
1、AI幻觉
由于语言模型是基于大量数据,通过一定算法以概率的模式生成的内容[9],目前避免不了输出不真实、不准确、不可预计的内容,比如输出错误的答案,编造虚拟的人物、事物,错误地省略某些信息,将真实和虚拟混合起来等[10]。
案例一:输出错误答案(2025年3月)

图1 DeepSeek遗漏了乌海市
询问关于我国有哪些带“海”字的城市,AI遗漏了内蒙古自治区的地级市乌海市(已加入联网搜索)。再次询问,结果依然相同。
尝试使用腾讯元宝中的DeepSeek询问:
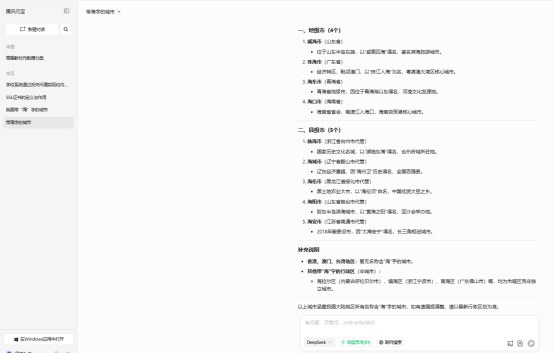
图2 腾讯元宝中的DeepSeek生成的第一次结果
结果列出的个数特别少,遗漏了几个城市,包括上海市,考虑到可能没添加“联网搜索”功能,于是加入该功能,再次询问:
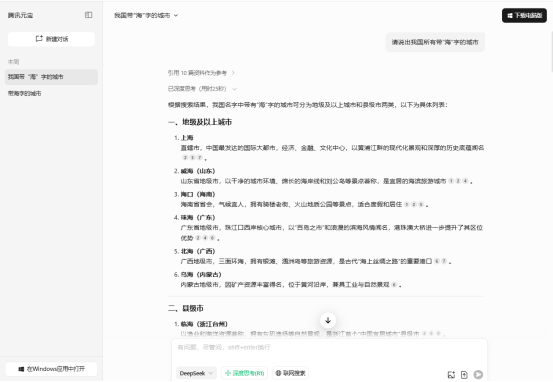
图3 腾讯元宝中的DeepSeek生成的第二次结果
再次询问后,AI显示“引用10篇资料作为参考”,结果中地级市增多,但是第一次结果中的青海省的海东市遗漏了,于是再次询问(此次未加入联网搜索):
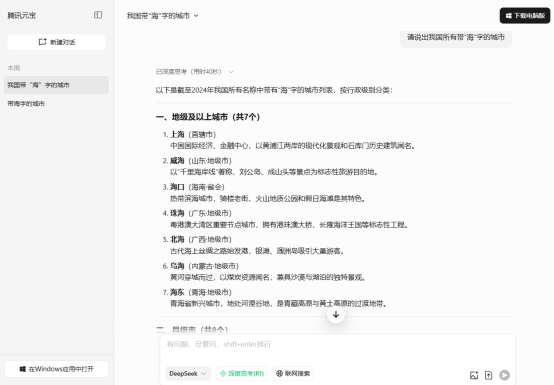
图4 腾讯元宝中的DeepSeek生成的第三次结果
本次结果中又加入了青海省的海东市。由于上次未加入“联网搜索”的功能,再次加入后搜索:
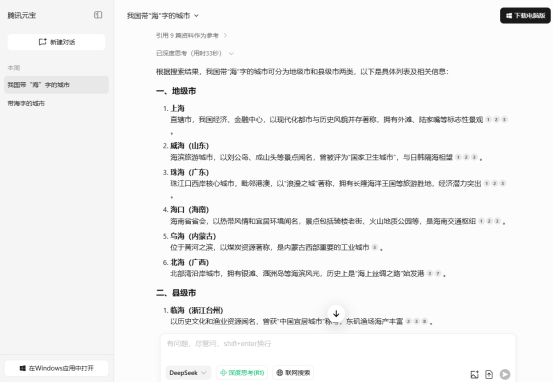
图5 腾讯元宝中的DeepSeek生成的第四次结果
再次询问后,AI显示“引用9篇资料作为参考”,结果又把青海省的海东市遗漏了,按理来说,加入“联网搜索”的功能后,AI的回答应该更加全面,但是相较上次未加入“联网搜索”的功能的询问,AI回答的地级市比之前更少,可见AI的回答有时不仅错误,而且是不可预计的。
案例二:编造虚拟的事物(ima.copilot中使用DeepSeek,2025年2月
