型往往基本一致。至于这种一致在经验上的确证与否,我们了解到该主题没有实际的定量调研,尽管它给自身带来量化问题。因此我们可以随意在100种不同语言中挑选,它们的语音体系都已可靠地建立起来。那么我们使用国际音标,给每个符号列出不同语言的数量,这些语言的语音体系包含了该符号化的语音实体。那么最后我们将确定遍及这些100种语言的语音实体分布是否纯属偶然。这种调研是公开的。然而即便没有实际调研的结果,我们知道西方欧洲语言中一般存在共同的元音、复合元音、辅音和擦音。如果没有这第二个原则的存在那么将会很难理解第三个原则的数据,该数据现在来自我们刚刚讨论过的内容。
如果我们提出不同语音实体应该使用的最经济的相关频率是什么这个问题即时,第三个原则的本质便一目了然。在回答此问题时,根据最省力原则,我们只能认为(1)语音实体越简单就会使用得越频繁,而且(2)如果我们前面两个原则确凿可信,那么我们可能有望发现不同语言中类似语音实体将会有类似的百分比频率。(1)和(2)这两点在经验上皆可证明。
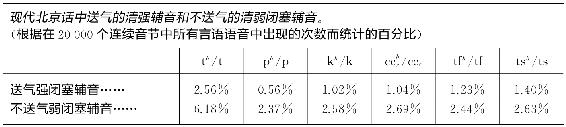
为了在经验上确证这第三个原则,我们将作如下研究工作。我们第一步将在某特定语言中挑选一组相应的音素对,合格的语音学家心中自然十分清楚哪个音素更容易发音,那么我们将发现,在更容易发音与更频繁使用之间是否存在任何正相关。为此目的我们在汉语的北京方言中挑选了六对送气的闭塞清辅音以及它们不送气的对应音素,如表3-2所示24。送气的闭塞辅音,用上标符号h标注,是该对音素中较困难的音,因为,首先它有一个紧元音或强辅音的发音,而它的对子有一个非紧元音或弱辅音的发音,其次,它的爆破紧接着是一个明显的送气(h),而这却是它的不送气弱辅音的对子所没有的。表3-2是指20 000个连续汉语音节的样本中的音素,我们在审查表3-2百分比时发现,在所有情况下,非送气闭塞音较易而送气闭塞音较难,前者的频率几乎是后者的两倍。这就证实了我们的假设。
表3-2
来自其他语言的有关送气和不送气闭塞音的数据与上文所述是一致的,而且已经在他处发表并详细描述了所涉及的语言体系25。
我们现在转而论述不同语言中相似语音类型之间百分比频率是否可能一致这个问题,我们在表3-3中呈现的数据是17种不同语言的成对浊闭塞音和清闭塞音t/d,p/b和k/g,这早已在其他地方发表了。审查该表揭示出每一栏的重要性大体一致。因此t的百分比约是6%,d的百分比约为3%等等。鉴于样本规模的不同、所检测的材料种类不同以及不同的文本抄写者所采用的分析方法不同,平均值和标准离差的显现似乎在统计上可能令人怀疑,但是将它们包括进来比解释它们的缺席更容易,而且如果不是很严肃地对待它们,也无伤大雅26。
表3-3
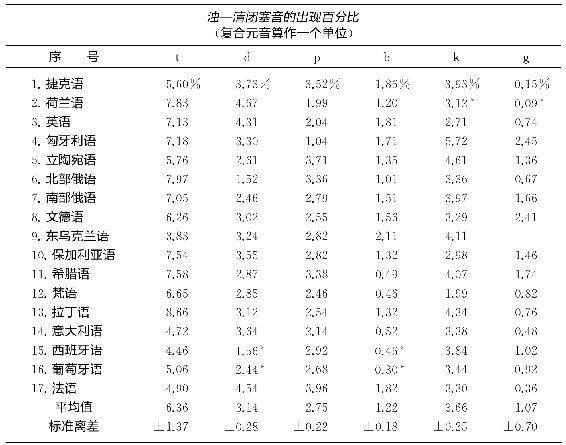
*用星号(*)标记的闭塞音是音素变体(参见文本),而所有其他的都是音素。
表3-3中甚至更加惊人的事实是,在这17个样本中清闭塞音t、p和k的频率几乎毫无意外地比它们对应的浊闭塞音d、b和g的频率要高[27]。这在概率法则看来,始料未及。实际上,清闭塞音比浊闭塞音频率更高的概率大概是百万分之五(或者,更精确地说是P=(0.508 5)(10-5),根据亨利·S.戴尔(Henry S.Dyer)博士和约翰·K.迪金森(John K.Dickinson)博士他们非常友善地统计出的这个概率),这正如在上述17种语言中浊—清闭塞音对子中所观察到的,而且是根据零假设即任何一种闭塞音都同等可能出现的前提下观察到的。因此,我们有正当理由想知道,大体而言,浊闭塞音是否比它们对应的清闭塞音更难以发出。事实就是如此,这是赫金斯(C.V.Hudgins)和斯特森(R.H.Stetson)在将这些辅音发出浊辅音时喉咙压低的精彩试验研究中所得的结论27。
读者可能想知道表3-3中的一致关系是不是因为不同语言(匈牙利语除外)之间存在着基因关系。答案是“非也”。例如,荷兰语和英语的闭塞音在历史上与其他语言的闭塞音不相同,如果只是因为格林定律的作用,拉丁语vita的元音间音t在意大利语vita中保留下来,而在法语vie中消失了,却在西班牙语和葡萄牙语中变成了擦音(如同英语thy中的th)。实际上,在历经几千年的时间长河中,尽管这些语言中有的可能已经构成了共同的族群,然而语音形式已经发生了相当大的改变,这种改变是可论证的。
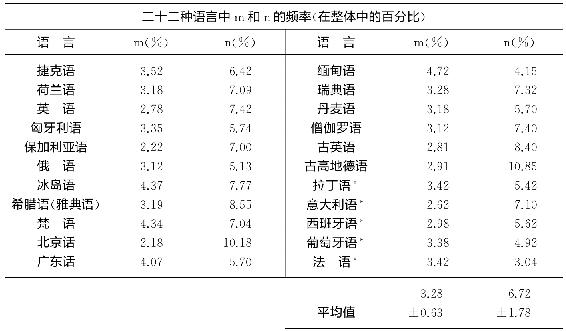
读者可能还想知道是否有其他语音类型的现成数据。应该指出除了闭塞音(如爆破辅音),言语语音在发音的长度和重音方面很可能存在大量的变化,元音在这方面的变化最为显著,以及流音、鼻音、塞擦音和送气音也或多或少地存在类似变化。然而,短元音与长元音和复合元音进行比较时,短元音明显更频繁,几乎无一例外。流音(如r和l)在语言中表现为更大的频率变化,而且除了鼻音m和n,其他音也是如此。正如我们在表3-4里22种不同语言的数据中发现的,m似乎毫无例外地比同一语言中的n频率要低,而且似乎在其他语言中还有差不多相同的百分比—频率,这些语言在地区和时间上有很大差异而且在某些情况下甚至几乎不相关28。
尽管我们已经为表3-4中数据呈现了平均值和标准离差,我们再次提醒读者,基础样本在规模和记录技术上差别很大(如,对于什么是元音、复合元音、三合元音的处理方法不一致,于是这种不一致将会多少影响样本的规模并进而影响它的百分比);此外,百分比很可能随着挑选的文本风格不同而变化。假如我们有某一特定语言的十二个不同言语风格的样本,每个样本有10 000个音素这么长,并且我们用标注的语音变体描述其音位,那么我们很可能获得了该语言的重要音值,我们可以将这些音值与用类似方法得到的其他语言的结果加以比较,这样做非常有利。然而尽管那样,适当的警告也是必需的。因为毕竟某些语言中的某些音素可能频率过高因而正处于形式变化纠正期(如,语音变化)之际,因此某个超过平均值的特定频率可能仅仅暗示该音素处于不稳定状态。这层考虑把我们领向语音系统的第四个原则即语音变化,它与其他三项原则密切相关。
表3-4
* 来自罗杰斯(F.M.Rogers)的分析。
我们提出下面这个显然的问题来看待第四个原则:随着旧词语要么简化要么消亡而新词语不断产生,词素频率的百分比在动态进化过程中会发生什么变化?显然,除非所有言语变化是在保留先前存在的语音百分比这个严格限定条件下产生的,否则这些百分比将会起伏波动——而且甚至以很大的幅度在波动。换句话说,除非语音体系中有某种调节机制在校正过高或者过低的频率,否则我们应当有望发现某种特定语音类型的频率将会在某特定时刻不同语言之间产生非常大的变化,而且同种语言在不同时刻也会产生非常大的变化。
事实上,语音变化的形式中确实存在一个调节机制。因此,例如,假设某特定长元音频率变得过高那么它的音长可能会变短;一个频率过高的d可能会弱化成t。一般说来,一旦一个语音实体的频率的增减超过了其特定形式允可的阈值,作为补偿它可能有望在形式上也会发生变化29。一旦这样的语音实体发生了具体的语音变化——如d变成t或者相反——那么包含该变化语音实体的每个词语也会产生变化[28]。我们称之为语音变化的条理性。
语音变化条理性的例子确实多得很。读者自己可以查阅任何一种语言的有关历史文献所确证的这类例子。这个条理性是由卡尔·布鲁格曼(Karl Brugmann)及其学派首先严谨地提出来,而且在克莱德·克拉克洪(Clyde Kluckhohn)博士看来,这个条理性第一次揭示了整个生物社会领域的严密的行动法则,它是比较文献学和语言学等不同历史描写领域中穷尽性研究的重要前提。从这些积累的大量例证中,我们仅仅随意挑选了一些例子加以论述。
因此,古英语ū这个音素变成了ou(有时候写成ow)。由于这个变化,mūs变成了mouse,hūs变成了house,lūs变成了louse,cū变成了cow。尽管这种变化将ū从古英语中消除了,但是这种消亡只是临时性的。因为随后音素ō变成了ū,如gōs变成了gūs(写成goose),而且mōna变成了mūn(写成moon),等等。这些例子特别有意思,它们阐释了某特定语音类型如ū由于自身的不稳定性可能变成ou,只是给新来的ǖ挪出空位,而后者是从昔日语音类型ō变化而来的。于是在这个由ō到ū的第二次变化出现在古英语中之后,这个往昔的语音类型ā取代了遭抛弃的语音类型ō(如古英语中stān,rāp和gāt如今都是带有ō的发音出现在stone,rope和goat中)。那么语音体系的第四个原则语音变化的条理性就论述到此。
因此,我们可以这样概括,语音体系在刚刚阐述的音位系统四项原则范围内改变其构成分的形式。所以,(1)语音体系将不同语音类型数量限定在20—60个左右;(2)世界上语音体系似乎青睐于使用最简便的语音类型;(3)语音类型的频率与其可比较的功力系数成反比例关系;以及(4)语音形成的变化始终在一个语言的所有词汇中有条理性地发生,即如果某特定变化在特定一系列条件下出现在一个词语中,那么所有其他词语只要存在相同条件亦会发生同样的变化。尽管语音变化一直在发生,我们千万不要忽视某些当今语音表现形式中存在重大的古代遗迹,因此mouse中的m和s很可能在该词语中存在了数千年之久[29]。
3. 其他各类因素
既然我们已经概述了语音体系的四项原则,我们再回到语音实体、音素以及因素变体这个问题。我们首先来证明为什么音素未必是唯一的有区别意义的最小单位(正如某些音系学家曾经主张的);其次要证明音素变体为什么也会是有区别意义的最小单位(正如大多数音系学家否认的)。
我们选择英语这一语言来开始论证,英语中d是一个音素(如,bad对bat)。接着我们假定由于语音变化所有单词的词尾d都变成了ø这个形式,此形式对于这种语言来说是全新的(例如,bad变成了baø)既然这种新的形式只会出现在词语的词尾,并且既然没有d会出现在词尾,那么整个这种语言中也就不存在一个可以表明d和ø之间差异的音位对立。因此,根据定义这个全新的形式中ø不会是一个音素而是d的音素变体。然而我们如何知道ø是d的音素变体而不是其他音素如l,m,n,o或者p的音素变体呢?显然,我们知道ø是d的音素变体只是因为我们知道在历史上它是由d发展而来的;假如缺乏这种历史信息我们自然无从知晓。此外,在词尾位置的d变成ø之前,那些词尾位置的d仍然是音素,因为根据定义它们还是“具有区别意义的最小单位”。然而在变化发生之后,ø是什么?对我们来说,它仍是一个有区别意义的单位,因为我们发现在假定的colø(cold)与cōl(写成coal)之间存在着差异。
