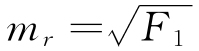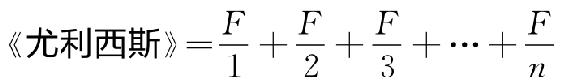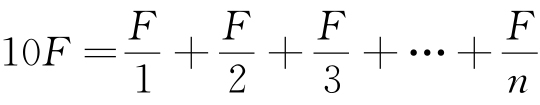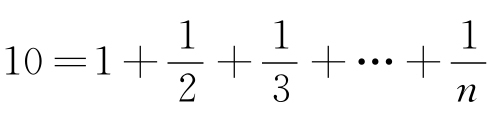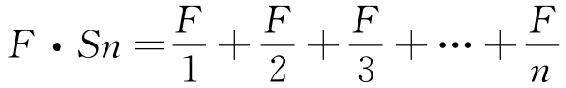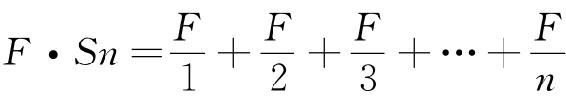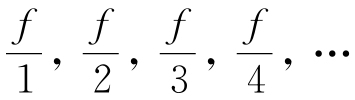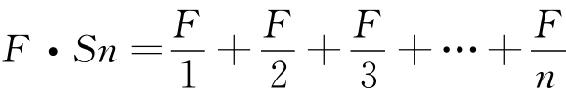第二章
论词语的经济
为了我们其后的研究转向论证最省力原则,我们应该牢记某些通常的考虑因素,这将有助于指导我们的论述步骤。例如,我们应当记住,如果最省力原则的确是人类所有行动的基本原则,我们就有望在我们可能选择研究的任何人类行为中发现这个原则在发挥作用。总之,如果该原则是真的,任何人类行为都会是最省力原则发挥作用的表现形式。因此,所有人类行为都是我们最省力原则这个“磨坊”潜在的“谷物”。
为了经济地论述,我们将首先选择那些最容易揭示这个基本原则的特别人类行为用于我们的论证。也就是说,我们将不断努力从似乎最容易上手的方面着手研究我们假定的这个原则。因为科学论证好比登山运动,登山者要么选择一条最便捷的登山路以期实现登顶的渴望,要么选择一条障碍重重的登山路以期显摆高超的技巧。在本研究中,我们选择看起来最便捷的登山之道。
我们的研究之道始于探究作为一套工具的人类言语。更具体地说,首先研究作为一套工具的言语词汇1。选择词汇作研究的开端是因为,我们也将发现,研究词语为理解整个言语过程提供了钥匙,而研究整个言语过程为理解人格及整个生物社会动力学领域提供了钥匙。因此,本章内容对我们的全部研究将至关重要,因为我们在本章将要把在其他生物社会现象里不断复制的一个结点解开。我们细心周到地打开这第一个旋钮,以便将来的旋钮更容易打开[1]。
第一节 直入本题:词汇用法以及统一化之力与多元化之力
人说话是为了有所得。因此人类言语好比一套忙于实现目标的工具。我们真的还不知道,人们一旦说话,其言语总是旨在获得目标。然而正是这种足够常见的旨向证明我们可以将言语视作一套工具,我们假定事实就是如此。
人类言语传统上看作是一连串附着“意义”(或“用法”)的词语。我们对此传统观点没有异议,事实上我们在此采纳这个观点。可是在采取这个“具有意义的词语”观点时,将此观点与我们先前视言语为一套工具的看法结合起,可能很有益处,即这样表述:词语是为了达到目标而用来传达意义的工具。
然而,一旦我们说词语是工具,就会面临言语可能存在着经济这个问题。每当我们探究言语可能有经济,就会记起单单说话能力几乎代表了当今人类社会活动中一个巨大的便捷,无法说话却是一个重大障碍。既然能够说话的便捷与不能说话的障碍都无可否认地指向力的节省,我们可以说言语的单纯存在中有一个潜在的一般经济,也就是说有些人类目标通过言语比不通过言语更容易获得。相似情况的是一套木匠工具,它的单纯存在对木匠而言可以说是有一个潜在的一般经济。
但是在言语潜在一般经济之外,言说方式还有更多可能的经济。因为如果言语是由传递意思的词语工具组成,那么使用词语——工具以便传递意思就有可能存在一个更节俭的方式以及一个更不节俭的方式。因此,除了言语的一般经济之外,也存在一个可能的言语内部经济。
现在如果我们集中注意力关注可能的言语内部经济,我们就有希望瞥见其本质。因为通常可以感觉到词语是“意义的结合”,言语中潜伏着一个更多节俭和一个更少节俭的方式将“有意义的词语组合起来”,这两种方式是从言者和听者的角度来看的。[2]
从言者的角度看(言者的经济),他不仅选择要传递的意义而且选择传递该意义的词语,毫无疑问,只有一个唯一词语的词汇里存在一个更重要的隐性经济,这个唯一的词语可以意味着说话人要想表达的任何意义。因此,如果要用言辞表达m个不同意义,这个词语就会有m个不同意义。因为通过使用一个独词词汇,说话人将会省却精力,而这个精力是获得和维持大量词汇所必须的,也是从他的词汇里选择具有特殊意义的特别词语所必须的。这个独词词汇,反映了言者的经济,可以比作是一个假想的木匠装备,该装备只有一个木工工具,它可能用作锯子、锤子、钻子等各种功能,因而节省了不然要设计、维护以及使用各种精巧工具所需要的劳动。
但是从听者的角度看(听者的经济),一个独词词汇代表了极端的言语劳力,他将面对一个不可能的任务,即无法确定这个唯一的词语在既定环境中究竟表达何种特定意思。其实,从听者的角度,他需要解码言者的意思,言语的重要内部经济更可能在一定数量的词汇中发现,该词汇的每个词语都表达一个截然不同的意思。因此,如果有m个不同意思,就会有m个不同词语,一词一意。这个在不同词语与不同意义之间的一一对应,代表了听者的经济,将会给听者省却精力,用不着试图确定言者说出的那个词语所指的具体意义[3]。
就词语和意义这个问题而言,我们强调存在着这两种相互矛盾的经济,每一种都与一个词语可能具有多少个不同意思相关。因此,假如有m个不同特殊意思要表达出来,那么会有(1)言者经济,词汇量仅由一个词语组成,而这个词语指称所有m个不同的意义;也会有(2)对立的听者经济,词汇量由m个词语组成,每个词语指称一个不同的意义。显然,这两种对立的经济有着极端的冲突。
我们甚至可以设想一个特定的言语流遵从两个“对立的力量”。一个“力”(言者的经济)往往会通过把所有意义统一在一个词语里从而把词汇规模减少至一个唯一的词语,由此我们可以称之为统一化之力(the Force of Unification)。对与这个统一化之力相对的是另一个“力”(听者的经济),它往往会把词汇规模增加到每个不同词语表达每个不同意义的程度。由于这第二个“力”往往会增加词汇的多元化,于是我们称之为多元化之力(the Force of Diversification)。借助这两个术语,可以说某特定言语流的词汇不断地服从相对立的统一化之力与多元化之力,这两种力量决定了词汇中实际词语的数量n以及这些词语的意义。
采用力(force)这个术语描述假设潜伏在言语中这两种对立的经济,我们必须记住这个术语指称人们实际所做的事,而不是指称人们只要愿意就可以随心所欲地去做的事。因为我们认为,人们实际确实总是以力的最大经济来行动,所以我们认为在言—听的过程中人们自动会把力的消耗最小化。我们的统一化之力与多元化之力仅仅描述两个对立的行动过程,该行动过程从言者或听者的角度来看是一样经济的、行得通的,因此该行动结合言者和听者两个角度同样可以折衷而为。由此可见,一旦某人使用词语表达意思,他会自动通过在这两种经济中找到平衡的方式来最有效地表达他的想法,其中一方面,一种经济是词汇量少、易掌握、指称更广泛,另一方面,一种经济是词汇量大、指称更精确,结果是在他因而产生的言语语流中有n个不同词语的词汇代表理论上的统一化之力与多元化之力两者之间的词汇平衡[4]。
第二节 词汇平衡问题
我们显然还不清楚在我们假定的统一化之力与多元化之力两者之间实际上还存在词汇平衡这个东西,因为我们还不知道总是在节约自己的力的消耗,况且我们毕竟正在尝试给予证明。然而为了说得清晰明白我们列举:如果(1)我们明确认为人确实总是节约自己的力,而且如果(2)我们先前分析这两种力量之间的词汇平衡逻辑是可靠的,那么(3)我们通过直接诉诸有效交际中一些实际言语实例的客观事实就可以证明,我们明确假定的力的经济是真实确凿的。(4)我们尽可能发现有关这两种力量中某种词汇平衡的证据,那么(5)我们就根据事实证明自己假说的(1)力的经济。因此,这主要取决于我们能否从一些在交际效果令人满意的实际言语实例中揭示某些可靠的词汇平衡事例。
幸运的是,如果词汇平衡的条件确实存在于特定的言语实例中,我们将毫不费力地发现了这个条件,因为它正是这两种力量的本质与方向。一方面,统一化之力朝着不同词语的数量减少到1个的方向行动,同时将那1个词语的频率增加到100%。相反,多元化之力将朝着相反方向行动,增加不同词语的数量,同时将这些词语的平均出现频率减少到1。因此,数量与频率将是词汇平衡的参数。
既然言语实例中不同词语的数量及其各自出现频率可以通过经验主义方法加以确定,显然我们下一步将寻找在某些实际言语实例中词语的相关实际经验信息。
一、词汇平衡的经验证据
詹姆斯·乔伊斯(James Joyce)的小说《尤利西斯》(Ulysses)连续有260 430个词语,代表了一个相当大的连续言语,可以公正地说它成功地交流了各种想法。对于此书中不同词语的数量连同它们各自出现的实际频率,迈尔斯·L.汉利(Miles L.Hanley)博士及其同事已作统计,他们十分恰当地认为,所有词语只要它们出现的完全屈折形式有任何“语音上”的不同就是不同的词语(因此,give,gives,gave,given,giving,giver,gift这些形式代表了七个不同词语而不是以七种不同形式出现的同一个词语)3。
