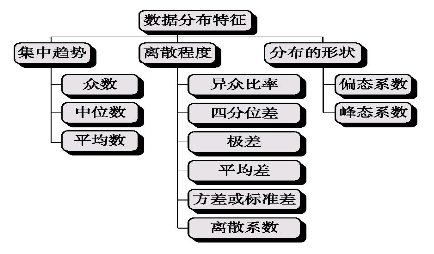
第4章 数据第概括性度量
一、学习目标
1、掌握集中趋势各测度值的计算方法。
2、掌握集中趋势各测度值的特点及应用场合。
3、掌握离散程度各测度值的计算方法。
4、掌握离散程度各测度值的特点及应用场合。
5、了解偏态与峰态的测度方法。
6、了解用Excel计算描述统计量并进行分析。
二、学习指南
1.知识点
集中趋势的度量;离散程度的度量;偏态与峰态的度量;相对位置的度量
2.重点与难点
重点是每种数据集中趋势的各个测度值的含义、计算方法;离散程度的各个测度值的含义、计算方法;偏态与峰态的含义;标准分数的计算公式。
难点是中位数和四分位数的计算;加权平均数的计算;众数、中位数和平均数的关系;方差的公式;标准分数;离散系数等。
三、知识内容
知识点一:集中趋势的度量
一组数据向其中心值靠拢的倾向和程度, 测度集中趋势就是寻找数据水平的代表值或中心值, 不同类型的数据用不同的集中趋势测度值
低层次数据的测度值适用于高层次的测量数据,但高层次数据的测度值并不适用于低层次的测量数据, 测度值的选用取决于所掌握的数据的类型。
(一)分类数据:众数
一组数据中出现次数最多的变量值:M0,不受极端值的影响,可能没有众数或有几个众数,主要用于分类数据,也可用于顺序数据和数值型数据。
例题分析:
某城市居民关注广告类型的频数分布 |
广告类型 | 人数
(人) | 比例 | 频率(%) |
商品广告
服务广告
金融广告
房地产广告
招生招聘广告
其他广告 | 112
51
9
16
10
2 | 0.560
0.255
0.045
0.080
0.050
0.010 | 56.0
25.5
4.5
8.0
5.0
1.0 |
合计 | 200 | 1 | 100 |
解:这里的变量为“广告类型”,这是个分类变量,不同类型的广告就是变量值在所调查的200人当中,关注商品广告的人数最多,为112人,占总被调查人数的56%,因此众数为“商品广告”这一类别,即
Mo=商品广告
(二)顺序数据:中位数
一组数据排序后处于中间位置上的变量值,不受极端值的影响,主要用于顺序数据,也可用数值型数据,但不能用于分类数据。
未分组资料中位数的计算
基本步骤:
1.)先进行排队 ;
2.)确定中数的位置:(n+1)/2
3.)中间位置上的那个标志值即为中位数。
顺序数据的中位数(例题分析)
甲城市家庭对住房状况评价的频数分布 |
回答类别 | 甲城市 |
户数 (户) | 累计频数 |
非常不满意
不满意
一般
满意
非常满意 | 24
108
93
45
30 | 24
132
225
270
300 |
合计 | 300 | — |
解:中位数的位置为: 300+1/2=150.5
从累计频数看,中位数在“一般”这一组别中。因此
Me=一般
对于未分组的原始资料,首先必须将标志值按大小排序。设排序的结果为:
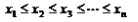
则中位数就可以按下面的方式确定:
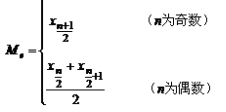
(三)顺序数据:四分位数
排序后处于25%和75%位置上的值,不受极端值的影响, 主要用于顺序数据,也可用于数值型数据,但不能用于分类数据。
末分组资料四分位数的计算
基本步骤:
1.)先进行排队 ;
2.)确定中数的位置:(n+1)/4和 3(n+1)/4
3.)在(n+1)/4和 3(n+1)/4位置的变量值,即为四分位数。
例题分析:
甲城市家庭对住房状况评价的频数分布 |
回答类别 | 甲城市 |
户数 (户) | 累计频数 |
非常不满意
不满意
一般
满意
非常满意 | 24
108
93
45
30 | 24
132
225
270
300 |
合计 | 300 | — |
解:QL位置= (300+1)/4 =75