尽管我们已经将语音实体界定为有区别意义的最小单位,但是我们还得证明在语音实体成为有区别意义的最小单位之前实际的音位对立必须存在。据我们所知,语音实体的置换才是最重要的。音位对立的存在是偶然的。很明显,几乎所有语言都有用于解释大多数不同语音实体的语族的音位对立。但是我们认为这是由于置换经济原则导致的结果。在产生更大的语音实体置换之前产生较小的置换,一般来说都是经济的;因此,长远来看,小置换可能出现并充作某特定语言的语音体系中大多数明显不同的语音实体的音位对立[30]。
如果我们进一步审查“音素理论”,我们会发现一个常见的信念,用伦纳德·布龙菲尔德博士的话(第83页)说32:“音素与该语言中所有其他音素有着显著区分”。这个看法是错误的。例如,我们已经指出,德语中短音ǎ和长音ā是不同音素。埃伯哈特(Eberhart)博士和科特·兹维尔纳(Kurt Zwirner)博士在他们一系列精彩的音素测定研究中发现,在实际言语样本的表音法记载中,不同元音音位发音长度的频率分布遵循一条“常态曲线”;ǎ和ā的之间的唯一区分在于它们各自分布的方式中,因为,有些稍长的ǎ的发音事实上比有些较短的ā的发音还要长33。因此,在一个纯粹的声学基础上如果不知道置换的余项(或分布的方式),音位ǎ并非总是与该语言中所有其他音位有着显著区分[31]。
甚至在进一步深入了解语音体系的细枝末节特别是变化不定的音长这个问题时,我们呼吁大家关注莱曼(W.P.Lehmann)和黑夫纳(R.M.S.Heffner)杰出的实证研究,他们发现了特定元音往往在末尾的浊塞音之前比在末尾的清塞音之前发的音要长些(如,在d,b和g之前比在t,p和k之前的发音要长些)34。因此,正如这两位实验者所指出的,浊塞音相对而言频率较低,在元音的音长及其后塞音的频率之间确实存在相反关系,他们发现的这一种相反关系就d、b和g逐渐减少的频率而言也是真实有效的。因此,元音在频率更高的d之前比频率更低的g之前的发音要短些(读者会发现在连续发出tot、tod、tog或者pit、pid、pig这些音节时元音是越来越长)。元音的音长与其后末尾塞音的频率之间存在的这种相反关系(上述实验者没有明确界定将这种相反关系归因为最后这个辅音的发音“技巧”不同)与赫金斯博士和南博斯(F.C.Numbers)博士的实证研究密切相联35。
因此,赫金斯博士和南博斯博士在他们开拓性研究中调研了失聪者的言语,发现失聪者在发元音和辅音的错误是随着元音和辅音相对频率减少而增多。上述实验者对于错误和出现频率之间的这种相反关系提出了语用困难量表。将此发现与前文莱曼—黑夫纳(Lehmann-Heffner)发现连接起来,我们可以认为,当言者接近一个更罕见同时有更困难的末尾塞音时,他的言语流就有准备地放慢速度,结果导致前面元音音长相应地增长了。其中,波恩市音系学家蒙泽拉斯(Menzerath)博士和葡萄牙德拉赛达(A.de Lacerda)博士已经证明了后一个语音实体影响前一个语音实体的发音36。
在讨论这些各类详细的语音问题来说明省力经济时,我们千万不要忽视为了具体置换选择具体语音实体这个基本问题,通过尽量使得言语流中连续词语有区别以便给听者节省功力,因为显然一个过于紧密的同音词并列或者“要不然是同音词”的过于紧密的并列可能会给听者制造混乱。我们因而揣测存在一个调节原则控制了置换中语音实体的分配,这样言语流就会丰富多样而且完全明确。因此,连续词语在许多不同置换位置中可能不是由一个而是多个不同语音实体区分开来的,音位的错误发音可能给听者很少或者没有造成误解。“语音变化”这个主题承蒙我当时学生富兰克·皮亚诺(Frank Piano)调研的,他分析了埃尔德里奇列表中第二个样本连续11 538个词语中2 544个不同词语。在将这些2 544个不同词语根据国际音标精简之后他发现了23对同音词变得相同,只剩下2 521个语音上不同的词语。排除了l和r之间的语音差异(那么call和core将变得相同)以及排除m和n之间的语音差异(影响了诸如some和son之类词语)之后,不同词语的数量降低到只有2 481个。再进一步排除了所有短元音之间差异(那么bit,bet,bat,but,bought将变得相同)之后,不同词语的数量降低到只有2 460个。接着(不顾一切地)皮亚诺先生让所有长元音、短元音和双元音变得相同,结果无论怎样没有任何元音区分后仍然有2 264个不同的语音形式。从该研究中显然可见,在实际言语样本中词语不是由一个而是许多个差异区分开来的,语音上非常相似的词语不可能经常出现在同一文本中,这是因为从听者的角度来看存在着很明显的经济因素。这个问题似乎值得进一步研究37。
语音学上有许多其他诱人的问题,而且有太多详细的研究我们还没有提到过。多亏卡贝尔·格里特(W.Cabell Greet)博士精心编著的《美国语》(American Speech),许多重要论文都可在这本刊物中查到,它同时包含了出自经验丰富的特雷维勒(S.Treviño)之手的一个该领域完整的、连续的参考文献。此外,还有贝尔电话实验室持续的研究,这在他们的刊物中已有汇报。马克·H.李德尔(Mark H.Liddell)博士的实验研究仍然很重要。国外研究有法瑟·A.格梅利(Father A.Gemelli)(意大利)的电解分析研究,德拉赛达博士(葡萄牙)的新喷墨纪录技术,琼斯(D.Jones)博士和琼斯(S.Jones)博士(英格兰)的研究,潘坎塞利·卡齐亚(Pancancelli-Calzia)博士(德国)的研究——仅列举一些此前未提及的研究。在美国,人们可能记得托马斯(C.K.Thomas)博士,诺尔(F.H.Knower)博士,希尔(A.A.Hill)博士,孟肯(H.L.Mencken)博士,科万(F.S.Cowan)博士,怀斯(C.M.Wise)博士,里德(W.A.Read)博士,纽曼(S.Newman)博士,齐默曼(J.D.Zimmerman)博士,马隆(K.Malone)博士,德费拉里(H.Deferrari)博士,路易斯·庞德(Lousise Pound)博士,弗尔克(C.H.Voelker)博士,帕门特(C.E.Parmenter)博士,普利(R.C.Pooley)博士,利布基(W.F.Luebke)博士,以及赫尔岑(L.S.Hultzen)博士——以及还有本文现在讨论的那些学者们的研究。这样的列举也无法穷尽。
请大家注意语音学这个广阔领域中大量优秀的实验性研究和理论性研究,我们大胆推测这个越来越多的精心观察与阐释或许在某种程度上对于生物社会研究具有一定价值,这一点恐怕是一些语音学家本人也未曾料到。而且就我们对于这些研究的了解,没有哪一个与我们的最省力原则相悖。
此刻,有人或许觉得我们对于语音体系的结构和动力学的兴趣有点过头了甚至有点迂腐。然而,如果从整个有机世界来看待语音体系,而且如果记得我们对于语言体系的讨论是在讨论一群不同类型的物理行动的经济,以及这些类型显然存在“有限数量的法则”,人们或许不再觉得我们兴致过分了。这样的法则并非是语音系统独有的。例如,在所有无止境的各类动植物中,所观察到的生殖核染色体数量的全部范围仍然有限;根据怀特(M.J.D.White)的单倍体数据,只有5%的生殖核有4个以下染色体,75%的生殖核有20个以下染色体38。可是在这个出现了所有且无限的化学变体的狭小范围内为何应该存在这个“有限数量法则”?如果我们将染色体视作物理行动的“类型”,或许音位的“有限数量法则”的原因适用于染色体有限数量。果真如此,言语的结构和行为只不过是所有生物过程的结构和行为中一个特例而已(参见第五章和第六章)。
因此,刚才论及和阐明的语音结构四项原则大概可适用于人类言语范围之外。或许同样如此的还有简略法则、效益递减法则及其多能经济原则和置换经济原则,这些我们已经就言语方面作了论述。同样如此的可能还有特化经济原则,该原则我们已经作过描述,而且我们现在就转而详细地讨论和阐明这一原则。
三、特化经济原则
在我们详细审查词语以及其他言语实体的置换经济原则时,我们多少有些忽略了我们的工具类比,工具类比最初不仅用来表明言语结构这些问题的本质而且表明它们可能的解决方法。我们没有必要再去概述工具类比中意指“最小等式”或简略原则那部分,因为这些观点的适用性已经在言语中得以检测。但是或许有必要记得我们仍然关注效益递减法则,我们记得该法则是在三大框架下讨论的,(1)多能经济原则(其中,工具或词语的不同用途或“意义”随着其频率增加而增加),(3)置换经济原则(我们刚刚结束了对它的讨论),以及(2)特化经济原则(我们现在来考量)。
机械工具特化经济原则的主要特征既不多又简单。因此,一旦由于这样或那样的原因为了执行具体任务而形成的几个工具的置换使用得越来越频繁,最终频繁到设计和采用单独专门性工具执行该置换迄今所履行的具体任务可能更加经济。这种单独的特化的工具取代工具置换,代表了特化经济原则的运用。
这项原则在具体实践中的一个重要长期结果就是有些古老且简略的工具往往在木板上下行,离工匠渐行渐远,这些就是“变得过时的”或衰老的工具,另一个后果是更新的而且还未完全简略的专门性工具将会沿着木板上行,这些则是新生的工具。这两个后果的最终结果是,在我们沿着木板远离工匠时,我们应当遇到一个混合体即一方面是陈旧简略的衰老工具和另一方面是更新更大的新生工具,而且由于当时假设的原因,这个混合体将会相应地包含愈发少有的衰老工具和愈发增多的新生工具。
假如我们现在将上述机械关系转变为言语术语,我们是否可以说,在我们进入更加罕见词语的领域时,这些词语往往是包括词汇表中愈发更多的更新且更长的词语,就像工具类比所揭示的那样?我们来看看事实究竟如何。