除了上述发表的汉利索引之外还有朱斯(M.Joos)博士仔细编写的附录,该附录陈列了大量信息,这是实现我们当前目标所必须的。因为,朱斯不仅告诉我们在这些260 430个连续词语中有29 899个不同的词语,而且按照这些不同词语出现的频率进行降序排序,他告诉我们每个不同词语的实际频率以及伴随该频率出现的不同序列r。通过查阅这个附录我们得知,例如,频率位居第10的词语(r=10)出现了2 653次(f=2 653),或者频率位居第100的词语(r=100)出现了265次(f=265)。实际上,该附录告诉我们所有序列r的词语所出现的实际频率f,从r=1到r=29 899,29 899是该列表的最后序列,因为《尤利西斯》只有29 899个不同词语。
显然,这些词语的不同序列r及其各自频率f之间的关系,对于整个词汇平衡问题很可能十分有意义,不仅因为这个关系涉及不同词语出现的频率,而且因为该列表中最后序列告诉我们实例中不同词语的数量。我们还记得,出现频率与不同词语数量两者都是统一化之力与多元化之力对任何言语实例中假定的词汇平衡起着重要平衡作用的因素。
通过查阅汉利《索引》(Index)的大量数据,我们从毗邻的表2-1随机选择的序列中发现,乔伊斯的《尤利西斯》中r与f之间的关系并非杂乱无章。因为如果我们将表2-1第Ⅰ栏中每个序列r乘以第Ⅱ栏中相应的频率f,我们就会得出第Ⅲ栏中的乘积C,所有不同序列的乘积差不多是同样大小,该乘积如第Ⅳ栏所见代表了构成《尤利西斯》总规模的260 430个连续词语的1/10。其实,就表2-1而言,我们所发现《尤利西斯》中不同词语的数量及其使用频率之间有着清晰的相互联系,即它们俩接近一个等轴双曲线的简单方程式:
r×f=C
其中,r是指《尤利西斯》中词语序列,f是指该词语的出现频率(我暂且忽略乘积C)。
表2-1
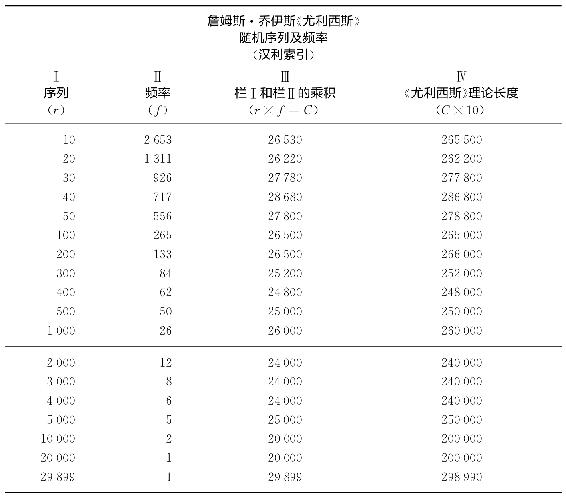
该表数据清晰地证明了词汇平衡的存在。
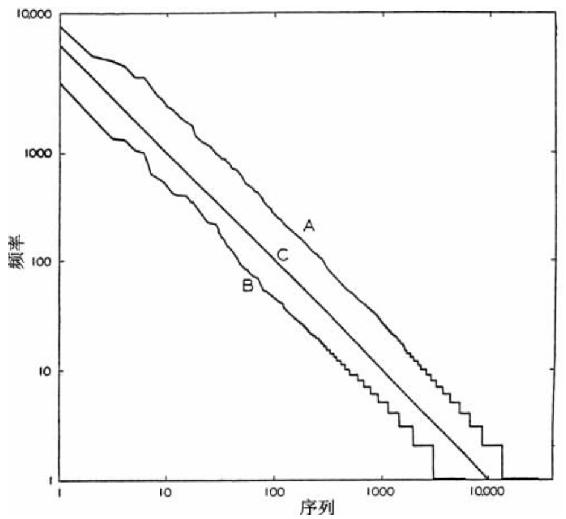
我们不要忘了表2-1只包括了可能的29 899个词语中抽取的一些词语,因此可以合理质疑29 899个不同词语中其余词语之间是否可能存在序列—频率关系。尽管我们不能以表格形式容易地呈现所有不同词语的序列—频率关系,然而可以用曲线图的形式十分方便地加以呈现,因为我们知道,方程式r×f=C在双对数坐标上会以一连串的点在直线上以45°角从左向右下行。如果我们在双对数坐标上将29 899个不同词语的序列及频率绘制成图,而且如果这些点是在直线上以45°角从左向右下行,我们可以认为《尤利西斯》所有词汇的序列—频率分布遵循r×f=C这个方程式,并且该分布表明了自始至终存在着一个词汇平衡4。
至于给这个特别方程式绘制曲线图的细节(这将始终在我们的研究中一再重复),我们将在X-轴或横坐标水平绘制从1到29 899的连续序列,接着在Y-轴或纵坐标上测量频率,我们给每个序列以一个点,对应该序列词语出现的实际频率。我们在完成29 899个序列词语实际频率的绘图后把这些点连成一条线,看看这条线是不是直线,它是不是以预期的45°角从左向右下行。
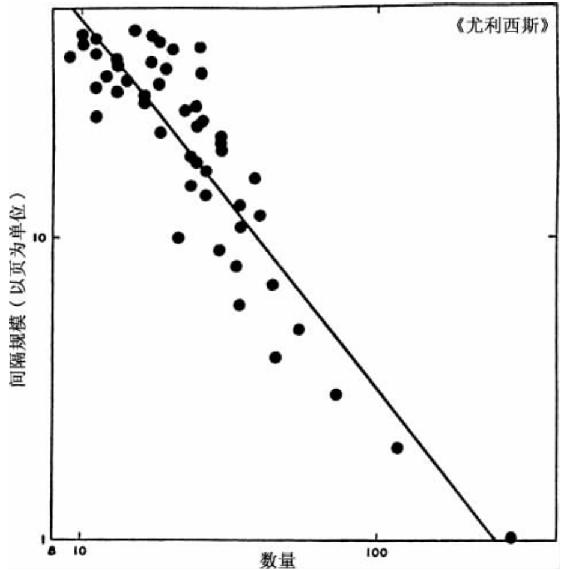
图2-1中曲线A呈现了整部《尤利西斯》按上述说明绘制出的数据,读者自己可能估算出这条曲线几乎是以45°角直线从左向右下行。为了表明就双曲线的序列—频率词语分布而言,不仅只有《尤利西斯》如此,我们还获赠了包括图2-1中曲线B,曲线B是由埃尔德里奇(R.C.Eldridge)分析美国报纸联合实例总计43 989个词语中6 002个完全屈折形式的不同词语的序列—频率分布5。曲线C是45°斜率的理想曲线,添加在此方便读者更清楚地审阅。
图2-1 词语序列—频率分布图。(A)詹姆斯·乔伊斯数据;(B)埃尔德里奇数据;(C)-1斜率理想曲线。
显然,图2-1中曲线与预期45°斜率的直线相当接近,除了随着这条线接近底部时出现了越来越大的“梯阶”。尽管我们马上会发现,这些“梯阶”产生于整数频率且受方程式r×f=C的控制,但是我们现在只可以说,这个数据只在该条线下降到“梯阶”开始之前的地方证实了我们的方程式。可是,我们注意到该直线穿过“梯阶”的延长部分在大多数情况下直接正面切断这些梯阶(原因后文解释),同时注意到“梯阶”因此并非任意出现而是有其自身的条理性,该条理性显然与上述直线的条理性并不相关。
二、r×f=C的意义
在讨论图2-1中出现“梯阶”的原因之前,我们来简要论述这些曲线本身的意义,这些曲线清楚地表明选择和使用词语是某种基本控制原则的根本规律性问题,该原则与我们理论预期的由统一化之力与多元化之力造成的词汇平衡并非不一致。
也许鉴别这些曲线展示的根本规律最简单的方法就是暂时忽略它们是如何真出现了,而相反去探究要是没有基本控制原则介入它们怎样才可能出现。总之,从我们给这个数据绘图的特定方式中我们来探究序列—频率分布的可能和不可能出现的各种方式,我们可以从中发现,这些方式与我们已经观察到的直线分布相一致的可能性是微乎其微的。
首先,既然我们给这些词语按其频率从左向右降序排列,显然将这一连串的点连接形成的一条线任何时候都可能向上弯曲,因为任何时候向上弯曲都会表明根据频率降序排列数据是不正确的。另一方面,一旦相邻序列有着一模一样的频率,这条线就可能而且事实上也会水平延伸(恰好就像图2-1中曲线底部出现的“梯阶”线,我们稍后即将看到)。因此,我们可以提前预言,任何序列—频率分布可能永未从左至右向上倾斜,尽管该分布可能是水平的。但是,不尽然。我们也可以预言,序列—频率曲线永远不会真正垂直向下弯曲,因为这条线必须从左到右将相邻序列的点连接起来。图2-1中“梯阶”看起来是垂直线其实不然,因为它们实际上确实连接起了相邻各点。另一方面,只要这条线从未变成真正的垂直,它会在任何时候以任何斜率向下弯曲。
就我们将数据绘制成图的方法而言,我们可以提前预言,只要这条线从不真正垂直地向上弯曲也从不真正垂直地向下弯曲,这条线在序列—频率分布上从左向右延伸在坐标纸上任何一点都可能会弯曲并转向。关于这一点,读者可以拿起铅笔和纸张从左上角至右下角画各种形状、各种歪曲的线条——这些线条不是向上弯曲也不是真正垂直的——以便弄清楚在我们绘图方法限定范围内存在的大量可能情况。读者在画完他的“任意线条”后就会意识到图2-1中线条的条理性。读者还会明白,这个条理性表明存在一个基本控制原则,该原则决定了言语流中词语使用的数量与频率,不论言者和听者是否知晓该原则的存在,也不论我们所说的词汇平衡之中统一化之力与多元化之力是否给该原则提供了必须的解释。既然图2-1中所有词语在各自实例中都有“意义”,读者或许可以根据词语分布的条理性推断,意义分布中很可能有对应的条理性,因为一般来讲,言者说出词语是为了表达意义。
第三节 意义的条理分布
暂时告别图2-1中词语分布,我们现在关注词语的意义分布这个问题。我们在前文讨论了,在相冲突的统一化之力与多元化之力的作用之下,要表达m个不同意义将会有这样分布,即,一方面没有一个单个词语具备所有m个不同意义,而且另一方面不同词语一定会少于m个。结果,我们可以预期,至少有些词语一定有多个意义。那么将会存在一个意义分布的确定问题,首先要确定哪些词语会有多个意义,接着确定这些多义词会有多少个不同的意义。在解决这个问题时,统一化之力与多元化之力对我们会很有用。
我们首先来关注言语流中最频繁使用的词,特别是图2-1中的实际言语样本。我们随意用字母F1来指称最高频率词的频率。现在的问题是F1所代表的m1个不同意义。这里我们可以说,不管m1有多大,如果我们用f1乘以m1,f1表示m1个意义的平均出现频率,我们将获得F1,因为F1是由其不同意义的总频率构成的。因此,我们可以写成:
m1×f1=F1
记住这个简单方程式,我们来回忆前文讨论的统一化之力与多元化之力并且探究这两种力量各自影响m1和f1规模的情况。显然,统一化之力理论上朝着将所有不同意义集中到一个词语的方向行动,这往往以f1为代价来增加m1数量。另一方面,多元化之力理论上朝着减少每个词语不同意义数量的方向行动,这往往以m1为代价增加f1数量。因此,我们前文方程式中m1和f1各自规模将再次代表相对立的统一化之力与多元化之力的行动。
当然,我们并未先验地了解这两种力量相对强度可能有多大。然而,我们从图2-1数据中已经观察到,在该样本中不同词语数量n及其各自出现频率之间存在一个双曲线关系。因此,我们可以推测统一化之力与多元化之力两者通常彼此存在一个双曲线关系,以至于m1和f1也相互构成一个双曲线关系,接着进一步地导致m1往往等同于f1。
然而,如果m1等于f1而且既然m1×f1=F1,那么显然m1便等于F1的平方根或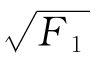 。
。
但是,现在我们来指出,上述论证在细节上作适当修改后也将适用于有mr个不同意义的单词,其相对出现频率为Fr,因此,下列简单方程式也许在预料之中:
这个简单方程式很有意思,因为它意味着,如果(1)我们对言语实例中词语的序列—频率分布作出统计,就像图2-1中对《尤利西斯》和埃尔德里奇数据所作的统计那样,并且如果(2)我们发现该分布会产出一个等轴双曲线的直线,就像图2-1中发现的那样,那么(3)我们可以从上述论证及方程式的本质中总结出的那些词语不同意义在双对数坐标上的序列—频率分布将会产生一条直线从左向右延伸到X=n这个点上,不过该直线在Y-轴上截距只有在X-轴上截距的1/2(即该直线将会有1/2或0.5个负斜率)。这个原因是每个r序列词语的mr个不同意义在双对数坐标上将由一个点来代表,这个点在每种情况下都是各个序列词语Fr的1/2。我们称之为理论上的意义分布法则。
为了从经验上确定这个理论上的意义分布法则是否存在,我们以图2-1中数据为例,在查阅一部合适词典之后我们可以把每r个不同语的mr个不同意义绘制成图,再去发现由此产生的意义—频率分布。这个结果产生的意义—频率分布只是指特定的《尤利西斯》和埃尔德里奇的词语—频率分布,因而缺乏一个更加普遍的适用性。
如果我们选择由桑代克(E.L.Thorndike)基于总数为1 000万个连续词语分析且发表的更加综合的英语词语—频率分布,这将会具有更加普遍适用性和同等有效性,这可以到达我们目的6。尽管桑代克博士发表了他所统计的20 000个最高频率的词语,然而这20 000个词语将代表标准英语的平均频率,比图2-1数据中列举的词汇更有说服力。桑代克博士确实多半忽略了词语的屈折变化词尾,相反他将特定词语几乎所有不同屈折词形的出现频率归入该词语的词典形式下(也就是说,他使用了技术上称作的词法单位)。然而,如果我们将注意力集中在词法单位上而仅仅忽视它的数、格或时态变体,我们没有理由认为这样处理会严重歪曲任何“意义法则”。我们也无需为这样的事实烦恼不安,即桑代克博士没有列举不同词语的实际频率而只是指出前一千个最高频率的词语、前两千个最高频率的词语,以此类推直到前两万个最高频率的词语,并进一步标注了前5 000个词语中的某个特定词语是在各自一千个词语中位居前500还是后500行列。这样处理缺少一个精确的数值标注——虽然还不至于导致他的统计无效——可是给我们的理论带来了名副其实的挑战。因为(1)如果我们在概括图2-2数据时认为这些分布代表了英语这种观点是正确的,并且(2)如果我们理论上的意义分布法则是正确的,那么我们可以推测,不仅(3)桑代克20 000个词语将会遵循词语的双曲线序列—频率分布而且(4)在双对数坐标上将20 000个词语的意义分布绘制成图将会产生如前文所分析的0.5负斜率。因此,通过直接转向分析每个组一千个词的连续二十组中每个组里每个词语的平均m个不同意义,我们可以检验我们理论上的意义分布法则。
幸运的是,为了分析20 000个词语的意义,我们有现成的《桑代克世纪词典》(Thorndike-Century Dictionary),该词典在客观分析欧文·洛奇(Irving Lorge)博士的《英语语义统计》7(The English Semantic Count)的基础上选择了m个不同意义提供给每个词语(除了500个最高频率的词语)。因此,该词典中每个词语m个实际使用的不同意义从经验上得以确定,以至于我们在分析意义—频率时无需担心过时的或即将过时的意义很可能歪曲我们的词语—意义分布。
我多亏有学生帮助,他们负责统计桑代克词典列举的20 000个词语目录中每个词语有多少个不同意义,我们在图2-2中呈现了出来,在横坐标轴上标绘了千词一组的连续词语组,在纵坐标轴上标绘了每组中每个词语的平均意义数量。既然每一千个词语中平均每个词语意义数量实际上是指每千词中第500个词语(或者说是居中)的意义数量,那么横坐标轴上的那些点代表了所有这些千词组中居中词语的意义数量,即它们代表了第500个、第1 500个、第2 500个……第19 500个词语各自的值。
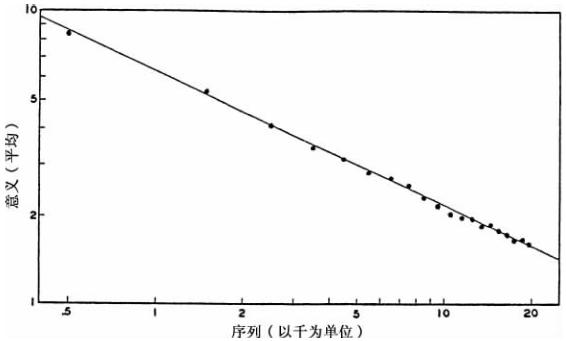
图2-2 词语的意义—频率分布(参见原文第30页)
浏览图2-2中数据足以表明,这些点明显直线下降,这与我们理论上预期的0.5个负斜率(即-0.5)相差不大。如果我们以最小二乘法计算连接这些点的最佳直线的斜率,我们会得出-0.460 5(±0.008 3)值,Y-截距为18.05(逆对数)。计算出的该值与我们预期的-0.5斜率相差并不大8。
如果我们记得《英语语义统计》没有用于500个最高频率的词语(它们意义区分真的很难,原因在接下来章节中清晰可见),这个近似值可能比上文所述值更接近预期值。由于这个因素,我们图表中左边第1个点是可疑的。如果对它忽略不计而重新计算剩下19个点的斜率,我们会得出-0.465 6(±0.002 7)斜率,这稍微更加接近我们预期的-0.5斜率。
如果我们现在将注意力转向每组500个词语的连续10组词语,这构成了该目录中5 000个最高频词语,并且如果我们再次忽视可疑的前500个词语,原因已经介绍了,我们将会得出-0.489 9(±0.003 0)斜率,该斜率差不多非常接近-0.5斜率[5]。
当然,遗憾的是,在此重要时刻没有现成的额外数据。不过,就连这一研究的结果也如此显著,以至于在将来经验分析结果待定时我们给出的结论也不是仓促而为,即意义分布法则是存在的,根据这个法则每千个词语(按照频率降序排列)中平均每个词语的意义数量m等同于该词语平均出现频率的平方根(或者根据序列平方根而减小)。
尽管稍后我们将再次回到“词语意义”的整个问题,同时会遇到对意义这个术语的界定问题9,但是我们甚至现在就可能觉得,我们理论上统一化之力与多元化之力已经引领我们在经验上揭示词语分布的简单方程(其形式为,r×f=C,其中r是整数)以及这些词语的意义分布,后者用方程形式表达即为,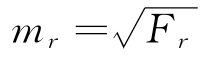 ,其中Fr=Cr。
,其中Fr=Cr。
顺便说一句,我们没有桑代克博士频率列表中20 000个词语的实际序列—频率分布,这个事实并没有否定我们上述结论,相反,我们将在后文中提供许多词语—序列—频率分布,读者们会非常乐意相信,假如我有桑戴克分析的20 000个最高频率词语的序列—频率分布,该分布很可能就会是直线的,就像图2-1中的那些分布一样,至少对于前1万个或前1.2万个最高频率的词语而言其分布很可能会是直线的。
有图2-2意义分布法则的保证,我们现在返回研究图2-1中直线分布的意义,图2-1中直线分布以-1斜率下行,底部量值增加的“梯阶”除外,该分布表明了存在一个词汇平衡。
第四节 频率的整数性
回顾前几页,我们暗示了,图2-1中两条曲线在底部出现的“梯阶”是词语不会出现分数频率这个事实自然出现的结果。既然这类“梯阶”将见于接下来章节的图表中,那么我们此刻离题别论有利可图,我们来转而论述这些“梯阶”大小与方程式r×f=C之间存在着更加精确的关系。
就这些“梯阶”本身而言,竖立线条(或“竖板”)是没有意义的,因为它们仅仅连接了水平线上方的最后一点与水平线下方的最初一点,而且添加这些竖线是为了让读者看得更清楚。另一方面,这些梯阶的水平线(或“梯面”)很有意义,因为它们代表了不同词语或序列的数量,这些不同词语或序列出现的频率是一样的。因此,曲线A紧贴横坐标的水平线代表了《尤利西斯》中出现一次的16 432个不同词语,下一个上方“梯阶”水平线代表了出现两次的4 776个词语,第三条水平线代表了出现三次的2 194个词语,依次上推,直到水平线变得越来越短以至于不再出现。
这些水平线显而易见,其中原因是,如果我们还记得,任何实际言语实例中词语出现的频率只能是整数(或自然数)。因此,任何实际言语实例中,一个词语会出现1次、2次、3次或其他自然数的次数,而不会是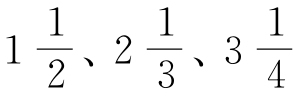 或是任何其他分数的次数。然而,既然我们所说的方程式r×f=C,理论上看词语必有分数的出现次数可实际中又不可能有,很显然在整数频率之间(如2和3之间)的下行对角线上的那些部分实际上不会有序列—频率点。相反,可以容易想象得出,那些理论上应该出现分数频率的频率,实际上以最近的整数频率出现的。也就是说,例如,理论上应该出现
或是任何其他分数的次数。然而,既然我们所说的方程式r×f=C,理论上看词语必有分数的出现次数可实际中又不可能有,很显然在整数频率之间(如2和3之间)的下行对角线上的那些部分实际上不会有序列—频率点。相反,可以容易想象得出,那些理论上应该出现分数频率的频率,实际上以最近的整数频率出现的。也就是说,例如,理论上应该出现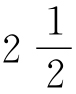 到
到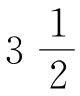 次数的那些词语,根据方程式r×f=C,事实上将会出现3次,因为3是最近的整数频率。并且这也将意味着,上方出现的直线对角线,如果延伸到底部将会大约从这些梯阶水平线的中间切断,正如观察图2-1差不多就是这种情形。因此,出现这些“梯阶”仅仅是方程式r×f=C按照整数频率得出的自然结果。