QU位置 =3×(300+1)/4=225
从累计频数看, QL在“不满意”这一组别中; QU在“一般”这一组别中。因此
QL = 不满意
QU = 一般
【例】:9个家庭的人均月收入数据
原始数据: 1500 750 780 1080 850 960 2000 1250 1630
排 序: 750 780 850 960 1080 1250 1500 1630 2000
位 置: 1 2 3 4 5 6 7 8 9
解:
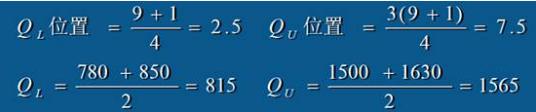
(四)数值型数据:平均数
一组数据相加后除以数据个数而得到的结果,一组数据的均衡点所在,体现了数据的必然性特征,易受极端值的影响,用于数值型数据,不能用于分类数据和顺序数据。
简单算术平均数:
计算公式:
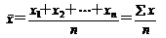
例: 据南方人才服务中心调查,从事IT行业的从业人员年薪在40000-55000元之间,表 1的数据是IT从业人员年薪的一个样本:
表 1 24名IT从业人员年薪资料表
49100
49300
48700 | 48600
51200
50300 | 49950
51000
49000 | 48800
49400
49800 | 47200
51400
48900 | 49900
51800
48650 | 51350
49600
51300 | 54600
53400
51900 |
计算IT从业人员的平均年薪。
根据公式计算如下:
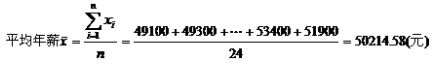
加权算术平均数:
计算公式:
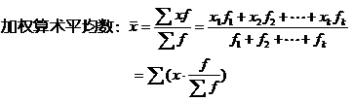
例: 计算人均日产量。计算表见下表。
按零件数分组 | 组中值x | 频数f | xf |
105~110
110~115
115~120
120~125
125~130
130~135
135~140 | 107.5
112.5
117.5
122.5
127.5
132.5
137.5 | 3
5
8
14
10
6
4 | 322.5
562.5
940.0
1715.0
1275.0
795.0
550.0 |
合? 计 | –– | 50 | 6160.0 |
解:平均日产量=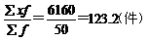
几何平均数:直接将n项变量连乘,然后对其连乘积开n次方根所得的平均数即为简单几何平均数。
计算公式为:
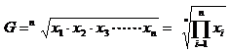
式中:G代表几何平均数,![]() 代表连乘符号
代表连乘符号
例5 某流水生产线有前后衔接的五道工序。某日各工序产品的合格率分别为95%、92%、90%、85%、80%,整个流水生产线产品的平均合格率为:
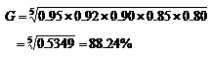
(五)众数、中位数和均值的特点和应用
1.众数、中位数和算术平均数的关系
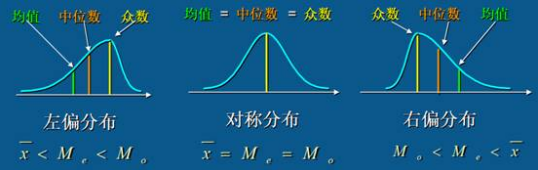
算术平均数、众数和中位数之间的关系与次数分布数列有关。在次数分布完全对称时,算术平均数、众数和中位数都是同一数值;在次数分布非对称时,算术平均数、众数和中位数不再是同一数值了,而具有相对固定的关系。在尾巴拖在右边的正偏态(或右偏态)分布中,众数最小,中位数适中,算术平均数最大;在尾巴拖在左边的负偏态(或左偏态)分布中,众数最大,中位数适中,算术平均数最小。
2.特点和应用
(1)众数
不受极端值影响
具有不唯一性,作为分类数据集中趋势的测度值
数据分布偏斜程度较大时应用
(2)中位数
不受极端值影响,作为顺序数据集中趋势的测度值
数据分布偏斜程度较大时应用
(2)平均数
易受极端值影响