承蒙我以前的学生丁乃通(译注:原文为Nai-Tung Ting,此为音译)博士,他担当重任确立了将近6 000个不同词语的采用日期和采用源头,这些词语是埃尔德里奇对于美国报纸英语大约44 000个连续词语进行频率分析中的(在前文所引用的书中)。为此目的,他使用了《简短英语词典》(The Shorter English Dictionary)(两卷本,牛津,1933年)而且还查询了《新英语词典》(The New English Dictionary)。由于埃尔德里奇列表中的词语是以完全屈折形式给出的,这些词语的日期和起源是由它们的词根而不是前缀或后缀决定的(如,build,real,promise决定了builder,really和promising的词龄和词源);复合词的词龄和词源是以其重读成分的词龄和词源为准(参见下文)。假如词语的不同形式和意义有不同的日期和来源,以最早的词龄和词源为准。对于有疑惑的起源和词源作了适当的标注。我审查了丁博士的大部分分析,发现其分析完美无瑕。
接下来就是数据分析,其结果呈现在图3-10中四个不同图形,分别标为A、B、C和D39。
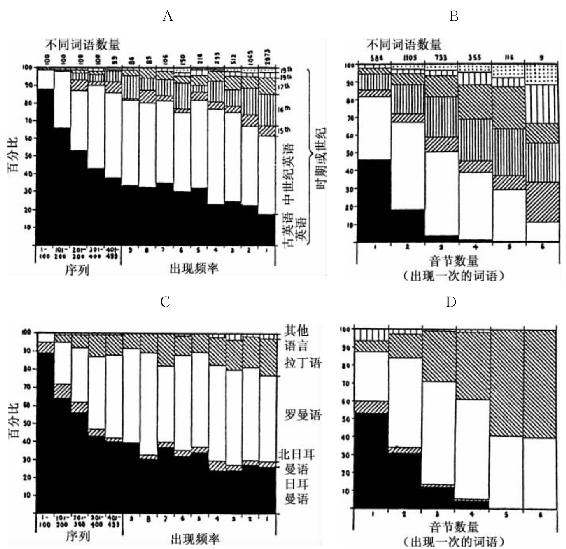
图3-10 英语的文化—年代层(埃尔德里奇分析)。(A)全部出现的词语的年代层;(B)根据音节大小,所有出现一次的词语的年代层;(C)全部出现的词语的文化层;(D)根据音节,所有出现一次的词语的文化层。
图A中从左到右有14个垂直立柱。最初的五个立柱共同代表了前499个最高频率词语(从序列1到499),它们包括所有出现10次或者以上的词语;总之,这些连续五个立柱分别指连续100个序列的最高频率词语,第五个立柱除外,它是指99个序列(即,从401到499)。在这些最初五个立柱之后,还有九个立柱,从左到右如图所示是指从那些出现9次到那些出现1次的相同频率不同词语的数量;每个立柱的底部是该立柱所指的频率,而顶部则是有着该频率的埃尔德里奇列表中不同词语的数量。
图A14个立柱中每一个在纵向上都代表了按照词语在语言中年龄的词语百分比。因此,底部(黑色部分)是古英语时期(包括后期古英语)就有的词语的百分比;其次(白色部分)是中古英语时期(包括早期和晚期中古英语)吸收的词语的百分比;而最上面,如图所示,则是包括从15世纪到19世纪所吸收的词语的百分比。20世纪吸收的词语在数据上可忽略不计。所有百分比的计算是基于有现成必要信息的词语总数得出的。并且排除了所有日期不确定的词语(它们在出现一次的词语中占3%以下,在出现两次的词语中占1%以下,随着频率增加,该百分比越来越小)。
浏览图3-10中的图A足以表明,频率越低的词语就有越多的部分是后来吸收的。因为我们知道,频率越低的词语往往是长度越长,所以我们可以有望发现词语的长度和年龄之间存在相反关系——实际上图3-10中图B数据也正如此,我们在图B中呈现了对于埃尔德里奇分析的出现一次的大约3 000个不同词语所类似导出的百分比(根据词语按音节的大小从左到右排列,分别是从1个音节到6个音节,有7个音节的词语只有两个)。
图3-10中的图B显示,出现一次的词语(按音节)的大小与该词语在这门语言中存在的时间长度之间存在一个明显无误的相反关系。尽管图B只是指大约3 000个出现一次的词语,但是我们记得这几乎是全部分析的约6 000个左右的一半。那些频率大于1的词语也揭示了同样的相反关系,尽管限于篇幅未将它们包括在此。
因此我们可以说,埃尔德里奇数据在实证上确证了特化经济原则,正如按照词汇表中词语的新词和旧词所表述的那样。
趁我们还在讨论这个主题时,我们转到图C和图D,它们是指所研究词语的起源或出处,此外它们分别与图A和图B相似。所选的起源主要有:常见的日耳曼语、北日耳曼语、罗曼语,以及拉丁语(该类别即所有其他的语类包括希腊语、汉语、希伯来语、凯尔特语、美洲印第安语、东印度语以及所有起源不明确的词语)。尽管采用的时间在图形上被忽略了,然而日耳曼语总的看来是最早的,接着绝对是北日耳曼语以及罗曼语。但是这种关系只是“总的看来”,因为有些拉丁语很早就借入英语,并且我们仍在借用罗曼语和北日耳曼语。
有意思的是,图A和B的数据表明常见的日耳曼语矩阵(即,该语言中最早时期已经存在的起源于日耳曼语的常见词语)往往是最短的。总的看来,从北日耳曼语、罗曼语和拉丁语吸收过来的词语属于较低频率的词语。在这个方面,有几点提请大家注意。首先,从这些不同的语言中借词这一做法很久以来一直在进行,因此,我们不可能对于具体外来词的来源精确地联系到某一具体时段。其次,根据我们的分类方式,任何新的复合词语如果是在较晚期的时候从较早期的成分中创造出来的,那么都将以这个较晚期的日期归属为它的采用日期;然而,复合词的起源是与其重读部分的起源一致:因此,例如,词语lineman据我们所了解的记录是在1858年进入英语的,并且由于其重读部分是罗曼语成分line而不是日耳曼语成分man,该词语lineman就归类为19世纪来自罗曼语。同理,highwayman是1649年记载的一个日耳曼语的三音节词语。当然,这些复合词数量不多;如果将它们全部排除在外也不会对我们的数据研究造成多大改观;因为无论有没有复合词,词汇由于在其较低频率范围内吸收新词语而变得丰富起来。
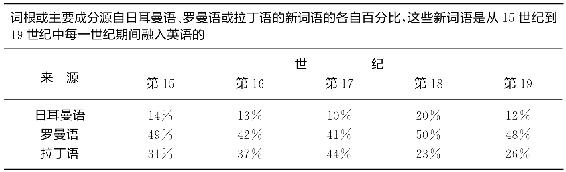
在我们离开埃尔德里奇词汇这个主题之前,也许有必要呈现从15世纪到19世纪这五个世纪期间源自日耳曼语、罗曼语和拉丁语的新词语实际百分比(我们对北日耳曼语和其他语言忽略不计,因为它们数量相对稀少)。这些百分比见于表3-5,我们从中发现,日耳曼语和拉丁语两者每一个世纪都浮动很大,而罗曼语浮动稍微小些。日耳曼语在三个世纪前顺服罗曼语和拉丁语,之后于18世纪达到顶峰;或许日耳曼语的这一涌现与发端于18世纪末的浪漫主义运动时期有关联,该时期极力反对前几个世纪的古典拉丁语。
表3-5
对于一个总数为40 000个不同连续词语中实际有6 000个不同词语的小样本而言,我们千万不要过于深入追究细节。源自桑代克博士的20 000个最高频率词语(在前面所引用的书中)的信息给予的指导可能更让人放心。尽管分析桑代克列表中全部词汇将会是一项艰巨的任务,但是此类分析很可能会给文化影响力专业的学生提供一个其价值简直难以想象的度量标准[32]。
言词部分不同起源的另一个例子——这次是指哥特语分析的词根词素——呈现在图3-11中,该图可以与前文图3-10中的图C相媲美,是指哥特语词语的词根的起源,不包括史上外来的普通名词和专有名词。众所周知,哥特语的词根主要是印欧语的起源,这就意味着许多哥特语词根在其他非日耳曼语的印欧语言中有对应词。有些哥特语的词根也是日耳曼语的起源,即这些日耳曼语词根只见于日耳曼语的各种方言中。还有一些哥特语之外不存在的独特的哥特语词根。最后,有些词根历史上是借自拉丁语、凯尔特语、希腊语、斯拉夫语,这些外来语随后被彻底同化了且转化为本族语,如同早起的罗曼语被彻底同化后进而转化为当今英语的本族语。
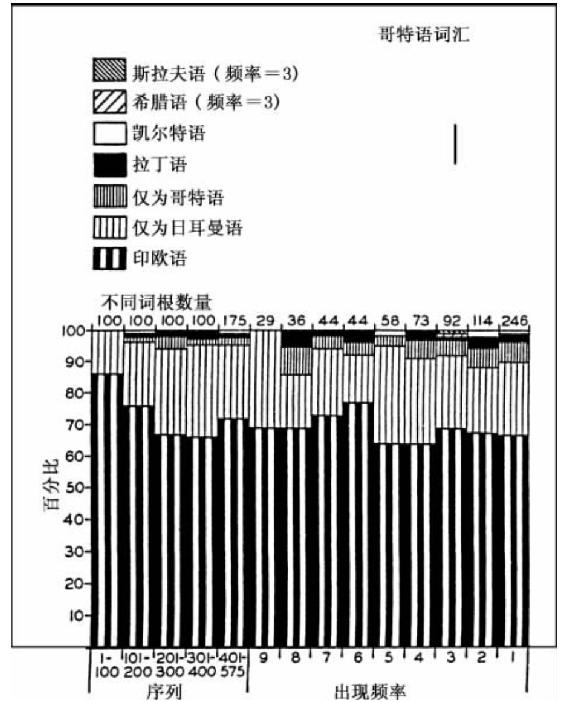
图3-11 哥特语词根的文化层。
这些各种词根的百分比是根据费斯特(Feist)词源学词典确定的40,呈现于图3-11的图1中,图中14个垂直立柱是指序列—频率列表的不同部分,这些部分在图形的顶部和底部都作了标注。因此,例如,左边的第一个立柱代表的是100个最高频率的词语中有86%的印欧语词根和14%的日耳曼语词根;第二个立柱表示的是76%的印欧语词根、20%的日耳曼语词根、2%的哥特语词根、1%的拉丁语词根以及1%的凯尔特语词根;其余立柱以此类推。
现在问题出现了,即根据这些数据我们在多大程度上敢于推理哥特语的史前文化层(如果我们可以认为相同的原则一般既适用于词根也适用于完全屈折变化的词语)。前四个立柱,是指400个最高频率的词根,确实看起来表明了这样的趋势,即日耳曼语层逐渐增加而古老印欧语层逐渐减少的这种情形似乎要么是征服者文化要么是被征服者文化开始宣称自己的权威。然而,前七个立柱与后七个立柱两者在这个方面的差异并不明显。类似的问题也出现在纯粹哥特语词根上以及在拉丁语、凯尔特语、希腊语和斯拉夫语的词根上,而且这样的问题在我们沿着该频率的列表从左向右前行时逐渐增多。这些比例是否表明各个文化影响力的强弱?这是一个问题,而且对于史前文化影响力专业的学生而言或许是一个非常有趣的问题。虽然没有更多哥尔特语文本语料可供分析,但是大量的古英语和古斯堪的纳维亚语同样可以用来分析41。
现在我们结束哥尔特语研究,转向讨论其他语言,看看专门化的外来语比例实际上是否会随着频率的减少而增加[33]。因为如果我们发现事实果真如此,我们将会获悉词汇的相对保守主义。我们在这个面将要检测两种语言,首先是古高地德语学者诺特克·拉比奥(Notker Labio)(1022年辞世)的词汇,其次是当今德裔宾州人试用的一种高地德语(宾州德语)。
圣加仑神学院院长诺特克·拉比奥,为了给他的学生们授课,将某些拉丁文古典著作“翻译”成古高地德语和拉丁语的混合文本,这两种语言彼此交织在一起——有时用德语翻译拉丁文,有时用德语评价或解释拉丁文。因此,第137首赞美诗在洛特克的译文中开篇如下(我们将他翻译的拉丁语文本标记为斜体字——我们接下来的数据分析中将该拉丁语文本排除在外);古高地德语我们译成英语而没有改变洛特克使用的拉丁语借词:
“Confitebor tibi domini in toto corde meo: I confess thee,Lord,that is ecclesia,in all my heart. I praise thee manu forti. Quonian audisti verba oris mei: whenever you heard the words of my mouth. You heard me in the prayer prophetarum and justorum” etc.(我赞美您,主啊,那就是教堂,我心中的教堂。我赞美您大能之手。每当您听见我的赞美。您会听到我在祈祷先知与正义)等等。