次数的那些词语,根据方程式r×f=C,事实上将会出现3次,因为3是最近的整数频率。并且这也将意味着,上方出现的直线对角线,如果延伸到底部将会大约从这些梯阶水平线的中间切断,正如观察图2-1差不多就是这种情形。因此,出现这些“梯阶”仅仅是方程式r×f=C按照整数频率得出的自然结果。
其实,方程式r×f=C是“梯阶”出现的原因,也将决定各种“梯阶”的位置和大小,这一点我们马上来解释。
因为可以看出(且在别处已经看出)10,相同f-整数出现频率的不同词语数量N(在方程式r×f=C的条件下)将会与它们频率的平方(差不多)成反比例。或者用稍微更加精确的方程式表达,即:
N(f2-1/4)=C
然而,我们中断论述不是为了由双曲线方程式r×f=C在数学上导出这个新的方程式,相反,我们仅仅认为,如果这个新方程式是真的,我们可以有望在乔伊斯《尤利西斯》中发现,当我们用那个频率平方减去常数1/4之后的值乘以相同频率的实际词语数量N[即,用(f2-1/4)乘以N],结果将会接近常量C。既然这个乘法运算所必需的数据有现成的,我们就立即继续论述它吧。
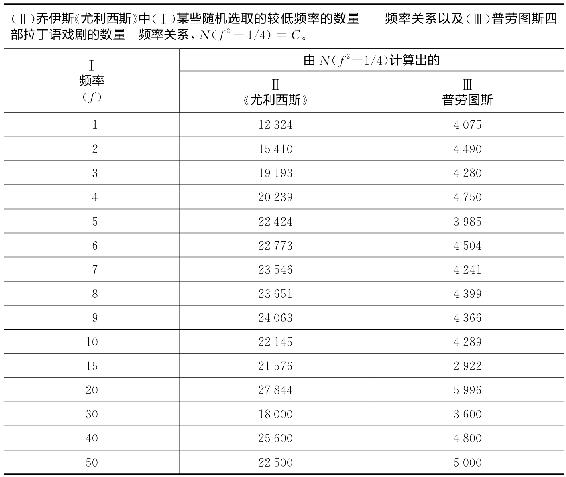
在表2-2中,我们提供了从《尤利西斯》中随机选取了15种频率的词语(栏Ⅱ)按照上述因子计算出的实际乘积,以及用相同方法计算了普劳图斯(Plautus)的四部拉丁语戏剧(栏Ⅲ)中上述因子的实际乘积,我们额外增添后者的计算是为了说明,这种数量—频率关系不是英语独有的特征11。
依次检查表2-2中栏Ⅱ、栏Ⅲ中每个数据,我们发现每栏中计算出的数值对于整栏而言几乎都是一样的,《尤利西斯》两个最低频率的除外。这就意味着《尤利西斯》和普劳图斯的四部戏剧两者在所选取的频率种类上几乎都有同样多的频率相同而词形不同的词语,这些词语的数量是根据我们方程式在理论上应该预期到的。而且那反过来意味着对《尤利西斯》而言更加具体的是,图2-1中“梯阶”的水平线几乎是满足方程式r×f=C的恰当规模,也就是说,理论上有分数频率的词语实际上确实有最近的整数频率[6]。
表2-2
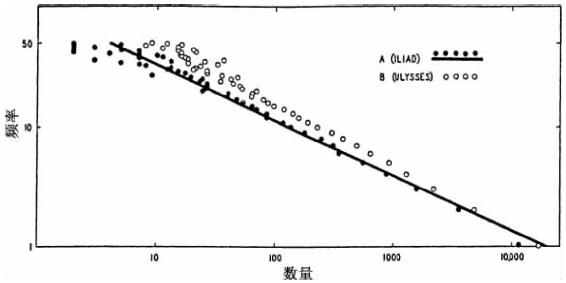
既然可以用图形更加完整地描述上述关系,我们就在图2-3中呈现了(A)《尤利西斯》中从1到50的频率种类的数据,每个圆圈表明了相同频率f(在纵坐标轴上进行对数测量)的不同词语的数量N(在横坐标轴上进行对数计量)。为了测量的全面,我们无偿地增加了(B)非英语语言的相同频率种类的一套数据——这次是荷马(Homer)希腊语《伊利亚特》(Iliad)(以黑点绘图的),取自普伦德加斯特(Prendergast)的《主要语词索引》12(Concordance),这是由我以前的学生哈罗德·D.罗斯(Harold D.Rose)博士耐心细致统计出来的。(普劳图斯材料已经在别处全文发表了。)
图2-3 词语的数量—频率关系。(A)荷马的《伊利亚特》;(B)詹姆斯·乔伊斯的《尤利西斯》
审阅图2-3中两条曲线,我们发现,每条曲线都是从左向右下行,下行方式为X-截距是Y-截距的两倍,正如从N(f2-1/4)=C中的指数2所预期的一样[7]。朱斯博士私底下告诉我(1937年9月16日),《尤利西斯》数据计算出来的指数是在1.99到2.01之间!根据他的计算,表2-2中普劳图斯数据的最小二乘法的指数是1.98。这些指数非常接近我们理论预期值2。我在图2-3中对于《伊利亚特》数据用最小二乘法计算出的是2.15±501[8]。
鉴于词语序列—频率分布中出现的“梯阶”的条理性本质,我们可以说,图2-1中A和B这两条曲线非常接近等轴双曲线方程式。此外,我们无偿增加的其他语言中较低频率范围内的相同频率的词语数量足以确保“词汇平衡”,也就是说,词语的一般条理性不是英语所特有的。我们将在接下来的章节中进一步呈现许多其他语言实例中的序列—频率分布,同时我们会不断再回到统一化之力与多元化之力的这个因素。然而,从一开始我们就将研究英语的特殊情况,这通常也会告诉我们许多有关词汇平衡的本质。
第五节 序列的整数性
词语具有的序列也必须是一个整数。因此,可以有第1个、第2个或第3个序列,但是没有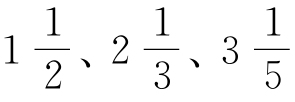 或任何其他非自然数的序列。因为方程式r×f=C没有规定r必须是整数,这个事实引发我们一个非常奇怪的考虑。甚至,就这个方程式而言,r和f两者都可以是从正无穷大到负无穷大中的任何数值,这在言语方面将会不可思议。因此,等轴双曲线方程式不足以完全描述我们的研究发现。我们现在来找一个更加恰当的方程式。
或任何其他非自然数的序列。因为方程式r×f=C没有规定r必须是整数,这个事实引发我们一个非常奇怪的考虑。甚至,就这个方程式而言,r和f两者都可以是从正无穷大到负无穷大中的任何数值,这在言语方面将会不可思议。因此,等轴双曲线方程式不足以完全描述我们的研究发现。我们现在来找一个更加恰当的方程式。
一、调和级数方程式
如果我们回到表2-1并且在“《尤利西斯》的理论长度”标题下检查第Ⅳ栏中的数据,我们发现该栏中各种数据都近似于260 430,而这是该部小说连续词语的总数量。也就是说,当我们用10乘以常量C(r×f=C中的),我们得出该部小说连续词语总数的近似值。这个事实现在引发一个对于序列与频率明显的且有启发性的思考,到目前为止我对此一直忽视了。
在给乔伊斯《尤利西斯》中的词语按频率降序排列时,我们已经根据1、2、3、……n这个简单整数级数加以排列,其中n代表了第29 899这个最后序列以及《尤利西斯》这个样本中最后一个不同的词语。
在观察到一个词语的序列r乘以其频率f的积是一个常量C(根据方程式r×f=C)时,我们可以立即推断出这些序列词语的不同频率f将按照下列简单调和级数的比例依次下降:
1,1/2,1/3,…1/n
因为每个频率f在乘其序列后将得到一个常数。
这个调和级数现在很有意思。因为如果我们说F代表了最高频率词语的实际频率(即,这个序列r=1的词语),那么F/r将会是任何序列r词语的实际频率。因此,例如,第10个最高频率词语(即r=10)将有F/10这个频率,并且第n个最高频率词语(即r=n)将会有F/n这个频率。
其实,我们可以将整个《尤利西斯》看成是n个不同语的下列F总和近似值,并且是按照频率降序排列的:
上述这个方程式中分数的分母是指各个词语的连续序列,其中n=29 899。
然而,此刻一个奇怪的考虑出现了。既然我们可以根据表2-1推理出,乔伊斯小说中连续词语总数约等于10乘以序列为1的词语的频率F(即,1×F×10=约260 000),我们就可以说10F大约就是《尤利西斯》的规模。实际上我们甚至可以对于《尤利西斯》所有词语列出下列近似方程式:
我们在检查这个方程式时发现,上次分析时我们仅仅用F乘以下列简单方程式:
而且这又反过来意味着,表2-1第Ⅳ栏中常数10完全代表了上列方程式中右边成员的调和级数分数之和。
现在一个调和级数的n个分数加在一起将得到一个总数。一个调和级数的n个成员之和在技术上可以用Sn表示(这意味着该级数n个成员之和S)。Sn的大小显然将取决于n的大小(即,相加分数的数量),因此,我们如果知道n的值就能算出任何Sn的近似值(且反之亦然)。
可是,此时我们得小心。虽然这个实际值Sn=10对于理解《尤利西斯》可能很重要并且已经发现了一个相同的常量大约可以描述埃尔德里奇的报纸语料,然而Sn=10这个特殊值对下列事项无足轻重,即对于理解调和级数,或方程式r×f=C,或最终对于统一化之力与多元化之力,或假定藏身于这两种力量背后的最省力原则而言是毫无意义的。Sn的大小仅仅告诉我们n(使用不同词语的数量)的大小。10以外的值同样可行。其实,我们在第四章将会发现,儿童有限词汇中的Sn典型小于10。因此,为了避免把我们的调和方程式与任何特定的Sn值联系起来,我们将用下列普通形式呈现这个调和方程式,这将足以描述我们以后的许多组数据:
从图形上看,上述这个调和级数方程式将会以一连串点的形式出现,如果像图2-1中用线连接起这些点,将会以45°角从左向右下行(技术上称作负斜率为1),这与图2-1中的曲线一样。Sn的大小只是有助于在X-轴上定点,垂直曲线将与X-轴形成截距:Sn值越大,直线在该图形上的定位越靠右。此外,如果我们假定当这条线在X-轴与Y-轴上截距相等时(而且这很重要),上述调和方程式是饱和的,那么我们可以在代数上说,上述饱和形式的调和方程式是指F=n这个条件或者指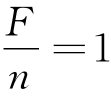 这个条件。而且这反过来又意味着第n个词语在该样本中只出现一次。
这个条件。而且这反过来又意味着第n个词语在该样本中只出现一次。
现在,这个饱和形式的调和方程式(此后缩写为F·Sn)比双曲线方程式r×f=C更加忠实地描述了图2-1中的近似数据。因为调和方程式F·Sn告诉我们r必须为整数,而且,由此我们能够容易在数学上预计,这些“梯阶”自然产生于频率f只能是自然数的事实。
因此,让我们记住,将来无论何时我们发现了一个序列—频率分布,如图2-1所绘制的,它的斜率为-1(即,其Y-截距等于X-截距),那么我们就可以推理出该分布就是F=n的饱和调和级数分布。