数学性质优良,作为数值型数据集中趋势的测度值
数据对称分布或接近对称分布时应用
知识点二:离散程度的度量
反映各变量值远离其中心值的程度(离散程度),从另一个侧面说明了集中趋势测度值的代表程度,不同类型的数据有不同的离散程度测度值。
(一)分类数据:异众比率
异众比率是分布数列中非众数组的频数与总频数之比,通常用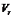 来表示,即:
来表示,即:
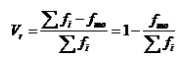
其中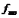 为众数组的频数。
为众数组的频数。
通常与众数相结合,用以表明众数代表性的高低。
例题分析:
某城市居民关注广告类型的频数分布 |
广告类型 | 人数(人) | 频率(%) |
商品广告
服务广告
金融广告
房地产广告
招生招聘广告
其他广告 | 112
51
9
16
10
2 | 56.0
25.5
4.5
8.0
5.0
1.0 |
合计 | 200 | 100 |
解: =200-112/200=44%
在所调查的200人当中,关注非商品广告的人数占44%,异众比率还是比较大。因此,用“商品广告”来反映城市居民对广告关注的一般趋势,其代表性不是很好。
(二)顺序数据:四分位差
也称为内距或四分间距,上四分位数与下四分位数之差,反映了中间50%数据的离散程度,不受极端值的影响,用于衡量中位数的代表性。
四分位差是四分位数中第一个四分位数与第三个四分位数之差,通常用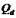 表示,即:
表示,即:
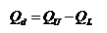
通常与中位数相结合,用以表明变量分布中间50%数值的离散程度,
例题:根据例3.6的计算结果,计算家庭人均月收入的四分位差。
解:
QL = 815
QU= 1565
四分位差:
QD = QU - QL= 1565 – 815= 750
(三)数值型数据:极差
一组数据的最大值与最小值之差,离散程度的最简单测度值,易受极端值影响,未考虑数据的分布,计算公式为:R = max(xi) - min(xi)
例: 有两个学习小组的统计学开始成绩分别为:
第一组:60,70,80,90,100
第二组:78,79,80,81,82
很明显,两个小组的考试成绩平均分都是80分,但是哪一组的分数比较集中呢?
如果用极差指标来衡量,则有
R甲=100-60=40(分)
R乙=82-78=4(分)
这说明第一组资料的标志变动度或离中趋势远大于第二组资料的标志变动度。
(四)数值型数据:平均差
各变量值与其均值离差绝对值的平均数,能全面反映一组数据的离散程度,数学性质较差,实际中应用较少。
平均差的计算:
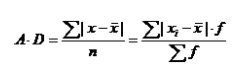
优点:利用了全部数据信息,能比较客观反映变量分布的离散程度。
不足:取了绝对值,因而数学处理不是很方便,数学性质也不是最优,应用上受到了一些限制。
仍以甲组学生数学成绩为例,计算平均差如下:
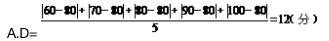
(五)数值型数据:方差和标准差
方差和标准差是测度数据变异程度的最重要、最常用的指标。方差是各个数据与其算术平均数的离差平方的平均数,通常以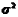 表示。方差的计量单位和量纲不便于从经济意义上进行解释,所以实际统计工作中多用方差的算术平方根–––标准差来测度统计数据的差异程度。标准差又称均方差,一般用σ表示。方差和标准差的计算也分为简单平均法和加权平均法,另外,对于总体数据和样本数据,公式略有不同。