在上述例子中,我们发现除了拉丁语文本(即,Confitebor tibi domini in toto corde meo 和quonian audisti verba oris mei)之外这个“译文”实际上富含拉丁语词语如ecclesia,manu forti,prophetarum,justorum。事实上,如果我忽略“译文”中斜体字部分的拉丁语文本而将我们的注意力限定在古高地德语和拉丁语这个混合体赞歌[著名的《混搭赞美诗》(Mischprosa)],我们仿佛看见神学院的学生们真正说话的样子:也就是说,古高地德语混杂着大量拉丁语词语和陈词滥调,这些都是学生们要学会的。诺特克所翻译的古典文献就是这种口语体的神学院《混搭赞美诗》。由于他的译文当时闻名遐迩,我们可以推测他的中世纪日耳曼语—拉丁语的行话在邻近的神学院也是知名而用的。这种行话大概在20世纪20年代的美国也对应存在,当时许多女毕业生纯粹为了社会效益热衷于在她们的英语中混用大量法语的词语和陈词滥调。然而,对于中世纪的修女和修道士而言,《混搭赞美诗》出现的原因或许是他们还未学会或者还未记得足够多的拉丁语,不能“直接阅读古典文献”。
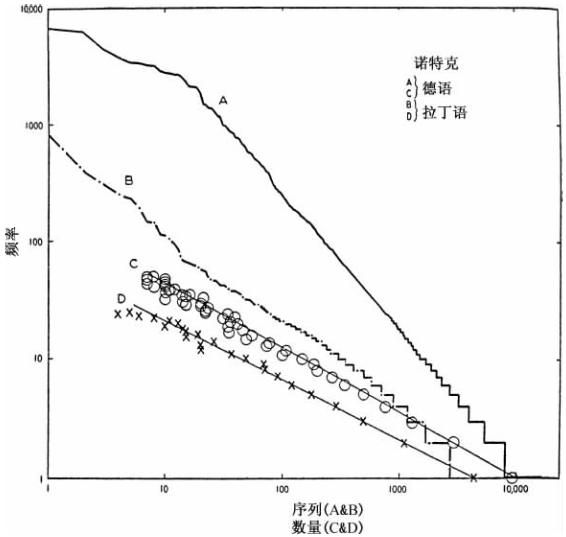
对于我们当前研究目的而言,幸运的是,有两位研究诺特克的美国学者塞尔特(E.H.Sehrt)博士和泰勒·斯塔克(Taylor Stark)博士将全部洛特克作品中所有古高地德语词语中所出现的不同词语制作了卡片索引,即在总量为195 821个连续词语中总共有17 196个不同词语。承蒙他俩将这些卡片交由我处理作序列—频率分析,其结果呈现为图3-12的曲线A。该曲线的直线性令人吃惊。同时曲线C也毫不逊色,它代表了那些出现50次或以下的相同频率的古高地德语的数量N(这些点呈现在空心圆内)。这些50个点的方程式用最小二乘法计算即为N×F1.68=9 832,该数值相对理论预期的F2的数值并非为一个糟糕的近似值[34]。如果扩大到将频率低于100的所有词语计算在内,该等式则为:N×F1.98=14 550,这个数值是一个非常相近的近似值。不幸的是,由于对数进位制难以在图形上标明从50到100的那些点。
既然我们已经发现,诺特克的《混搭赞美诗》中古高地德语名副其实有条理地遵从我们的经验方程式,那么我们就转而讨论该混搭赞美诗中拉丁文词语的频率分布(而且我们记得,我们在分析时将拉丁文部分排除在外,这些拉丁文是诺特克摘自其所译的各种古典著作)。在这个方面,我选用保罗·派珀(Paul Piper)编著的“诺特克索引及其教科书”(弗莱堡,1883年),对于《混搭赞美诗》卷Ⅰ和卷Ⅱ的前346页中所有拉丁文词语作了频率分析——在总量为21 766个词语中总共有7 080个完全屈折形式的不同词语。这些拉丁文词语的序列—频率分布呈现于图3-12中曲线B的断线中;所有出现25次或以下的词语,它们的数量—频率分布,目测是一条直线,呈现于曲线D中(以叉号表示)。这两条曲线基本上都是直线,虽然它们的斜率比曲线A和C的要小。尽管拉丁语的样本在数量上足以合理解释对整部《混搭赞美诗》本质所作的一般性说明。遗憾的是并非所有拉丁语都算在内,这样就不可能呈现一条联合曲线了。但是,作者的耐心和责任感最终消失在卷Ⅱ的第346页上(他对于该主题的智力上好奇心早在卷Ⅰ就已经得到彻底的满足)。由于诺特克数据的不完整,曲线D的斜率没有计算;可是它的直线性准确无误而且也不会在全面分析中发生丝毫改变。
我们在看待图3-12中的线性曲线图时可以一言以蔽之,该《混搭赞美诗》与我们的特化经济原则并非矛盾。拉丁语的混合呈线性分布这个事实表明,几何比率并不缺乏。表示拉丁语的曲线B比表示日耳曼语的曲线A斜率更小,这个事实似乎用简单的话来说就是,组合的《混搭赞美诗》中不同频率类型的不同拉丁文词语的比例随着频率降低而增加,这与我们的理论预期完全一致[35]。
图3-12 诺特克的古高地德语混搭文。(A)日耳曼语的序列—频率分布;(B)拉丁语的序列—频率分布;(C)日耳曼语的数量—频率分布;(D)拉丁语的数量—频率分布。
外来语具有同样直线性已经见于宾州古高地德语(宾州德语)所借用的英语词语方面,这从选自托马斯·哈特(Thomas Harter)著作《布勒斯蒂尔》(Boonastiel)(巴尔米拉,宾州,1928年)中总数为20 000个词语的四组连续5 000个词语的样本研究中得以揭示,该著作在两位著名的权威人士菲利普·A.雪莱(Philip A.Shelley)博士和阿尔伯特·F.巴芬顿(Albert F.Buffington)博士看来是以该方言写作的最著名的畅销书之一,同时也是该方言最具有代表性的例子。这本书是诙谐的书信集,是写给哈特本人的,称自己为“亲爱的哈特上校”且署名为“戈特利布·布勒斯蒂尔”(Gottlieb Boonastiel)。
这本书的实际数据分析是由我指导的巴芬顿(Buffington)博士完成的,他对于宾州德语语音的穷尽性公式化表述如今已成典范。他分析的结果用图形表达即为图3-13中四组数据。曲线A代表总共20 000个连续词语中所出现的2 762个不同词语(宾州德语加上英语外来语)的序列—频率分布;曲线B代表在20 000个词语中总共出现1 272次的589个来自英语的不同外来语的序列—频率分布。曲线C代表出现了1到10次相同频率的不同日耳曼语的数量N(该线条仅将最高点与最低点连接起来,意在使读者看得更清楚;一条拟合曲线的斜率可能稍微大些)。曲线D代表出现1到10次相同频率的不同英语外来语的数量N(该线条画出来的是为了帮助读者精确地拟合函数N×F2;一条拟合曲线的斜率可能稍微小些)。
很明显,图3-13中所有四条曲线都是非常接近直线性,曲线A并非远离调和序列,首先除了自上往下凹面只影响该口语体著作中大约12个最高频率的词语,其次除了该曲线在大约第200个序列中的斜率稍微有些变化。表示来自英语外来语的曲线B斜率较小,这意味着相同频率的外来语的比例根据一个固定比例随着频率减少而增加;的确,外来语使用频率较低,这一点在下面这个事实中也是显而易见的,即,这些外来语在不同词语中占20%以上,可是在总的出现次数中只占6%多一点。曲线C和D证实了这样一个事实,即,随着频率降低日耳曼语比例(C)减少了而借自英语不久的外来语比例(D)却在增多。因此,图3-13中宾州德语的日耳曼语和英语文化层就宾州德语词语的相对数量和年龄而言证明了我们理论上特化经济原则的真实性。此外,词语的长度与吸收的新近之间存在的关联在此也不乏见,尽管限于篇幅我们没有呈现一个详尽的图表[36]。同时遗憾的是,我们不能呈现全部列表中来自英语的500多个不同外来语,这些英语外来语或许比任何其他事物都更能代表纯粹美国文化层的词语。这样一个由美国文化进入一个外国文化的外来语列表与门肯(H.L.Mencken)对于由外国文化进入美国文化的外来语的研究同样具有启发意义。
图3-13 宾州德语(宾尼法尼州古高地德语)。(A)宾州德语词语以及英语外来语的序列—频率分布;(B)英语外来语的序列—频率分布;(C)来自日耳曼语的词语的数量—频率分布;(D)来自英语的外来语的数量—频率分布。
不幸的是,对于外来语我们没有进一步决定性的定量数据。对于当今依地语的广泛调研,是我先前同事著名青年学者斯塔姆(I.S.Stamm)博士负责完成的,该调研由于缺乏研究用的外来语而令人失望。这或许是由于为了分析而选择的文献导致的。但是根据我们的研究结果,那种认为依地语是日耳曼语、希伯来语、斯拉夫语等语言的显著混合体的普遍观点似乎还是谬见。依地语除了语音有偏离之外也只不过是日耳曼语的一种方言(至于它的序列—频率分布,参见下文);的确,对于日耳曼语中外来语的研究大概会有更多收获。
鉴于我们上述数据,就其本身而言,我们似乎合理地认为,在某特定语言中,词语的大小和频率与其年龄成相反关系,结果便是,词语越长频率越低因而也就越年轻。此外,由于频率越低的词语越少有不同意义,所以我们能够理解为什么外来语在我们看来是“高度专门化的”词语(即具有高度特化的意义)。
既然我们已经呈现了我们的数据并且论述了词语特化经济原则,我们就不要忘了在探究该原则更加普遍的含义时采取更加宽泛的视野。广泛地来讲,该原则似乎表明,创新的“力量”往往在外围对于频率较低的行动的形式和功能更能成功地施加影响,而对于频率较高的行动的形式和功能则不然,后者是更加保守的核心或矩阵[37]。
四、效益递减法则的概述:“普遍调和级数”
迄今为止,我们已经从许多不同角度分析了言语流。我们一开始论证了词语的相对长度为何与其相关的出现频率成相反关系(简略经济原则)。接着我们论证了词语不同意义的数量为何随着它们的频率而增加(多能经济原则)。接下来的主题是置换经济原则,我们从语言实例一直到更大的构型等各种言语实体论述了这一原则。最后我们论及特化经济原则,我们通过发现词语的年龄与其频率正相关来检测此原则。这四个原则背后的推手是来自工具“就近放置”以及工具数量n减少的经济。由于这个推手,年龄老、规模小、意义多样以及置换结合的多重性等所有这些方面往往都与高频率使用成正比例。这种关系中的这些术语值得记住,因为这种关系或许有望出现在任何遵循我们工具类比的生物社会组织中(参见第六章)。
然而,到目前为止,我们阐述的方式存在一个风险。因为虽然我们已经一个接一个地论证了上述原则,但是我们必须记住它们都是不断地同时运作,从而以最大经济保留动态平衡。也就是说,在动态过程中词语在意义上是不断地得以减少、置换、消除、借用和改变,可是与此同时语音体系的四项原则对于基本语音实体的数量、形式、频率以及空间一直在起作用。由于这些因素,我们可以预期任何地点任何时间任何语言的任何样本言语流中都会有显著的迹象表明各种分布,我们一直在形式—语义平衡这个总标题下描述了这些分布。
或许没有什么比快速连续看待从同一语言各个不同发展时期挑选的这些言语样本词语的一系列序列—频率分布能够更好地阐述这个动态过程中不断朝着形式—语义平衡的驱动,我们稍后将以此来处理英语和日耳曼语的数据(图3-14和3-15)。