二、样本大小与言语闭合的问题
尽管我们已经对词语的数量与出现频率作了较深入的分析,可是还存在一个基本问题,我们现在转到这个问题上,即研究对象言语流样本的优选规模这个问题,也就是说,样本规模是“适中的”,不“太长”也不“太短”。我如果借助一个简单的机械音叉类比就能最容易阐明这个问题的本质,即n个不同音叉代表n个不同词语,不同音叉的频率f对应词语的频率f。
我们设想有一个长板,上面附加了n个不同规模的音叉,它们在T间隔时间内都将根据饱和调和方程式各自振响,其中F=n的,即:
音叉代表了一个同时现象即它们同时一起振响,而言语流却是一个历时现象即一次只能说出一个词语,如果我们暂时认为这个事实无关紧要而忽略不计的话,那么到现在为止音叉在T间隔期间的群体行为对应言语流中言语词汇的群体行为。当我们在一段既不比T短又不比T长的t间隔期间去振动这个木板,这个机械类比的主要说教价值就呈现出来了。
如果我们以比T短得多的t间隔时间去振动木板,那么结果产生的群体振动的频率分布就会远不同于饱和调和方程式F·Sn计算出的频率分布,如果只是因为那些较低频率的音叉来不及发出所分派的少量振动。转到词语现象中,我们可能觉察到,同样这种关系也将存在于特别短的言语样本中,比方说,100个词的言语样本,在这样的言语样本中,可以想象最高频率的词语可能没有机会重复,更不用提那些更难得出现的词语,它们可能根本就没法出现。在这么短的样本中,大多数词语至多只出现一次,我们很难从中发现这个只在连续词语样本规模接近F·Sn时才会出现的基本调和级数。
另一方面,如果我们扩大音叉振动间隔时间,超过T到T+t,那么我们将超越F·Sn这个饱和级数。因为,尽管在T+t间隔内T期间振动总和将代表方程式F·Sn的部分,可是在整个T+t间隔期间所有振动之和从图形上看很可能会产生一个弯曲的、失真的序列—频率分布图(虽然这将主要取决于t的大小)。而且类似情况也会出现在连续词语样本为F·Sn+a中[9]。
因此,这个F·Sn样本的词语规模,就像音叉振动间隔时间为T一样,代表了一个优选规模,在这样规模内饱和调和方程式将会精确地呈现出来。虽然此刻我们可能不会停下来追问,如果样本明显背离优选规模,那么序列—频率分布如何在图形上呈现,但是我们承认,非常幸运的是,早期经验主义者碰巧研究的言语样本的大小相当接近优选规模。因为,如果他们选择的样本规模很小或很大,那么序列—频率的线性关系可能很难揭示出来[10]。
既然我们已经强调了这个明显的道理,即有关F·Sn这个连续词语的调和方式只会出现在规模非常接近F·Sn这个连续词语的样本中,那么我们继续作进一步的论述。如果言语流中词语的数量与频率是相对立的统一化之力与多元化之力产生的结果,(或者是其他有关“力量”的结果),那么F·Sn个连续词语的间隔作为一个单位很可能具有动力学意义,可以据此认为一个特定说话人讲得“太少”或“太多”。也就是说,如果我们明确地认为,F·Sn这个调和级数代表了一个基本原则控制着言语中词语的数量及使用频率,那么我们只能推断,一个特定说话人“自然”以下面这种方式选择谈话主题以及选择表达该主题的词语,这种方式是,该说话人持续的言语流产生的频率—分布将会满足方程式F·Sn的所有要求,既没有讲得“太少”也没有讲得“太多”。而且这反过来又意味着在言语流中固有存在一个动力学单位,我们称之为闭合(或循环,或律动),该动力学单位可以大致界定为言语长度,在这个长度内一组特殊言语工具一次性完成了它们的集体行为。这个闭合可能意味着我们还不知道的其他什么东西。事实上,我们只是在观察言语(以及我们类比用的音叉)使用的特殊方式时偶然发现了这个闭合的存在。我们将在第七章发现,言语流能够得以组成的方式中可以没有必然的闭合,而且人格分裂症言语的特征差不多就是没有闭合。
但是,闭合概念导致了一个更加重要的考虑因素,一旦我们提出下面这个问题,就会显露这个因素,该问题的答案,我们已经部分地预见了:假如你只能获得次优选样本去分析,那么你将永远不能识别词语数量与使用频率中的基本原则吗?
这个问题的本质最终是指使用率,我们可以借助前文的音叉板作简要说明。现在我们将在t间隔时间内振动音叉板,该t间隔时间如此短暂以至于调和级数不会很明显。这样处理后,我们面临查明整个音叉板的基本调和级数问题,为此,我们研究了几个高频率音叉的一些振动,这几个音叉来得及完成几次振动,藉此我们只获得了整个音叉板结构信息。我们在检查这些为数不多却较为频繁的振动后将会发现,特定音叉的振动率越高,它在t间隔期间内累积的振动频率f就越接近与调和级数的比例:
我们是否能够根据这些调和振动推理出整个音叉板成调和级数,这有点取决于t间隔的大小。
现在转至言语现象,我们是否可以根据上述机械类比推理出,规模很小的样本中词语重复的比率也会给我们一个相应的线索去发现词汇使用中基本的调和级数?显然我们还没聪明到从言语实际中得到这样的推理,因为我们根本就不知道言语流中词语重复的比率,所以我们不可以臆断音叉类比在这个方面是一个正确的类比。
就词语单纯调和方程式F·Sn而言,唯一可知的结果是各个词语出现的全部频率,而不是这些词语的出现率,也不是它们重复之间的间隔长度。例如,无论最高频率词语的F/1出现的次数在言语中是一个紧接一个集中在一起,还是在每隔Sn连续词语后出现一次,还是按照某个其他方式出现,这对于饱和方程式F·Sn而言没有任何区别。因为只要最高频率词语在F·Sn个连续词语出现F次,不管它的F个出现次数如何因时分配,它就符合这个调和方程式。而且经过必要细节修改后,这些连续词语中其他词语也同样如此。
因此,很清楚的是,这个调和方程式F·Sn尽管就其本身而言显然具有极高的描述性价值,然而其本身作为一个完整的描述还不具有最终效力,因为它没有告诉我们任何有关言语流中词语重复之间间隔长度的东西。我们来转到这个主题。
第六节 重复之间的间隔长度
也许理解词语重复之间的间隔长度这个问题最简便的方法就是,去发现乔伊斯《尤利西斯》这样的大篇幅言语实例中究竟是怎么回事,为了这个目的而采用《尤利西斯》为样本,似乎是由现成的汉利优秀《索引》所推荐,后者标出了所有使用次数为24或以下的词语所出现的页码。
1937年我当时的学生亚历山大·穆雷·弗勒(Alexander Murray Fowler)博士,前文某处已提到过13,曾组织一次专题学术研讨会,初步探究了乔伊斯的《尤利西斯》中所有出现5次、10次、15次、20次以及24次的不同词语重复的间隔页数(这是从汉利《索引》中加以确定的)。他发现了间隔长度与有该长度的间隔次数之间存在一个有趣的相反关系。
在讨论这个相反关系之前,我们首先来讨论弗勒研究程序,该研究程序尽管难免繁重,可还是分析得简洁明了,基本如下文所示。比方说,每个出现5次的词语被视作在其出现之间有4个间隔I。而且这4个间隔中每个间隔长度按照间隔的页数依次减掉各自在《索引》中所列出的页码便可算出。更明确地说,第1个间隔规模是由这个词语第2次出现时所在页码减掉该词语第一次出现时所在页码的差,同样,n-1间隔是由本讨论中任何词语在第n次出现时的所在页码减掉该词语在第n-1次出现时所在的页码的差。
如果这个词语在同一页重复,这个差数当然是零,间隔自然也为零。为了避免下面计算中出现零的情况,我随后给所有的间隔数加上1,例如,如果两个相邻页码的实际差数为20页,那么由此给出的间隔被认为是21[11]。
在确定《尤利西斯》所有出现5次的906个词语(共计有3 624次间隔)每次的间隔规模之后,弗勒接着将各种间隔规模I的出现次数列成表格,将所有第1次间隔,第2次间隔,第3次间隔以及第4次间隔的间隔规模列成表格,将所有这些间隔各自列成表格同时又把它们结合起来列成表格。在所有这些情形中,他不仅发现了短时间的间隔比长时间的间隔数量要多得多,而且还发现了间隔规模I相同的间隔数量与I的大小负相关或者用一般方程式表达如下:
Np×If=常量(近似值)
在这个方程式中f是指那些频率相同的不同词语的出现频率,其间隔正在被计量(在当前情况下,我们正在处理《尤利西斯》中所有出现5次的词语,或者f=5,我们可以说I5)。此外,指数p从图形上看代表了拟合这些点的线条的绝对斜率,我们以N为横坐标轴、以If为纵坐标轴在双对数纸上将该数据绘制成图,如图2-4所示[12]。
图2-4 间隔—频率关系。乔伊斯《尤利西斯》中重复出现5次的词语之间规模相同(用页数计量)的不同间隔数量
上列方程式使用更通用的术语If而不是I5,是因为间隔的数量与规模之间的相反关系同样也见于《尤利西斯》里分别出现10次、15次、20次和24次的各个词语中。我们对弗勒的研究数据进行常规例行检查之后发现该数据高度精确,接着我们将这种分析扩展到对《尤利西斯》中出现6次、12次、16次、17次、18次、19次、21次、22次、23次以及24次的词语,出现24次是汉利《索引》给出页码的最高上限次数。在所有这些情况下我们都发现同样存在这种相反关系,然而从数学角度研究这些数据时我们发现这个方程式中常量的大小差异显著,这一点我们在讨论截距时即将见到。