表示。方差的计量单位和量纲不便于从经济意义上进行解释,所以实际统计工作中多用方差的算术平方根–––标准差来测度统计数据的差异程度。标准差又称均方差,一般用σ表示。方差和标准差的计算也分为简单平均法和加权平均法,另外,对于总体数据和样本数据,公式略有不同。
1.总体方差和标准差
设总体方差为,对于未经分组整理的原始数据,方差的计算公式为:
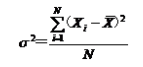
对于分组数据,方差的计算公式为:
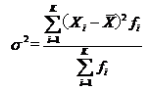
方差的平方根即为标准差,其相应的计算公式为:
未分组数据: 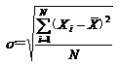
分组数据: 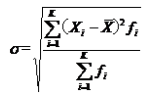
2.样本方差和标准差
样本方差与总体方差在计算上的区别是:总体方差是用数据个数或总频数去除离差平方和,而样本方差则是用样本数据个数或总频数减1去除离差平方和,其中样本数据个数减1即n-1称为自由度。设样本方差为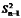 ,根据未分组数据和分组数据计算样本方差的公式分别为:
,根据未分组数据和分组数据计算样本方差的公式分别为:
样本方差:未分组数据: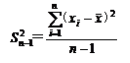 分组数据:
分组数据: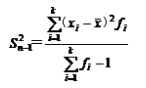
样本标准差:未分组数据: 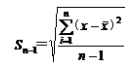 分组数据:
分组数据: 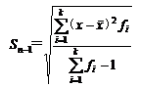
例: 考察一台机器的生产能力,利用抽样程序来检验生产出来的产品质量,假设搜集的数据如下:
3.43
| 3.45 | 3.43 | 3.48 | 3.52 | 3.50 | 3.39 |
?3.48 | 3.41 | 3.38 | 3.49 | 3.45 | 3.51 | 3.50 |
根据该行业通用法则:如果一个样本中的14个数据项的方差大于0.005,则该机器必须关闭待修。问此时的机器是否必须关闭?
解:根据已知数据,计算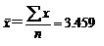
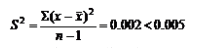
因此,该机器工作正常。
方差和标准差也是根据全部数据计算的,它反映了每个数据与其均值相比平均相差的数值,因此它能准确地反映出数据的离散程度。方差和标准差是实际中应用最广泛的离散程度测度值。
(六)相对离散程度:离散系数
上面介绍的各离散程度测度值都是反映数据分散程度的绝对值,其数值的大小一方面取决于原变量值本身水平高低的影响,也就是与变量的均值大小有关。变量值绝对水平越高,离散程度的测度值自然也就越大,绝对水平越低,离散程度的测度值自然也就越小;另一方面,它们与原变量值的计量单位相同,采用不同计量单位计量的变量值,其离散程度的测度值也就不同。因此,对于平均水平不同或计量单位不同的不同组别的变量值,是不能直接用上述离散程度的测度值直接进行比较的。为了消除变量值水平高低和计量单位不同对离散程度测度值的影响,需要计算离散系数。
离散系数通常是就标准差来计算的,因此,也称为标准差系数,它是一组数据的标准差与其相应的均值之比,是测度数据离散程度的相对指标,其计算公式为:
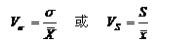
离散系数要是用于对不同组别数据的离散程度进行比较,离散系数大的说明该组数据的离散程度也就大,离散系数小的说明该组数据的离散程度也就小。
例: 某管理局抽查了所属的8家企业,其产品销售数据如表5–10所示。试比较产品销售额与销售利润的离散程度。