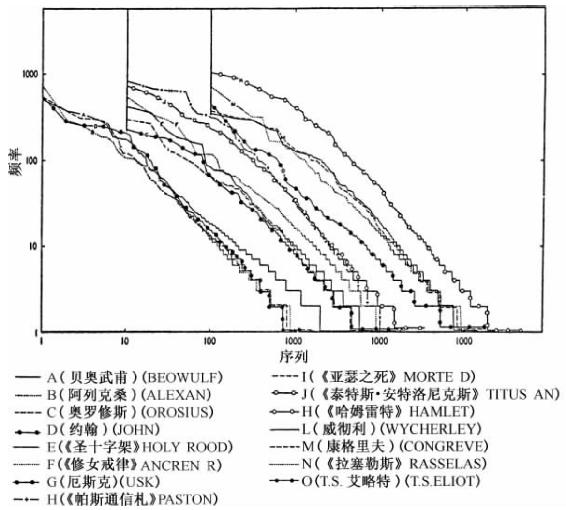
图3-14 贝奥武甫至T.S.艾略特。从早期古英语至今15位英语作家的词语的序列—频率分布。
但是在我们转而讨论这些数据之前,这些数据代表了从大约5 000到大约20 000个连续词语的不同篇幅的差不多24个独立语言样本,我们必须简要地指出某些必定出现在不同篇幅样本中的变化问题。首先,在与这些部分样本一样小的样本中我们可以预料到它们在某种程度上会偏离我们预期的线性标准,该偏离是以某种波浪形式出现在我们的直线上,这种波浪式线条往往随着样本篇幅的增大而消失。其次,我们可以预料到线条的斜率往往随着样本篇幅的增大而稍微减小,其中原因早在第二章就已经提到了;当然,在样本篇幅差不多同样大小的范围内,斜率也会差不多同样大小。第三,我们必须准备好去发现一些不稳定平衡的情况,在该情况中即便适当考虑到样本篇幅,斜率还是要么平缓要么陡峭;于是在此我们必须寻找语言历史发展中的随后纠正,因为一个更加稳定的平衡出现了。由于这第三点对我们整个研究很重要,我们有好几个暂时不稳定平衡的典型案例真的很幸运。
但是,这三点在我们数据上都不如曲线顶端凹面向下的明显弯曲即自上向下凹曲引人注目,我们已经提到过自上向下凹曲,而且它一般仅仅代表12个左右的最高频率词语。这个特殊弯曲的出现只不过意味着我们所研究的样本是选自亲密私人书信中(以及戏剧、劝诫布道语料等等)存在的某种“口语体言语”;而在更加正式的语料中没有这种弯曲[38]。
至于在亲密个人(即非正式的)书信中出现顶部凹曲的原因,这可能反映了在此情形中作者与读者有某种共同的体验,因而无需用高度清晰的陈述来表达,然而在给对该主题不熟悉的非亲密的人写信时则必须使用这种高度清晰的陈述。因此,在给一位关系非亲密的人写信讲述一个非熟悉的话题时冠词和其他短小的高频词语是必需的,对于一个关系亲密的人则不需要,因为后者无需明示也知道马莉、约翰和内德分别是指哪只猫、哪位司机和哪只狗,而且也能猜到“he”、“she”和“it”各自所指称的人或物。总之,在顶部凹曲的言语样本中,我们毫无例外地发现,常见的高频冠词等词语的频率部分让位给更多的人称代词,结果在顶部形成了凹曲。
记住上述几个因素,我们现在转至图3-14,其中我们发现有15组不同数据,时间跨度从早期的《贝奥武甫》(Beowulf)古英语(曲线A)到最近的艾略特(T.S.Eliot)的诗歌(曲线O)。为了方便读者,这些曲线分布在连续三组的对数坐标图上,正如检查每条曲线顶部见到的那样,而且每条曲线都是从序列1开始的。
第一组四个序列—频率曲线首先是:曲线A、B、C和D。曲线A代表了《贝奥武甫》的完全屈折变化形式的词语,这是由我先前的学生埃伦·B.索伦森(Allen B.Sorensen)先生从天主教神父柯莱伯(Fr.Klaeber)博士的词汇表中建立起来的。该条曲线总体上相当平直;然而其斜率低于1,因而表明存在一个不稳定的平衡状态,尽管该斜率也可能是由该语料的诗学本性导致的。无论如何,很有必要指出,在曲线B、C和D中,这三条曲线代表后期古英语,调和斜率已得到修复,以及继《贝奥武甫》时期之后古英语已经历经了某些少量的形态简化。曲线B、C和D分别代表10 000个连续词语的样本,曲线B的样本来自(B)无名氏的古英语《亚历山大大帝致亚里士多德信札》(Letter of Alexander the Great to Aristotle)(10世纪晚期),曲线C的样本来自(C)阿尔弗雷德(Alfred)翻译的《奥罗修斯》(Orosius)(9世纪),以及曲线D的样本来自(D)最近《西撒克逊语约翰福音书》(West Saxon Gospel of John),这三条曲线的数据都是由小马古恩(F.P.Magoun Jr.)博士统计确定的,承蒙他将此数据交由我处理用于我这里的研究。我们发现,尽管曲线B、C和D存在时间差异,它们仍十分相似。
我们现在转向第二组对数图,有六条不同曲线(从E到J)。曲线E代表《圣十字架》(The Holy Rood)(约1170年)中大约7 000个连续词语,这是由我先前的学生史密斯(R.F.W.Smith)先生分析的,这是很早的中古英语,代表了该语言结构变化较多的一段时期。曲线F代表《修女戒律》(约1230—1250年)中10 000个词语的英语文本样本,这是由我先前的学生多福林格(W.M.Doerflinger)先生确定的;而且我们记得,对于12世纪和13世纪的读者而言,《贝奥武甫》或者阿尔弗雷德作品或埃尔弗里克作品很可能完全是外语——那些发生其间的形态变化、语音变化以及语义变化更是如此。曲线G、H和I来自我先前的学生艾尔默·R.贝斯特(Elmer R.Best)先生的细致研究,它们是指15世纪的英语:曲线G代表厄斯克(Usk)的《爱的见证》(Testament of Love)中10 000个词语,曲线H代表约翰·帕斯通(John Paston)爵士信札中的20 000个词语,以及曲线I代表马洛里(Mallory)的《亚瑟之死》(Morte d'Arthur)中的10 000个词语。曲线G到曲线I差别不是很大,尽管它们在风格以及样本规模上存在着差异;此外《帕斯通信札》(Paston Letters)(曲线H)的顶部凹曲也在意料之中,因为私人通信本就亲密。与之相似的是,曲线J数据也是亲密的口语体,它是对莎士比亚《泰特斯·安特洛尼克斯》(Titus Andronicus)所作的分析,这是由我先前的学生布莱克莫尔·埃文斯(G.Blakemore Evans)着手分析的;该条曲线总体上线性十足,而且看得出它比一百多年前的《帕斯通信札》更加接近调和级数。到了莎士比亚时期,古英语和中古英语的屈折变化已大为简化,同时有大量来自拉丁语和罗曼语的外来语已经融入了英语。
我们转向第三组图,该图另有五组数据。曲线K代表莎士比亚的《哈姆雷特》(Hamlet),这是由我先前的学生邦德(W.H.Bond)先生分析的;该曲线除了前12个左右的词语之外十分平直,我们将在联系图3-15时再回到该数据。曲线L和M是指17世纪晚期两位喜剧作家作品中10 000个词语,它们分别来自威廉·威彻利(William Wycherley)的《乡村女人》(Country Wife)以及威廉·康格里夫(William Congreve)的《如此世道》(The Way of the World),这是由我先前的学生威廉斯(D.G.Williams)先生在我同事也是该领域知名专家肯尼思·B.默多克(Kenneth B.Murdock)博士的指导下进行分析的。L和M这两条曲线十分相似,它们与曲线N差别也不是很大,曲线N代表18世纪中期的塞缪尔·约翰逊(Samuel Johnson)博士的小说《拉塞勒斯》(Rasselas),这是由我先前的学生安森(A.J.Ansen)先生统计确定的。最后,曲线O呈现的结果是由我先前的学生多丽丝·A.荷格兰(Doris A.Hoagland)小姐取得的,她分析了T.S.艾略特的《诗选:1909—1925》[Poems(1909—1925)]中前5 000个词语,两首法语诗歌除外,即她没有分析《经理》(Le Directeur)和《乱性杂拌》(Mélange Adultere de Tout)。将该样本包括在此是为了表明,即便艾略特先生明显偏离英语的风格“标准”,他的语言在我们的曲线图上也并未显得格外怪异。
当然,限于篇幅其他一些研究并未包括在此。我的学生玛丽·G.道格拉斯(Mary G.Douglas)计算了两个2 500个词语的样本,一个来自格特鲁德·斯泰因(Gertrude Stein)的《艾丽斯·B.托克拉斯自传》(Autobiography of Alice B.Toklas),而另一个样本来自弗吉尼娅·沃尔夫(Virginia Woolf)的《到灯塔去》(To the Light House)。这两条曲线与其他曲线很相似。沃洛诺克(E.Woronock)小姐计算了查尔斯·卓别林(Charles Chaplin)先生电影的影评中7 500个词语,并且发现了一条十分近似于直线的曲线。类似的直线性也见于艾伦·F.小阿诺德(Alan F.Arnold Jr.)对于阿切博尔德·麦克利什(Archibald MacLeish)的文章《不靠谱的人》(The Irresponsible)所作的分析中。
现在我们从整体上审查图3-14中15个曲线图,同时记住它们代表英语生命长河中流逝的1 000多年历史,而且涉及从金·阿尔弗雷德(King Alfred)到T.S.艾略特先生如此广泛不同的个性。在诸多情形中皆存在顶部凹曲,该顶部凹曲至多对于前几十个词语而言较为明显且一般代表了所有不同词语数量的1%之中的1/10不到。但是随着我们审查图3-14(译注:原文中为“Fig.3-4”,可是根据上下文,此处当为“Fig.3-14”)中曲线,我们当然想知道,这些曲线随着它们从左向右“下溢”不是基本上相似——而是比它们所代表的实际作品还要相似。(当然,随便读者在自己书架上另找某个作家,分析该作家五千个或一万个词语的样本,都可以检验我们的原则。)