为了从图形上阐述上文提到的数据的本质,我们在双对数坐标图上以N为横轴以I5为纵坐标绘制了图2-4,呈现了《尤利西斯》中所有出现5次的906个词语从I5=1页到I5=50页的所有重复之间间隔的具体数量与规模。图2-4数据的最佳Y's线的负斜率(其中Y=logIf)由最小二乘法计算为1.25(均方根差是±0.168)。因此,如果我们记得I5只有从1到50的整数值,我们可以用这个方程式在数学上描述这些点:
N1.25×I5=常量
至于其余频率级别(即,那些各自出现6次、10次、12次、15次、16次、17次、18次、19次、20次、21次、22次、23次以及24次的词语),显然我们没有足够的文本空间给它们逐一绘图。可是,既然我们只对我们材料的斜率和误差感兴趣,我们在表2-3中能够并且将要以表格形式给上述所有各类频率呈现出完整信息。该表格的第Ⅰ栏为第Ⅱ栏中各种出现频率类别列出15种不同分析,所有出现频率对应的不同词语数量列在第Ⅲ栏,借助该表格我们在第Ⅳ、第Ⅴ栏和第Ⅵ栏中发现了有关斜率、误差等方面的预期信息。第Ⅳ栏是由最小二乘法计算的最佳Y's线的负斜率。第Ⅴ栏是有此斜率的各条线的均方根差。第Ⅵ栏是最佳Y's线的Y-截距(实际上是Y-截距的逆对数)。第14F的分析是弗勒博士对I24所作的分析,而第15Z的分析是我对I24所作的分析,我们把这两个分析包括进来是为了说明他的分析与我的分析非常一致。
这些计算基于由1到21而不是由1到50的间隔规模,所有15个不同分析都是按照同样方式处理的,图2-4中的数据就是这种情形。对当前语料的计算限定在第21个最小间隔规模之内,这是因为有几组数据没有出现部分较大的间隔规模(即N=0)——这一事实使得计算和比较更加困难。那么为了能够比较所有15组数据,If的上限减少至21页的间隔,因为所有这15组数据都有从If=1到If=21的间隔例子。这些21个最低的间隔单位足以揭示整个表格材料里是否存在任何系统化的可能。
表2-3
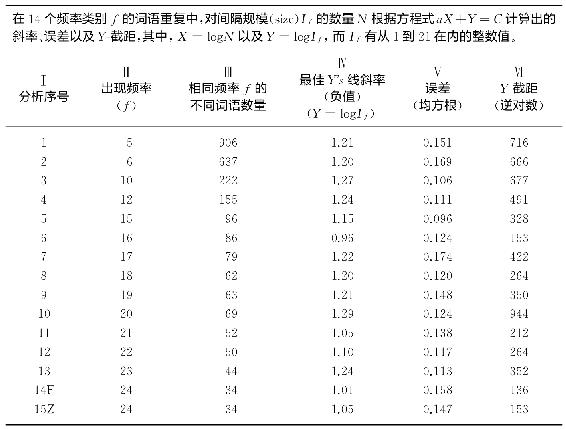
现在转到表2-3第Ⅳ栏中所有条目,我们发现负斜率在0.96到1.29之间中位数为1.20。第Ⅴ栏中误差大小在较低、中间或较高频率类别上的偏差没有明显联系,但是似乎在这15个分析中分布得不偏不倚。
至于第Ⅳ栏中位数为1.20的那些斜率,我们可以无所畏惧地说这些数值的高度一致杜绝了纯粹随意或偶然。事实上它们明白无误地表明了在N与If之间存在一个基本的相关性。而且既然这种相关性对于我们研究的平衡具有重要意义,我们现在简要列举可以想象得到的那些不同意见,它们反对我们将这个相关性看作具有根本意义。
首先,不能反对说这种相关性只是源自我们仅选择了21个最小间隔规模的事实,因为在图2-4中我们发现50个最小间隔I5的负斜率为1.25、误差为±0.168,这与表2-3中第一个分析没有显著差异,后者分析的21个最小间隔规模I5的斜率为1.21、误差为±0.151。因此,通过双倍多的间隔规模范围,我们没有明显改变斜率或误差。此外,我们在图2-5中呈现了I24的所有数据,我们审查发现,这种相关性对于所有间隔规模包括50页以上较大间隔规模而言都是确凿有效的。
其次,这种N与If之间的相关性不能归因于我们决定选择1页作为测量单位的事实,因为如果我们使用的测量单位是2页或1/10页、或者我们用其他常量乘以If、或者用词语而不是页数作为测量单位(在词语重复频率最高的情况下,建议可以使用这种运算方法),这种相关性依然会存在。这种相关性也不是源自我们为了避免出现零的运算而给每个间隔规模武断地加上1页这个事实,这个加数可能稍微修改了每个斜率的数值但是没有改变所有斜率之间的基本一致性。
第三,这种相关性不能因为我们认为没有超过I24的斜率类别而遭否认,我们记得就汉利《索引》给出所需页码而言I24是最高频率类别。相反,恰恰是较低频率词语中这种相关性的存在,才是其最惊人的一个特征。因为我们可能想象得出有望找到每100个词语中出现1次、2次或3次的高频词语重复间隔的某种控制原则,却找不到每100页中出现1次、2次或3次的词语重复间隔的某种控制原则。
最后,也是最重要的一点,我们不可以忽视这种相关性并非为先验上的必须。因为实际上一个模拟的言语样本可能被构建出(众多不同可能之中)时每个间隔都是1。甚至,没有任何先验上的原因可以解释N与If之间的这种相关性必须存在,仅这一点足以证明我们有理由承认这种相关性的存在。
于是我们因而认为下列方程式代表的关系是本来就存在的而不是一个统计制造的东西[13],我们将在这个信念的基础上继续研究。
Np×If=常量
我们在说N×If=常量这个方程式呈现了所有出现频率相同的词语重复间隔时必须注意到其中原因远多于该方程式实际所描述的。因为尽管该方程式描述了短间隔的双曲线性优先,但是对于(1)一方面,最短间隔在全部词语重复中是否要么早出现要么晚出现,或者对于(2)另一方面,不同规模的间隔是否将在整个语言样本中平均分布,该方程式却无明确意义。实际上,正如我们将在表2-4和图2-5的数据中看出的,有意思的是,第二个最终结果(2)是毋庸置疑。
表2-4
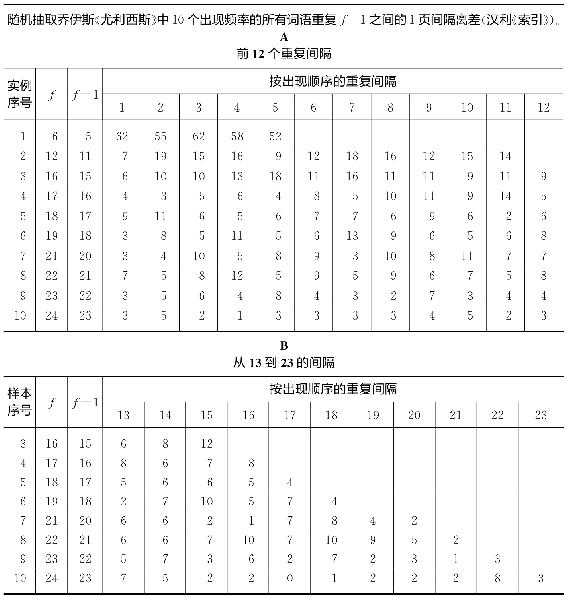
为了阐述第(2)点,我们分析了频率类别,随机抽取了10个类别,对每个类别中所有词语f-1重复的所有1页间隔(即If=1)的离差在表2-4中加以呈现。在表2-4中,显然最短间隔在整个样本的开始、结尾、或任何部分都没有明显的优势。实际上,它们似乎差不多分散在各自连续的间隔中。间隔规模从If=2到If=21的情况同样如此,我们分析的所有其他间隔规模也是一样(尽管限于篇幅不在此列出)。
此外,图2-5是表2-3中所有15个不同样本的典型图形,我们从中发现了《尤利西斯》中所有出现24次的词语中所有间隔规模的完整离差散布图。重复之间的23个连续间隔在算术上由横坐标表示,而实际间隔规模I24在对数上以纵坐标测量。这些小十字图形标出所有间隔的大小及其出现位置。本数据来自表2-3中第15Z条分析。
图2-5 詹姆斯·乔伊斯《尤利西斯》中出现24次词语的重复间隔分布
就我们所见而言,图2-5中十字图形在散布图中分布非常均匀,没有丝毫进一步的系统化。其余14个样本的散布图也同样如此,尽管我们限于篇幅没有呈现于此。所以,方程式Np×If=常量(近似值)不仅适用于每个特定频率类别的所有联合的f-1间隔,也适用于各个频率类别的单独每个f-1间隔。换言之,在我们分析间隔规模分布的基础上大体上可以说,我们发现N与If之间的相反关系不仅适用于整个频率类别f的各种间隔,而且也适用于该类别的每个连续f-1间隔14。
既然我们已经确立了词语重复之间的间隔数量与间隔规模之间存在相反关系,那么剩下的任务就是探究这种相反关系存在的动力学原因。
第七节 功力因时分配的问题(功力因时平均分配)
我们花了好几页的篇幅一直积极埋头定量研究词语现象,以至于我们对最省力原则的兴趣被遗忘在讨论的背景之中。然而,现在当我们将注意力转移到探究N×If=常量(近似值)这个定量分配的动力学原因时,我们当好好考虑先要了解该分配按照最省力术语可能意味着什么。而且如果我们记得在表2-4和图2-5数据中各种间隔规模If在该样本全部时间内是平均分布的,那么我们可以推测言语流中词语及其重复的空间所涉及的力(Effort)也可能是因时平均分配。这个推测使我们开始考虑迄今多半被忽视的时间概念,所有功力都消耗在时间里。
使用术语功力因时平均分配,我们只能意味一件事,即,在间隔时间T内消耗的全部功力W将以这样一个比率来消耗,该比率是任何单元间隔时间t内将消耗等量功力w,或者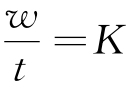 。
。
就F·Sn连续词语构成的言语样本而言,功力因时平均分配将意味着,在样本期间所消耗的全部功力分配是,每二分之一样本期间花费等量功力,每四分之一的情况也同样如此,如果继续分下去,Sn连续词语中每F数量的情况也都如此。这就是说,不论选择什么时间单元,功力消耗的比率一定是尽可能地接近常量。
既然我们已经界定了我们所说的功力因时平均分配概念是什么,接下来的任务就是按照功力因时平均分配在理论上解释这个词语方程式N×If=常量(近似值)。为此,我们第一步(1)将是构建一个机械类比[钟铃类比(the Bell Analogy)],其中,最少功力因时平均分配,而且我们将发现能够用我们已经观察并用于描述言语流中词语分布的同样方程式来描述钟铃声的频率分布,这个类比将引出时间视角(time-perspective)这个概念。接着(2)我们将简要概述本章内容,以便我们熟悉本书其余内容,最省力原则将在本书其余部分始终作为所有生物社会现象的一个根本性控制原则。
一、钟铃类比以及“时间视角”的意义
为了先从理论上解释各种方程式,我们以n个钟铃为例,它们同样大小同样难以鸣响[14],我们将它们安装在一个长平板上,沿着木板均匀摆放,顺便提一下,该木板不断抵抗所有运动。在木板的一头我们将放置一块黑板,划出n栏分别对应每个钟铃,同时我们也在那儿安置一个敲钟精灵(demon)充当敲钟人。这位敲钟精灵必须每秒敲一个钟铃,而且他每次敲完钟铃后必须返回到黑板处在黑板上对应该钟铃的一栏上作个记录。因此,为了给一个钟铃敲10次或者给10个钟铃各敲一次,他在任何一种情况下都要沿着这个木板并且在这10秒钟内往返10次,因此将在黑板上作10个标记,而且因为我们将要求这位敲钟精灵沿着最短的距离往返跑,他所有的功力因而将是最少的。