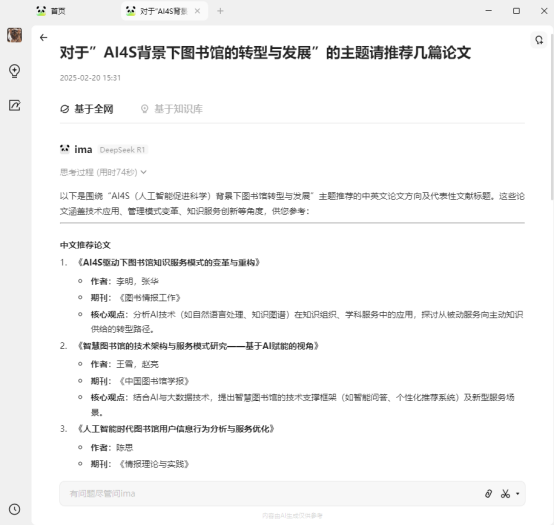
图6 AI推荐了虚拟论文
AI在基于全网的情况下推荐了几篇不存在的、虚拟的论文。换成DeepSeek官网,加上“联网搜索”功能后,生成结果真实性更高,但有些特殊的网站比如arxiv预印本网站、文库网站,比起正式期刊,这些网站上的期刊有更大的可能性改变,比如arxiv网站上,作者再上传论文后可能后期还会多次修改,比如修改论文题目,甚至撤回,此时AI生成的结果可能包含作者之前未修改的内容。
案例三:错误地省略某些信息(DeepSeek,2025年3月)
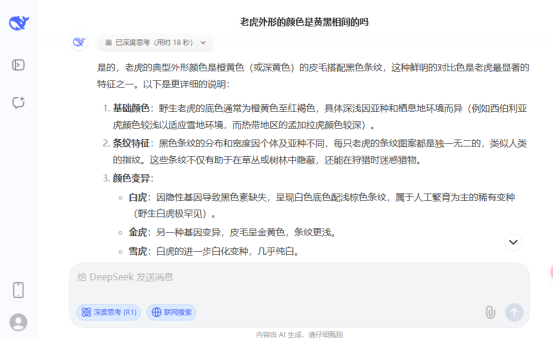
图7 AI关于老虎颜色的回答
AI忽略了所有老虎的外形其实都有白色,即使东北虎、孟加拉虎,在腹部、面部都有白色。
2、有偏见和过时
以下原因可能会导致AI生成的内容有偏见和过时:
模型公司无法获得的训练材料不包括在模型中,因此没有出现在输出中。
来自互联网的未经检查的材料被用作训练材料。
如果现实中通过新的研究发现某些内容不正确,但是AI可能还是会给出这些旧的内容,因为它在最新的训练数据中没有包括新信息。
用户反馈给 AI 的关于问题的正确、错误或倾向,会使AI在之后的使用中带来人类偏见。
案例四:AI生成的信息并不是最新的(DeepSeek,2025年3月):

图8 第一次询问 图9 第二次询问
关于“申公豹”是否为反派的提问,在图8中可以发现AI生成的内容并没有包括最新信息的,并没有关于影片“哪吒2”的信息,但在图9中开启联网搜索后,增加了“哪吒2”的影片信息后,输出的内容就更全面。
3、人工智能被审查
AI会被限制一些他们不会讨论的问题,因为它受到了运营它们的公司的限制。这些通常是有争议的话题,如如何编写恶意软件、举出仇恨言论的例子以及如何浓缩铀等,又或者研究者正在研究和讨论有争议的话题。对于这些话题,AI 由于采取了保护措施而不愿意进行帮助。