我们在认识上述15组英语数据之后转而论述图3-15左下角标识为1的8组德语和依地语的序列—频率分布。其中有六个分析是在与图3-9阐明的词素分布时一起讨论过的。更具体地说,曲线A代表了高地德语《伊西多尔》(Isïdore)中4 825个词语的序列——频率分布,这是由默雷·弗勒(A.Murray Fowler)博士确定的。曲线B代表古高地德语《韦塞布鲁勒布道》(Wessobrunner Sermon)以及《奥特劳祷文》(Otloh's Prayer)中1 726个词语,这是由斯蒂芬斯(S.A.R.Stephens)先生研究的。曲线C代表古高地德语《班伯吉宗教信条与忏悔祷文》(Bamberger Creed and Confession)中2 556个连续词语,这是根据肯尼思·拉杰斯泰特(Kennth Lagerstedt)先生的分析而确定的,他还分析了《来自波西米亚的农夫》(约1 400年)中10 000个连续词语,这在图中由曲线E来表示。曲线D代表了选自伯特霍德·冯·雷根斯堡(Berthold von Regensburg)的《布道文》(Sermons)(约1 250年)中10 000个连续词语,这是由卡罗琳·P.赖利(Caroline P.Riley)小姐研究的(限于篇幅,我们没有在此呈现出沃青格(Watzinger)博士对于这些布道文中另外5 000个词语的研究,因为它们的曲线与赖利小姐分析的一样)。曲线F代表了从拿骚·萨尔布吕肯(Nassau-Saarbrücken)的《胡格沙普勒》(Hug Schapeler)(1437年)中女伯爵的大约10 000个连续词语的样本,这是由我先前的学生沃伦·梅雷迪思(Warren Meredith)先生作出的研究。曲线G代表了盖勒·冯·凯塞伯格(Geiler von Kayserberg)(1445—1510)作品中“朝圣者”的大约5 000个词语,这是由斯蒂芬斯(S.A.R.Stephens)先生所作的研究。在曲线H中我们呈现了对于依地语(Yiddish)的20 000个词语的数据研究,这是由施塔姆(I.S.Stamm)博士负责的;这些依地语摘录自阿布·卡亨(Ab.Kahan)的《我生命中的树叶》(Bltter von mein Leben)(卷Ⅱ,纽约,1926年)、列文(Z.Levin)的《科波东维兹及其他故事》(Kopolovitz und andere Erzhlungen)(纽约,1926年)、泽文(J.J.Zevin)的《顾客与小贩洽耶姆》(Chayim der Customer-Pedlar)(纽约,1926年)、施耐尔(Z.Schnaiur)的《表兄扎合姆》(Vetter Zhome)(维尔纳,1930年)以及刊发在报纸上的一些文章。曲线H增补在此是为了说教的原因,为了提醒读者将上述非同类的语料结合在一起并视作同类可能有望产生什么结果。
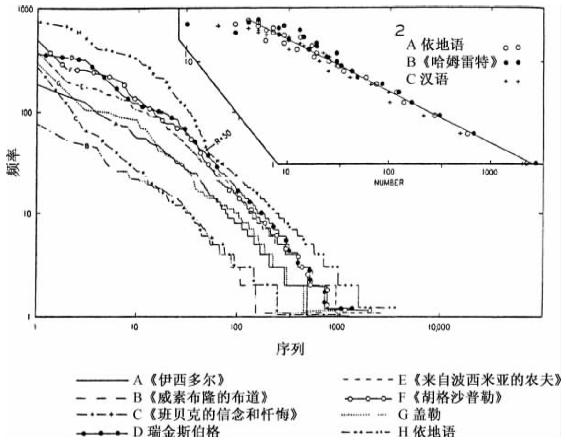
图3-15 比较曲线。(1)七位古高地德语或中古高地德语作者的词语以及依地语词语的序列—频率分布;(2)依地语、《哈姆雷特》和汉语的数量—频率关系。
显然,除了曲线H的依地语,图3-15中德语曲线或许恰好可以作为第四组曲线图放置在研究英语的图3-14中,因为从9世纪到16世纪的德语曲线图与从9世纪到20世纪的英语曲线图没有根本的统计差异。总之,尽管原始的西日耳曼语很久以前一方面在英格兰分裂成各种方言,另一方面在南部德国也分裂成各种方言,而且尽管千百年过去了,这些方言在语音、形态、语义以及句法上变化很大直至各自完全演变为不同的外语,然而就这些语言各自序列—频率分布所反映的动力学而言,它们依然基本相同。而且,如果我们再退一步将哥特语代表的东日耳曼语包括在内,我们仍将发现它们是相同的;并且据我们所知,图2-3中的希腊语也同样如此。
因此,我们在言语行为中发现了物理学家早就已经发现的非动物界行为的规律:在所有明显多样复杂的现象背后存在着相同的基本动力原则。
我们可不要忘记,图3-15中表示依地语的曲线H在其顶部有着显著的凹面膨胀,这代表了前50个词语(占不同词语总量的1.31%)频率过高。正如前文提及的以及另外刊发的文章中所处理的那样42,此类膨胀或许是汇聚非同类语料造成的。然而,如果我们察看曲线H中R=50以下部分会发现一个显著的直线性,该直线性并非与混合数据样本不相容,假如各个样本本身的下部分是呈调和级数的话。如果曲线H的下部分确实是条直线,那么,为了发现熟悉的线性数量—频率关系是否存在,将相同f的不同词语数量N标示在横坐标轴上而将f标示在纵坐标轴上,也会揭示出曲线H下部分为直线这个事实。我们已经在图3-15右上角(标注为2)作此处理:其中,我们用空心圆圈表示所有f值为1到25的相同频率f的不同依地语的数量N;我们还用实心圆点表示《哈姆雷特》中大约30 000个连续词语的f值为1到25的相同频率不同词语的数量,这是由威廉·亨利·邦德(William Henry Bond)先生确定的。我们添加了一条指数为2的任意画出的直线,是为了让读者看起来方便。但是还没完,因为我们还添加了用十字符号表示在以前发表的文章中讨论过的43总量为13 428个连续词语的北京话样本中f值为1到23(因为没有一个词出现了24次或25次)的相同频率f的不同词语数量N。这三组数据在斜率上与图2-3中荷马的《伊利亚特》以及乔伊斯的《尤利西斯》的斜率差别不大,或者与图3-7中哥特语圣经的斜率差别也不大。如果图3-15(2)中的空心圆圈、实心圆点以及十字符号有时太近了不容易区分,读者应该怪罪最省力原则,因为该原则运行期间的基本言语样本在规模上如此相似以至于结果同样十分相似。尽管依地语、莎士比亚语言以及汉语在时间、空间和文化上存在巨大差异,但是它们之间的动力差异并非显著。
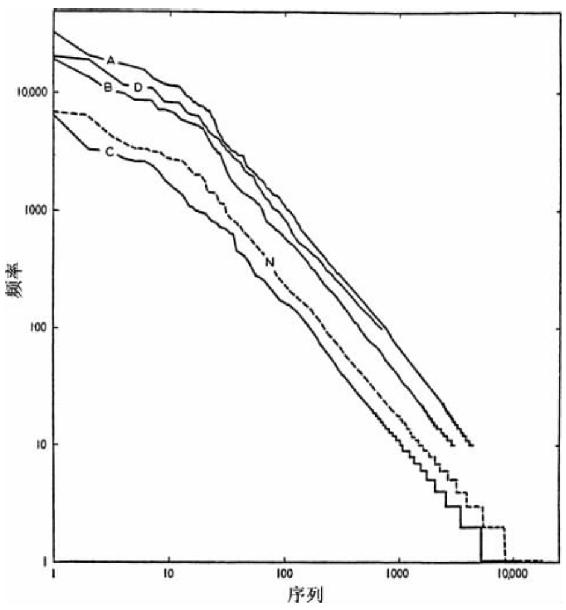
还有其他语言的频率列表。截至1939年主要欧洲语言的参考书目选集可见于弗里斯(C.C.Fries)和特拉维(A.A.Traver)的《英语词语目录》(English Word Lists)。自1937之后在汉利博士对于詹姆斯·乔伊斯的《尤利西斯》作出的《词语索引》(Word Index)影响下,一系列重要索引已经出现在威斯康星大学及其大学出版社。它们是:班迪(W.T.Bandy)的《波特莱尔诗歌词语索引》(A Word Index to Beaudelaire's Poem)(1939年)[39],黑夫纳(R.M.S.Heffner)和雷曼(W.P.Lehmann)的《瓦尔特·冯·德尔·福格威德诗歌词语索引》(A Word Index to the Poems of Walther von der Vogelweide)(1940年),霍菲尔德(A.R.Hohlfeld)、马丁·朱斯(Martin Joos)和特维德尔(W.F.Twaddell)的《歌德〈浮士德〉作品中的词语索引》(Wortindex von Goethes Faust)(1940年),阿尔弗雷德·森(Alfred Senn)和雷曼(W.Lehmann)《沃尔夫拉姆的〈帕尔齐法尔〉词语索引》(Word-Index to Wolfram's Parzival)(1938年)。此外,还有最近的(1942年)里程碑式的《挪威语词语研究》(Norwegian Word Studies),这是由埃纳·豪根(Einar Haugen)所作的两卷本研究成果,它编入的索引有①西格丽德·温赛特(Sigrid Undset)描写中世纪生活的小说以及②她早期描写现代生活的作品、③伊娃·艾森(Ivar Aasen)用新挪威语写的作品、④亨利克·沃杰兰德(Henrik Wergeland)(1808—1845)的词汇以及⑤古挪威语萨迦传说的词汇。我们顺便说一下,《挪威语词语研究》这个宝贵的研究已经用油印形式出版了,而且只出版了100本(聪明人会举一反三)。它包括了(20页之后)以前斯堪的纳维亚词语统计的目录索引。虽然我们可能没有更多空词叙述德语频率目录,特别是如今这些目录已经公开出版不难获得,但是我们仍然的确在图3-16中呈现了豪根博士的现代挪威语语料,其中有5条曲线:曲线A代表温赛特的中世纪生活小说,曲线B代表她早期的现代生活作品,曲线C代表伊娃·艾森的新挪威语作品,曲线D代表沃杰兰德的作品。在最初发表时,曲线A和B中频率低于10的值并未给出,曲线D中频率低于100的值也未给出。顺便说一句,至于曲线N代表南部德国修道士诺特克·拉比奥( —1022)的古高地德语,该语料我们已经在图3-12中用曲线A加以呈现。这些曲线除了顶部凹曲之外基本上是平行的,斜率略低于1(大概是因为样本规模巨大的缘故)。
在察看图3-16时我们应该记住,曲线N代表的诺特克语言与其余四条曲线代表的语言至少相隔800年。并且,曲线N代表西日耳曼语,而其余四条曲线代表北日耳曼语。
图3-16 挪威语(豪根的分析)和诺特克词语的序列—频率分布。(A)温赛特的中世纪生活小说;(B)温赛特早期现代生活作品;(C)艾森的新挪威语;(D)沃杰兰德的作品;(N)诺特克的作品,来自图3-12。
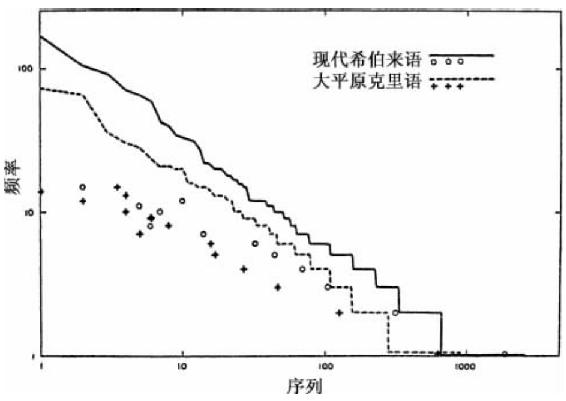
由于上述图形的斜率近似于一个调和级数(除顶部凹曲之外),我们不要忽略,有时候那些所谓的“词语”的序列—频率斜率很可能是小于1的。努特卡语和大平原克里语的“表句词的词语”情况也是如此,正如我们在图3-1和图3-2中所见到的。为了更新我们对于此类低于1的斜率的记忆,我们在图3-17中呈现了当今巴勒斯坦希伯来语的5 000个连续词语的序列—频率分布,这是由我先前的学生伯纳德·西格尔(Bernard Siegel)先生分析的,他还一起分析了美洲印第安语言大平原克里语中2 000个连续词语的样本,我们添加在此以便比较。希伯来语的曲线是四个5 000词语的样本中第一个,令人遗憾的是,西格尔先生从未有机会按照原计划将这四个样本结合在一个有20 000个词语的样本中。大平原克里语的曲线是五个2 000词语的样本中第一个,这五个样本在图3-2中是以一个联合的形式呈现出来的。
图3-17 希伯来语和大平原克里语。序列—频率分布(折线和线条);以及数量—频率分布(空心圆圈和十字符号)。
显然,图3-17中两条曲线是直线性的,几乎平行且斜率明显小于1。此外,那些出现15次或以下次数的词语的数量—频率关系中各自空心圆圈和十字符号基本上呈直线性且相互平行(大平原克里语中没有词语出现11次,希伯来语中没有词语出现13次或14次)。而且,根据我们的统计数据,理论上巴勒斯坦希伯来语与大平原克里语和努特卡语一样在结构上具有表句词语言的本质——事实也正如此。因为图3-17中希伯来“词语”包括希伯来语中在技术上通常称作“不可分离之词”。顺便说一句,移动“不可分离之词”以及研究因而产生的序列—频率分布这项任务(比如,我们在图3-1中为努特卡语的A1和A2分布所做的工作)也是由西格尔先生承担的,但是没有全部完成;可是在希伯来语“不可分离之词”移动后现有的解析数据范围之内,它们的序列—频率分布并非与斜率为1的直线性格格不入,尽管存在一个非常显著的尾端。在这个方面,我们记得巴勒斯坦希伯来语,与努特卡语不同,在很大程度上是一种“人为建构的”语言;而且这一事实可能用来解释那些解析数据的变体[40]。