这个类比很有意思,理由很多。首先,按照敲某特定钟铃往返一趟计算,这位敲钟精灵的全部功力w将与从黑板到钟铃的距离d成正比例增加(或者w=d)。而且由于各个钟铃与黑板的距离根据级数1d,2d,3d,…,nd成整数增加,敲钟精灵往返各个钟铃的功力也将根据级数1w,2w,3w,…,nw而增加。
现在,如果我们要求敲钟精灵随着一个频率f敲响每个钟铃,该频率与敲钟往返的功力w成反比例——或者用方程式表达为w×f=C——他将相应更频繁地敲击近的(因而也更容易)而不是远的(同时更难)钟铃。而且,由于频率序列r是降序排列,每个钟铃敲击频率序列将等同于该钟铃上述的w,所以我们得出这个熟悉的方程式:
r×f=C
然而,如果我们现在要求这位敲钟精灵根据这个方程式去敲击所有的钟铃,但是在敲击一次第n个也是最远的一个钟铃后停下来,以及在敲完所有其余钟铃所指派的频率后也停下来,那么这些n个钟铃将大致根据这个方程式被敲击:
其中F·Sn代表了往返的全部趟数(也是全部“秒”数),其中F代表了距离最近的钟铃的全部频率,F=n。上列方程式只是个近似值,因为没有分数频率,其原因上文已经陈述了。
上列方程式F·Sn对于该敲钟精灵敲钟的顺序没有限定。因此,他可以敲击最近的钟铃所指派的F次,再去敲第二近的钟铃所指派的F/2次,依次类推沿着木板敲钟,直到敲一次第n个也是最远的那个钟铃。总之,他可以总是“最容易逗留的钟铃最先”敲从而尽可能拖延敲击较远同时因而更困难的那些钟铃。“最容易的最先”敲的主要缺点是,该敲钟精灵将不得不跑得越来越快,于是,随着沿木板前行越来越远,假如他在规定的一秒内完成每个往返,他的功力比率因而总是在逐渐增大。他这样做就是因时非平均分配功力并且冒着在敲第n个钟铃前可能崩溃的风险。
为了改正这个功力因时非平均分配,我们要求这位敲钟精灵尽可能因时平均分配他的功力,还是按照方程式F·Sn来敲钟。然而一旦他确实因时平均分配其功力,他就会立刻自动以下面这种方式敲钟,即各钟铃重复间隔规模If接近一般方程式:
N×If=常量
接近这个方程式的理由是,这位敲钟精灵一秒一秒地用累积的频率f抵消累积的功力w,即,他将努力在每1/2的F·Sn秒内消耗一半的总功力,每1/4的F·Sn秒内消费1/4的总功力,在每Sn秒内消耗1/F的总功力,依此类推。或者换言之,这位敲钟精灵每敲一个远距离的w较大的钟铃,他将必须敲击一连串或一簇距离更近的w较小的钟铃。
确实,如果我们把这位敲钟精灵的全部活动视作是把那些难敲的钟铃与一簇簇容易敲的钟铃分散开来,或许我们能够很容易理解为什么重复之间的短间隔比长间隔在比例上更多。因为,首先我们知道钟铃的w越大就越少敲击,同样地,用来平衡的一族更容易敲的钟铃越多(也就是说,在乘以功力时更容易敲的钟铃的鸣响次数越多),这簇钟铃就越少出现。正如距离越远的钟铃和簇越长的钟铃在比例上更稀少,更容易敲的钟铃以及簇更短的钟铃在比例上也就更频繁。
现在,既然这一簇钟铃是由更容易敲的钟铃构成(即,它们按比例地包括更容易敲击的钟铃),而且既然一个钟铃越容易敲,相应地它就敲的更频繁,结果就是这一簇钟铃的重复敲击率高于平均重复率(即,它们敲击的间隔远远短于平均间隔)。其实,这一簇钟铃重复敲击之间的短间隔不仅超过平均水平,而且比例上也如此。因此,在这些一簇簇钟铃里我们差不多有望发现方程式N×If=常量(近似值)。
所有这些重复之间的间隔规模不仅在这些簇内部而且是在这些簇之间计算得出的。然而,既然这些簇的大小往往与其数量成反比例变化,于是这些簇之间较短的重复间隔也就相应地多于较长的重复间隔。因此,在计量同一个(任何频率类别的)钟铃的鸣响间隔规模If的数量N时,我们发现近似于方程式:
N×If=常量(近似值)
而且这是真的,像前文所说的那样,因为我们的敲钟精灵不断快速重复敲击木板近端更容易敲更频繁响的钟铃,这就抵消了木板远端更难敲击且更稀少鸣响的钟铃。统计分析可能将黑板上累积的标记减少到一个与图2-5相似的散布图。如果我们给每个钟铃起一个不同的名字并且敲钟后记下它的名字,那么这一系列名字的频率分布就会与乔伊斯的《尤利西斯》中一系列词语的频率分布差不多。也就是说,这些钟铃敲响的一系列名字将构成一个模拟的连续言语样本,在这个样本中我们应该会发现在论述乔伊斯的《尤利西斯》时迄今所得出的几乎所有方程式。
现在由方程式N×If=常量(近似值)可推理出其他方程式,尽管逆推并不成立。因此,在这一点上方程式N×If=常量(近似值)可看作是其他方程式的基本方程式——我们即刻将转而论述这一点。
但是在我们转到上述钟铃类比中数量—间隔的基本关系之前,我们将强调这一点,即,确实可以想象得到钟铃类比的运作可作其他解释。因此,这个敲钟精灵可能敲击第n个钟铃一次而敲击第1个钟铃F次,在两者抵消之后,他将用木板近端频繁且更易鸣响的钟铃声抵消木板远端稀有也更难鸣响的钟铃声。然而无论怎样解释这个类比,这位敲钟精灵仍将用稀少的困难行为抵消频繁的容易行为,这样的话在每Sn秒内他将消耗尽可能差不多全部功力的第1/F份额。因为每Sn秒内所耗功力超过平均值(即,已经消耗的功力超过F/W——这种情况只发生在敲响均数以上的难敲钟铃的时候)就一定对应着Sn秒内所耗功力低于平均值(即,消耗的功力少于F/W——这种情况只发生在敲响均数以上的容易钟铃的时候。)因此,较短的重复间隔相应地要多于较长的重复间隔。
我们的敲钟精灵在面对钟铃类比这个问题时是在处理一个真正的组群问题,在该组群的问题中,每个动作引发一定量的连续动作并影响其他每个动作,在这些连续动作中,最小功力尽可能地是以一个常量近似值而分布。为了成功地解决这个组群问题,这位敲钟精灵必须视之为按时间计算的一个组群问题,或者我们会认为,这为敲钟精灵必须按定义有一个百分百的时间视角,这个时间视角按照我们的钟铃类比不仅意味着行动的有效执行,这些行动的频率与所涉及的功力成反比,而且意味着功力因时平均分配。
时间视角,是指这位敲钟精灵能够成功地掌握一个组群的问题并能对之作出恰当反应,这个概念很有意思,不仅是因为它允许将来客观地界定由各类精神病所导致的不平衡的时间视角,而且还因为它表明N×If=常量(近似值)这种关系对于言语流而言根本不是必要的,因为其他分配也极有可能。
也许理解百分百的时间视角的意义最简单方法就是勘察一些理论上可能的错误的时间视角案例,在这些案例中,所有功力就其本身而言尽管最小化了仍将平均分布,而且在这些案例中我们将不会发现在N与If之间存在一个反比例关系。一个错误的时间视角的案例是我们提到过的“最容易的最先”案例,该案例就像我们记得的那样仅仅表明了在不间断的连续时间内给每个最容易敲的钟铃敲击所指派的F/r次然后接着敲下一个最容易的钟铃。在此情况下,所有重复间隔都将是1,结果是在双对数坐标图上的分布斜率将会是零。因此,我们可以将这个“最容易的最先”案例描述为零时间视角的案例。
如此描述的时间视角无论是0.00还是1.00,所耗功力总量保持不变。区别在于功力的消耗比率。时间视角为1.00的功力消耗比率尽可能的是常量,然而时间视角是0.00时,敲钟精灵的功力比率逐渐增大,他越跑越快,直到在第F·Sn秒达到了最高速度,结果却在第F·Sn+1秒内再次急剧下降到最低速度。这个“最容易的最先”案例先天存在着循环的自动出现(这是我们前文讨论过的闭合的结果),其功力比率对于精神病学理论可能很有意义。
因此,出于精神病学目的,任何小于1.00的时间视角可以被认为,表明了一种躁郁症不平衡,其特征就是行动不正常地连续“起伏不定”。
现在转到时间视角可能大于1.00的那些假设例子,我们记得表2-4中乔伊斯《尤利西斯》样本的负斜率中位值接近1.20。如果为了更一般的阐述,我们忽略了该表中第Ⅵ栏中的误差,同样我们给每个间隔任意加上1页,那么我们可以说乔伊斯系统地倾向避免重复词语。也就是说,按照钟铃类比,《尤利西斯》中过去的动作(无论是钟铃的还是词语的)往往是被系统地视作远离当下而不是事实上可能是1.00时间视角的情况(即,比如昨日之事被视为前天发生的)。总之,《尤利西斯》中现在时刻似乎以过去时刻为代价成系统地独占且抢先占据了乔伊斯——这个说法对于乔伊斯“意识流”写作学派的学生们而言无可争辩。无论如何,假如我们将1.00定义为“正确的”,我们可能觉得乔伊斯的时间视角有点“不对劲”。
另一个假设的错误的时间视角例子是可以想象的,比如在此情况下曲线变得明显向上凹曲或向下凹曲,似乎这个组群的问题要么被各个击破要么成了其他更大问题的附属。但是我们不必停留在这些假定的案例中,因为出于我们当下目的我们仅仅有意根据我们的方程式Np×If=常量(近似值)来阐述时间视角的可能意义,我们此后将这个方程式命名为数量—间隔方程式。
表2-5
以上阐释的错误时间视角的情况表明,不同言语实例一方面可以根据这个数量—间隔方程式的标准来揭示各种变数,该方程式是指功力因时分配比率;另一方面,同样这些言语实例可以非常接近F·Sn这个调和方程式,该方程式毕竟是指“不管功力分配比率如何正在将功力最小化”这个事实。
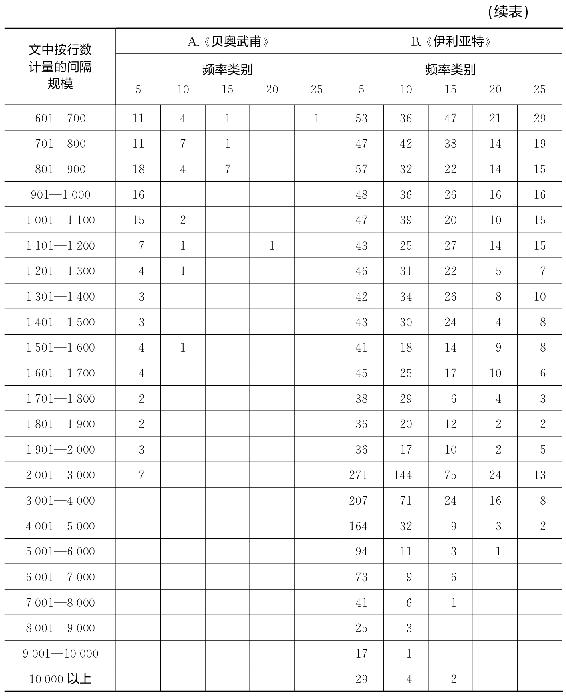
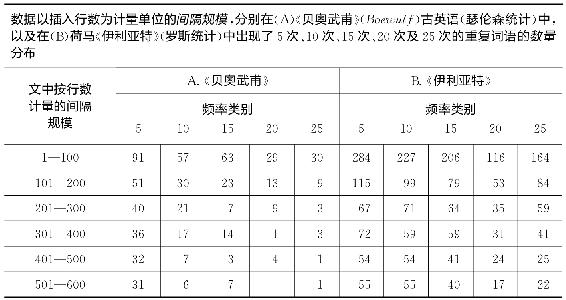
然而,为了不使读怀疑词语重复间隔的规模与数量之间通常存在一个基本的反比例关系,我们在表2-5中呈现了古英语史诗《贝奥武甫》(Boewulf)以及荷马《伊利亚特》中出现5次、10次、15次、20次及25次的词语数量—间隔关系。《贝奥武甫》的研究是由我以前的学生艾伦·索伦森(Allen Sorensen)先生特意使用克莱伯(Klaeber)版15《贝奥武甫》中词汇表作出的。《伊利亚特》的研究是由我以前的学生哈罗德·D.罗斯(Harold D.Rose)博士使用普伦德加斯特《主要词语索引》16(Concordance)作出的,该《伊利亚特》研究前文提到过。分析方法基本上就是弗勒博士研究《尤利西斯》所采用的方法。这两个研究中数据以插入行数计算,单元间隔为100行。我们从表2-5中大体看出,这两个古老文本虽然在时间、风格以及内容上远不同于乔伊斯《尤利西斯》,但是在间隔数量与规模上也存在着反比例关系。这几组点构成的图形(限于篇幅未在此呈现)没有形成一个非常令人满意的自始至终的直线性,尽管这些散布图没有偏爱任何间隔顺序。至于《伊利亚特》,我们记得在图2-3中也见到了词语数量—频率关系的显著直线性。至于《贝奥武甫》,我们将在下一章研究它的序列—频率分布[15]。
这些数据中没有哪一组有乔伊斯《尤利西斯》样本中呈现得那样广泛,也没有一组像《尤利西斯》那样呈明显的直线性。各种斜率偏差对于该研究中的个体作者或说话者的“人格”而言可能有什么意义,这个问题有待日后研究。同时,我们将继续坚信,那些广泛的《尤利西斯》数据,具有负斜率近似1的线性关系,足以证明我们探索建构钟铃类比的有效性。
现在回到这个钟铃类比,我们已经表明了这个钟铃类比与词语重复的数量—间隔方程式之间除了数学描述的相似性之外没有更深层关系。因此,我们无权单凭这个机械类比就归纳出重复词语的数量—间隔方程式确实代表了最小功力因时平均分配。
另一方面,不可否认,这个钟铃类比客观描述了词语分布的某些显著特征。借助这个类比以及在下一章对其完善,我们将更好地研究言语动力学而不会忽视这个事实即词语是一个活着的现象。
二、小结与内容概述
我们在本章已经完成两件事。
首先,为了表明言语流的条理性,我们已经呈现了言语流中词语出现频率的大量数据以及意义的大量数据。所观察到的具体条理性没有先验的必要性,而且具体所观察到的分布类型只不过是偶然的结果,而且接下来的章节中进一步确证的数据将更加减少这种偶然的可能性。
其次,我们已经尝试在经济的基础上合理分析我们的经验数据[16]。这种理性分析的尝试只是个开端,它并非出自这种看法即认为它只不过是初步的介绍。
理性分析的主要步骤在于钟铃类比,其中我们面对的不仅是将功力最小化的问题而且是最小化的功力因时分配的比率问题。最小化的功力因时分配这个问题是本研究主题的基础,因此它会在下一章引出“将平均功力消耗比率最小化”这个概念,然后接着引导出“将可能(平均)功力消耗比率最小化”这个概念,即根据定义即为最省力。
这个钟铃类比有意如此构建,即功力比率因时最小化并且尽可能每秒之间都没有变化。如此建构该类比,这样钟铃声的分布与言语流中词语的分布就会很相似。多亏这个钟铃类比的客观性,我们才能发现数量—间隔方程式是首要的调和级数方程式,前者是指重复间隔的频率与规模之间存在反比例关系,后者是本章一开始就谈到的。也就是说,后者可由前者推理出来,反之则不行。
那么,这就是我们本章论证的小结。
展望未来,我们要么在完善这个有点死板的钟铃类比的过程中继续进行理论上的合理分析,要么进一步呈现经验数据,要么两者都要进行,正如我们按照自然科学的方式在归纳与演绎之间更迭一样。
在接下来一章中,我们两者都要进行,即我们将进一步呈现一组组研究数据,并且尝试愈发精确地在理论上进行合理分析。不断借助这个归纳—演绎的分析方法,我们将从言者和听者的两个角度了解言语流中大小实体的形式与功能,而且我们将同时更多了解有关它们的基本组织原则,直到在第五章我们将得出一个观点,即整个言语现象大概都是受制于最省力原则。
[1]为了简化起见,我们将在本章使用术语最省力,用以指最少可能功力的情形以及只对直接行为所作的论述,从技术上看后者也是一种最省力。
[2]后来我们将词语的意义界定为由这个词语引起的一种反应2。
[3]这个词语也无需必说出来,该词语也可以写出来。在词语使用的内部经济方面,作者—读者的情况与言者—听者的情况类似,即使读者对作者而言不是立即在场的,而听者对言者来说却是立即在场的,即使书面言语的词语用法可能有点不同于口头言语的词语用法,其原因我们将在后一章探究。如果我们一开始讨论词语时不将书面言辞与口头言辞分成两类,我们不作对立区分是为了合理的简化,这样简化在我一开始分析词语及其用法时似乎就很合理,我们认为读者稍加思考便会同意这一点。
[4]我们将一直用黑体字表达(译注:英语原文中是用大写字母表达)统一化之力与多元化之力这两个术语,为了提醒我们自己这两种力量并不代表物理学家对力这个术语的传统理解。此外,我们的术语平衡将包括技术上所熟知的物理学家与经济学家所说的稳定状态与平衡。
[5]这个斜率很可能是最可靠的,因为它是指最高频率的10 000个词语,这些词语可见于100 000个连续词语的最优样本。有关最优样本的论述参见下文。
[6]表2-2栏Ⅱ中C的大小应该与表2-1中C的大小是相同的,即大约为26 000。两者之间的细微不同可归因于《尤利西斯》曲线顶部和底部的细微弯曲。
[7]我们记得f2与f2-1/4之间的差异只对于非常小的f值很重要。因此,当f甚至是4这么大时,f2与f2-1/4之间的差异仅为16与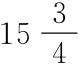 之间的差异,当f=10时,其差异只在100与
之间的差异,当f=10时,其差异只在100与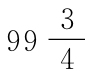 。
。
[8]由于普伦德加斯特没有给出《伊利亚特》中最高频率词语的频率,所以我们无法绘制它的序列—频率分布图。
[9]因为振动间歇呈现出T的倍数,该序列—频率分布成为直线性,曲线向上,第n个序列的频率等于T的倍数。言语流逐渐增长,情况也会同样如此,所以,找到一个优选长度或优选倍数的机会非常小。
[10]卡罗尔(J.B.Carrol)博士已经从理论和经验上研究了规模不同的样本中n个不同词语与优选规模的基本值Sn之间相同或不同的关系[《心理记录Ⅱ》(The Psychologocial Record,Ⅱ)(1938),第16期,第379—386页]。可是,关于这一点,主要取决于样本中的重复率。参见下文。
[11]如果是增加1/2页而不是1的话,统计起来可能更好一点。然而,在计算斜率与误差这个繁重任务时,如下文所示,保持y为整数而不是分数,可以用我的表格得出整数值,从而节省了大量工作。如果读者用1/2页顶替1页在下文讨论的斜率计算中,他将要给所有斜率大约增加0.2。因此,具体来说,下文表2-3中对出现15次的词语作描述的负斜率1.15(随机选择第5个分析)如果根据增加1/2页而不是1页来计算则将会增加到1.34。其他组数据也会同样如此。这个稍有不同的斜率并未改变我们的论证。
[12]我们按照普通做法在横坐标轴而不是纵坐标轴上测量N,我们有意决定如此处理是为了使图2-4中数据与以传统方式绘制的图2-5中数据保持一致。如果这两个坐标轴颠倒过来,这种关系也不会改变。
[13]就上列方程式中常量而言,表2-3的15个分析中各自常量的值是由第Ⅵ栏中Y-截距的逆对数来表明的,我们在第Ⅵ栏中发现了第Ⅱ栏中截距大小与频率大小之间存在一个不太起眼的相反关系。但是澄清这一点有待进一步定量调查研究的结果,特别是最高频率类别的定量调研结果。
[14]更具体地讲,我们认为走到钟铃及返回都需要功力(work),但是我们认为敲钟本身无需功力。
[15]我们将在下一章同时呈现美洲印第安语言努特卡语(Nootka)的线性序列—频率数据。我们现在提及这一点是因为尽管努特卡语数据只代表了10 000个连续词语,我们还是发现了就间隔词语数量而言有一个熟悉的数量—间隔方程式。因此,最频繁的词语在样本中出现了107次,在1—10、11—20、21—30、31—40、41—50这5类间隔词语中分别重复了31次、12次、15次、3次以及3次。出现10次的有17个不同词语,在同样5类间隔词语中分别重复了35次、14次、9次、5次和0次;还有只出现两次的词语有583个,在这5类间隔词语中分别重复了131次、39次、34次、20次和19次。该数据其余部分也差不多。因此,《尤利西斯》、《伊里亚特》或《贝奥武甫》在这一点上与美洲印第安努特卡语很相似17。
[16]我们经常观察到的双曲线分布类型表明了一个经济控制性因素,即使是像钟铃形状的曲线也表明某种普遍的理性分析。