到目前为止,我们已经呈现了足够多的数据以表明词语以及表句词的序列—频率分布往往在双对数坐标图上是直线性的,即便该分布的负斜率可能并非总是1(正如我们刚才在图3-17数据中发现的那样)。或许通过总结我们可以暂时抛开这些斜率变体的主题——首先探讨斜率的数学运算然后再探讨理论。无论在哪种情况下,问题简单易答。
至于斜率变体的数学运算,我们在图3-18中呈现了五条不同直线,它们绝对斜率的大小都是由字母p之后的分数表示。因此,底部的水平直线没有斜率,即标作p=0;由于从下向上的第二条直线在水平线上的截距是其在垂直轴上截距的 ,所以它的p值是。其余直线的斜率以此类推。显然,我们能够无限增加这些直线的斜率,然而不管斜率有多陡峭,垂直轴上截距的总量除以水平轴上截距总量时将会得出p的数值,该数值即为绝对斜率。
,所以它的p值是。其余直线的斜率以此类推。显然,我们能够无限增加这些直线的斜率,然而不管斜率有多陡峭,垂直轴上截距的总量除以水平轴上截距总量时将会得出p的数值,该数值即为绝对斜率。
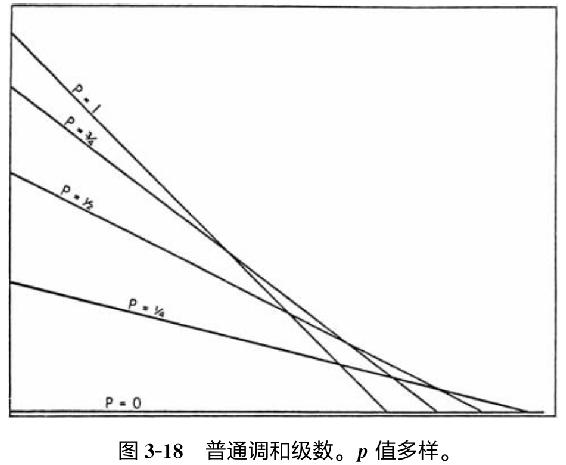
图3-18 普通调和级数。p值多样。
无论p值是多少,在双对数坐标图上某特定斜率p的直线上的点都可用下列简单方程式进行代数描述,
r×f1/p=C
其中,r代表序列,标绘在横坐标上,而f代表频率,标绘在纵坐标上。当p=1时,碰巧正如图2-1中数据的情况,那么,我们得出r×f=C这个熟悉的方程式,该方程式我们在第二章讨论过了。
此外,当我们将一组序列—频率数据视作分数级数时p值很重要,正如我们在第二章讨论调和级数方程式时一样,我们现在将其作如下描写:
右边分数的分母指数为1的原因很明显,如果我们将普通调和级数的方程式作如下描写:
这个普通调和级数(我们全书中一个基本方程式)描述任何一组序列—频率数据,它们的点在双对数坐标图上形成直线。n的大小将是X-截距的逆对数;F的大小将是Y-截距的逆对数;p的大小将是Y-截距除以X-截距的值。在简单调和级数的情况下,我们迄今一直讨论的就是简单调和级数,X-截距等于Y-截距,结果p=1(我们因而完全省略了指数)。因此,我们的简单调和级数只不过是普通调和级数的一个特例44。
记住上述简单数学运算,我们现在可以回到图3-1中努特卡语、图3-2中大平原克里语以及图3-17中希伯来语,并且计算它们的斜率和p值;有了这些数值我们差不多可以用普通调和级数或者方程式r·f1/p=C来描述这些数据。因而只要这些分布是直线性的,我们整本书的数学运算方面都是十分简单易答的,因为斜率的大小给我们揭示了一切[41]。
我们现在根据普通调和级数转向斜率变化之理论意义,我们记得我们理论上的多元化之力将斜率“拉”向零斜率,可是我们理论上的统一化之力将它“拉”向真垂线而斜率无限变大。我们调和级数的绝对斜率1似乎表明了这两股假定力量的动态平衡。这就是大量词语序列—频率的斜率,正如我们已经看到的。
为什么p=1这个数值对于词语至关重要,这个问题再自然不过了,因为显然其他斜率也有可能,而且的确对于大平原克里语和巴勒斯坦希伯来语而言是有可能的,其他斜率(低于1)已经被发现了。这个问题我们将试图在第五章作答。
第五节 小结
我们在前文已经呈现了相当多的经验数据,我们已经尝试通过机械类比(工具类比)的经济进行合理解释。
至于经验数据本身,我认为我们已经呈现足够多了,无疑可以证实人类言语存在着条理性。因此,不管具体使用的物理词语,以及不管它们的具体意义,甚至据推测如果不同群体没有两个物理词语且没有两个共同的意义,不同词语的数量n及其频率f之间的比例对于所有言语群体而言显然都是相同的。这整个条理性我们稍后将界定为心智,对于心智的动力学我们将在第五章和第七章作更多具体的探讨。
我们所有构想显然是指个人组织和使用n个不同种类的物理刺激引起m个不同种类的反应(即意义),这是根据所探讨的言语群体的传统而言的(m等同于我们机械类比的z个不同用途)。
我们在论述时始终都指出两种一致的言语倾向。第一个倾向是指向减少言语实体的重要性,实体规模越小出现的频率就越大;我们称之为简略法则。
第二个倾向是指向减少或最小化所履行的不同行动种类的数量n;我们将此倾向称作效益递减法则(稍后我们将简称为“n最小值”)。我们论及了多能经济原则、置换经济原则以及特化经济原则,这些原作是把应用种类多样性n最小化的工具,我们仅提及在此而不去回顾它们的定义[42]。
为了合理解释我们的数据,我们创设了工具类比,有n个不同工具,它们的结构我们在此不作回顾,仅强调我们上述的法则与原则皆来自这个类比。然而,在言语和工具类比之间是否存在一个比单单类比物更加紧密的关系,这种疑问非常合理。有关这一点以及展望我们在稍后章节所作的论述,我们认为,言语是指组织n个不同种类的物理行为,它在刺激与反应之间只存在一种传统的或文化的关联。另一方面,我们的工具类比是指组织n个不同种类的物理行为,它在刺激与反应之间存在一个物理关联。这种区分的重要性将在第五章、第六章和第七章论述的充分明了。在这些章节中,我们在探讨可能的功(力)这个问题的过程中将会发现,言语与这个工具类比之间没有动力学差异;而且一般来说一个重要的机体经济在于它将其所有n个不同种类的行动最小化的过程中。
我们已经在本章论述了形式—语义平衡这个一般主题,我们将在第四章转而简要审视儿童言语结构,我们从中将会证实我们前文的大部分论述。接着,我们将在第五章转而呈现有关论述且将言语视作听者的感知,而听者的普遍经济将得以探讨。我们将在第五章研究一个完全不同的问题,我们在探究思考的组织时会再次论述普通调和级数的经济。
[1]我们将在第五章清除所履行的工作中所有限制,我们将工具类比这个问题视作不断变化的工作以及不断变化的工具,工匠因而必须不仅为了工作寻找工具而且还要为了工具寻找工作,该工匠是以一种成熟的形式语义平衡的方式进行这些寻找,这种方式在语言过程中会有对应物。
[2]如果可以适当地选择单元,就不需要一个常量因子。
[3]显然,如果两件或更多工具的f与m(以及其他重要方面)完全一致,并且既然一件工具必须在这个一维木板上排在另一件(或其他)工具的前面,那么代表相同功力的工具排列将会有两个(或更多)选择2。
[4]这个特定的平衡,是指工具的形式和功能的改变以便减少使用时功力消耗的比率,这个平衡显然不是像物理学家所理解的纯粹静态平衡的一个例子,也不是生物学家所理解的体内平衡,而是按照目前定义理解的动态平衡。
[5]当然,我们承认这个数据指的是相同或相似频率类别的词语的平均长度。如果我们检查各自出现一次、两次、三次等实际词语长度,我们发现无论是按照音位还是音节计算的词语长度都有变数。然而我没有真正计算过这些要素,我已论述这些变数在各自频率类别范围内基本上是对称的,其模式是随着频率增加而向左移动,并且峰度随着频率减少而变小。我们提到这些技术问题是因为,我们稍后将看到,探索性研究表明,在某特定频率类别内,词语越长越可能是该语言中新的或初生的词语,然而越短的词语越可能是旧的或衰老的词语。
[6]想想使用一个高度多功能的小器械去执行任何一个可能的任务要费多少功力!这个功力比一个专门性工具花费的功力可能还要多。因此对于多功能的不断增加存在一个阻力。关于专门性工具的经济,参见下文。
[7]我们使用置换这个词语主要是指组合,是为了强调一起使用的固定顺序的重要性(即,大头锤锤凿子而不是凿子锤大头锤)。在实际作坊中,有些工具只能按照一个特定顺序一起使用,其他工具可能根本不可能一起使用。言语中我们就有这样的置换,如horse race以及racehorse可置换,可是doorknob不可以置换成“knob door”。我们可以有apt,pat以及tap,却没有tpa,pta或atp。因此,我们的术语置换只是被看作描述一个以差不多固定顺序而组合在一起的倾向,仅此而已。
[8]词语的年龄与长度之间的关系可见图3-10所呈现的。
[9]因此,不管动态过程的创新,正是因为这些我们已经讨论过的经济原则(而不是因为好古癖,也不是因为憎恶革新),我们应该可以预见显著的倾向是保留更频繁(并且更老的)工具与任务。总之,频率(及年龄)是价值的结果,而不是相反。
[10]我们在接下来章节中将会明白,从某种非常实际的意义上说,言者在跟听者谈话时试图把听者及其反应当作一套工具以便实现言者的目的。因此,这个工具类比引入听者并非无效。
[11]即使桑代克的第20组千词语组中的词语在其样本中出现了几千次,因而有机会代表那些与第一组千词语所见到的同样多的不同意义。
[12]我们可以说单个独立的“未置换”工具代表一次单个工具的置换,因而我们也可以说单个独立的“未置换”词语代表一次单个词语的置换。我们提到这一点是为了表明,B分析基本上是词语置换的序列—频率分布,最小置换是由单个词语构成的,也就是说,B分析包括完全同类的数据。为了更方便的阐述,我们仅仅使用表句词这个术语,意指两个或以上词语的置换。
[13]我们将在第五章再次回来思考这个努特卡语材料,我们会发现它对于理解语义结构有至关重要的价值。
[14]我们用的这个术语意思是,曲线在图形的顶端呈向下凹曲。
[15]这个一般等式将会是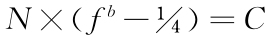 。因为如果p代表序列—频率分布的斜率的倒数,b的大小将会是P+1+一个小常量,那么两条B曲线的b一定会大于2。我们在文本中陈述了“阶梯”的“梯面”的最小二乘法斜率15。本章以及前一章没有对所有序列—频率分布计算最小二乘法,因为拟合这么多点需要大量的劳动。每第十个序列的拟合将会告诉我们的东西不比我们已经从图中所知道的东西多。读者将会在第十四章发现许多序列—频率斜率的最小二乘法的答数。
。因为如果p代表序列—频率分布的斜率的倒数,b的大小将会是P+1+一个小常量,那么两条B曲线的b一定会大于2。我们在文本中陈述了“阶梯”的“梯面”的最小二乘法斜率15。本章以及前一章没有对所有序列—频率分布计算最小二乘法,因为拟合这么多点需要大量的劳动。每第十个序列的拟合将会告诉我们的东西不比我们已经从图中所知道的东西多。读者将会在第十四章发现许多序列—频率斜率的最小二乘法的答数。
[16]努特卡语和大平原克里语各自连续五组2 000个词语的最小二乘法负效率、误差以及对数的Y-截距,相同f不同词语数量N,f值从1到10。
[17]构成达科他语样本10 000个词语的每组2 000个连续词语的连续五组词语的负最小二乘法(a)斜率、误差以及(b)对数的Y-截距分别为(1)a:0.410 97±0.051 0;b:1.141 5;(2)a:0.425 06±0.063 2;b:1.177 05;(3)a:0.354 99±0.061 2;b:1.053 86;(4)a:0.402 90±0.062 2;b:1.127 76;(5)a:0.384 61±0.057 6;b:1.103 16。
[18]外来专有名词,主要来自阿拉姆语,是伍尔菲勒斯(Wulfilus)借自希腊语圣经,这些词只有在具有哥特语词尾时才被视作词根词素,在后一种情况里是以除去词尾的形式来计算的。
[19]一般来说,如果p是线性序列—频率分布斜率的倒数,那么数量—频率分布斜率的倒数将会是p+1+一个小常量。
[20]这些汉字在减少至语音基础时,在算术—对数坐标方格上从f=100之点到f=2 000之点并非远离线性;对于较高频率,该序列—频率分布明显向下呈凸面,对于较低频率,它又明显向上呈凸面,因此这就表明此样本的大小在最佳规模之上。去除有区别意义的语音声调后只有394个不同“无声调”的词素变体。这20 000个连续汉字的序列—频率分布的线性已经在他处汇报过了20。
[21]我们已经对哥特语进行了分析,只是因为在所有有文字记载的德语方言中,哥特语在形态上最为一目了然,除了大约700年前或更早时期的挪威语铭文由于数量太少而没有统计处理。
[22]根据严格形式基础所作的词语分析与稍作上述校订的词语分析,两者之间的统计差异在图形上难以区分。
[23]总量为大约58 000个连续词语的样本包括:5个不同的10 000连续词语的样本,1个有着6 356个词语的样本,以及有着1 905个词的《斯克林》(译注:《斯克林》原文为Skeireins,是著名的哥特语《圣经》)。它们各自的最小二乘法指数以及X截距的对数(小括号里的数据)分别如下:第1个样本,2.25(2 356);第2个样本,2.13(1 923);第3个样本,2.16(2 137);第4个样本,2.14(1 944);第5个样本,2.19(1 998);第6个样本,2.30(1 763);以及第7个样本,2.14(738)。理论上可以预见,指数增加的同时样本字数总量在减少。前5个样本的序列—频率分布很相似。如果想要的话,我们将来可以专门刊发这些数据。
[24]至于图3-9中德语研究,应当指出约翰·A.华尔兹(John A.Walz)教授建议为此目的挑选这些德语文本,古高地德语的情况除外因为它没有什么选择。每位学生负责完成各自的样本,也就是说,他对自己样本词语作出序列—频率分析(将呈现在稍后的图形中),而且他根据词源词典和现有的比较历史语法将词语分解为他认为的可能是其形态成分。接着,他将这些词素分解为其“词素变体”(没有绘图)以便他自己可能发现统计差异是多么的微不足道,他是根据经常(且自然如此)广泛应用于历史性和对比性研究的某些形态细节作此分析。
[25]关于这一点,最小二乘法直线不会告诉我们任何新意。将一群完美的点连接起来可以画一条“最佳直线”。此外,斜率和误差由于样本规模的不同以及分析技术的可能不同而只不过是过分的挑剔。图3-9所呈现的是其总体图形效果。
[26]单凭音长的不同就能够区别不同音素,如德语中短音ǎ和长音ǎ。例如德语kan(拼写为kann)是“能够”的意思,而kan(拼写为kahn)是“船”的意思;或者man(拼写为Mann)是“人”的意思,而man(拼写为mahnl)是“温暖”的意思。
[27]由田中馆(N.Tanakadate)博士用罗马字母拼写的《用罗马语改写的短篇小说集》(Roomaziaki Tanpen Syoosetusyuu)统计的5 000个日语音位(第1—10页)揭示出如下百分比:p,0.26%;b,1.52;t,9.24;d,2.86;k,6.26;g,2.20;m,3.84;n,5.92。除了p的百分比,这些百分比相差不远。由于我对有些音位的语音结构没有把握,所以没有将这些百分比包括在表3-3中。
[28]正如前面发表的文章用大量篇幅所论述的那样,如果该变化的语音实体只是在某种特殊条件下(如,在重读音节中,或者在结尾部分,或者在元音间)发生变化,那么所有存在这些条件的词语都会发生变化。
[29]对于重音、类推、同化、异化等效果的进一步详细论述已经呈现在早先发表的论文中30。
[30]作为音素即有区别意义的最小单位(这个定义已经成为了某些美国语言学季刊的一款信条)的最后一个反正,我们采用哥特语hausei!即“hear”与哥特语hēr即“here”这个例子,这两个词在au和ē之间明显存在差异。在古英语中,这两个词分别是hiēr!和her,这是个真正的音位对立。但是,如今它们是同音词hear!和here。除非人们荒谬地认为所有语音变化都是瞬间的,我们必须推断出在古英语和现代英语之间或长或短的时期内hear和here的元音在语音技术方面是会引起歧义的(即,音系学家无法知道它们是否仍为不同音位或已经是相同音位)。在进一步论证中,言语流中可能总会有一个在音位上无法归类的剩余物,然而,该剩余物无论是在当下来看还是在过去或将来来看都不是没有区别意义的31。
[31]兹维尔纳的常态曲线的出现在动力学上很有意思。我们认为,除了其他原因,正是言者的经济倾向于缩短发音,而听者的经济倾向于延长发音。这两个对立的“力量”结果很可能就是常态曲线。但是,参见下文对变化不定的音长以及误差的讨论。无论如何,任何语音实体的最小量值似乎是由正常言语环境里所能听见的东西决定的。
[32]因此,假如某特定语言中词语的相对频率与其相对年龄之间存在一种联系,我们或许希望通过简单地检测该语言最早历史文本中词语分布频率发现某些民间的史前文化影响。藉此我们或许可以了解语言的文化层。
[33]我们已经从图2-2中了解到,词语不同意义的数量随着词语频率的降低而减少;因此,我们知道越罕见的词语其功能越少或越专门化。
[34]我发现虽然C线的X-截距是正确的,但是图3-12中该条线的斜率稍微有点不正确。正确的斜率当更好地吻合这些点,读者自己可以通过上述方程式计算后取而代之。
[35]如果我们再去浏览一下图3-10中曲线A英语分布图,我们也会发现古英语存在一个“凹曲线”,该曲线如果绘制在双对数坐标纸上也会近似于一条直线。因此,尽管埃尔德里奇数据与诺特克《混搭赞美诗》中二十多万个词语相比规模相对较小,但是特定“文化层”中词语的直线性在当今英语中并不缺乏。
[36]类似局限性阻止我们在图形上呈现4组5 000个连续词语的数据,不管如何变化多端,该观点可从下面这个事实中获得,即这四个样本中,频率从1到4的不同词语的平均数量以及标准偏差为:(1)137.25±21.47;(2)26±3.32;(3)10.75±3.13;(4)5.75±2.67。频率f=4以上的平均数N是2或1左右,我们在审视图3-13中曲线D时可以发现这一点。
[37]比较语文学家在他们的基因分类上已经认识到了这一点。因此,例如,有着大量来自土耳其语、希腊语、意大利语和斯拉夫语等外来语的当今阿尔巴尼亚语被称作独立的印欧语言,不是因为它自身的印欧语词根占绝对优势,而是因为它为数不多的代词、数词以及其他高频率的实体(即,谚语似的“语言的龙骨”)显而易见是阿尔巴尼亚语的印欧语种。
[38]关于私下个人书信,早在1936年这种顶部凹曲就由怀特霍恩(J.C.Whitehorn)博士发现它相当普遍地存在,他是第一个发现顶部凹曲存在的人。顶部凹曲是与书信的亲密性或口语化有关,而不是仅仅与书信体的书面形式有关,怀特霍恩博士在分析已出版的乔治·萧伯纳(George Bernard Shaw)和艾伦·特里(Ellen Terry)的信件时进一步阐释了这种顶部凹曲;此处萧伯纳书信更加接近调和排列(好像他是非常认真的在给好几个不同的读者写信),而这位女演员的语言揭示了预期的顶部凹曲。怀特霍恩的发现接着在我以前的三位学生研究中得到证实,他们是彭哈姆(W.A.Burnham)先生、希彭·古德休(H.Shippen Goodhue)先生以及科米特·罗斯福(Kermit Roosevelt)先生,他们认真分析了大量亲密私人书信的词语频率分布后发现所有样本都存在一个顶部凹曲。
[39]我的同事詹姆斯·理查德·里德(James Richard Reid)博士正在研究班迪博士的统计数据以及奥特雷·达布斯(J.Autrey Dabbs)先生私人收集并传送给他的法语统计数据。参见他用法语阐述的调和分布,以及他自己在《语言》(Language)第二十期(ⅩⅩ)(1944年)第231—237页中的重要论著。
[40]通过解释当今希伯来语,我们可以认为,如果我们着手恢复古典拉丁语在拉丁语语法框架内运用原始拉丁语词素创造新词语来表达新文化概念和新手工艺品,结果将会是一种“人为建构的”语言,与巴勒斯坦希伯来语想相类似,我们这么论述并非假装为了论述的完整性。当然,在每种情况下,许多古典术语将会得到保留。这种语言的人造性质本身有望在其词素和语音实体的频率—分布中得以体现。顺便说一句,读者不应该将巴勒斯坦希伯来语与依地语混为一谈,前者以闪语为基础,而后者则以日耳曼语为基础。
[41]如果我们指定实际斜率(正或负)为λ,那么p=-λ。
[42]鉴于我们稍后在第五章的论述,我们现在也可以认为,置换经济原则——即将两个或以上不同的行动种类合并起来产生第三个种类的原则——似乎是言语结构相当基本的原则。的确,多能经济原则和特化经济原则二者都是植根于置换经济原则,原因可从第五章论述中推导出。