表 某管理局所属8家企业的产品销售数据
企业编号 | 产品销售额(万元)X1 | 销售利润(万元)X2 |
1
2
3
4
5
6
7
8 | 170
220
390
430
480
650
950
1000 | 8.1
12.5
18.0
22.0
26.5
40.0
64.0
69.0 |
解:由于销售额与利润额的数据水平不同,不能直接用标准差进行比较,需要计算离散系数。由表中数据计算得

计算结果表明,V1<V2,说明产品销售额的离散程度小于销售利润的离散程度。
知识点三:偏态与峰态的度量
变量分布的形状要用形状指标来反映。形状指标就是反映变量分布具体形状,即左右是否对称、偏斜程度与陡峭程度如何的指标。
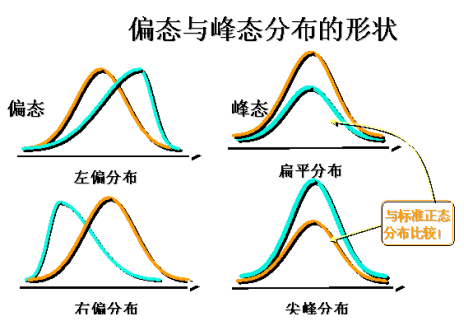
偏态的度量:偏态系数
反映变量分布偏斜程度的指标,偏度指变量分布偏斜的方向及其程度
偏度系数的计算方法:
1、根据原始数据计算
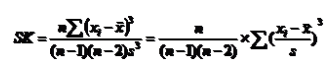
2、根据分组数据计算
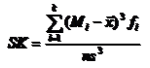
偏态系数性质:
偏态系数=0为对称分布
偏态系数> 0为右偏分布
偏态系数< 0为左偏分布
若1<偏态系数或偏态系数< -1,则为高度偏态分布
若0.5<偏态系数<1或-1<偏态系数< -0.5之间则为中等偏态分布
例题:计算偏态系数
按销售量份组(台) | 组中值(Mi) | 频数 fi |
140—150
150—160
160—170
170—180
180—190
190—200
200—210
210—220
220—230
230—240 | 145
155
165
175
185
195
205
215
225
235 | 4
9
16
27
20
17
10
8
4
5 |
合计 | — | 120 |
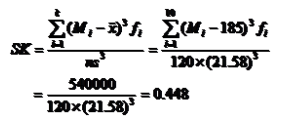
结论:偏态系数为正值,但与0的差异不大,说明电脑销售量为轻微右偏分布,即销售量较少的天数占据多数,而销售量较多的天数则占少数
峰态的度量:峰态系数
峰度通常是指钟型分布的顶峰与标准正态分布相比偏扁平或偏尖陡的程度。分为三种情况:标准正态峰度、尖顶峰度和平顶峰度。
峰度系数的计算
1、根据原始数据计算
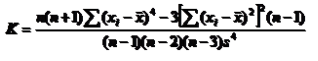
2、根据分组数据计算
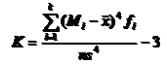
峰态系数性质:
峰态系数=0扁平峰度适中
峰态系数<0为扁平分布
峰态系数>0为尖峰分布
例题:计算峰态系数
按销售量份组(台) | 组中值(Mi) | 频数 fi |
140—150
150—160
160—170
170—180
180—190
190—200
200—210
210—220
220—230
230—240 | 145
155
165
175
185
195
205
215
225
235 | 4
9
16
27
20
17
10
8
4
5 |
合计 | — | 120 |
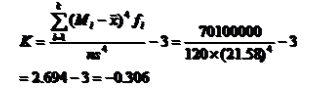
结论:偏态系数为负值,但与0的差异不大,说明电脑销售量为轻微扁平分布。
知识点四:相对位置度量
相对位置度量的指标是标准分数,也称标准化值,对某一个值在一组数据中相对位置的度量,变量值与其平均数的离差除以标准差后的值, 可用于判断一组数据是否有离群点,用于对变量的标准化处理。
计算公式: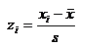
z分数只是将原始数据进行了线性变换,它并没有改变一个数据在该组数据中的位置,也没有改变该组数据分布的形状,而只是将该组数据变为均值为0,标准差为1。
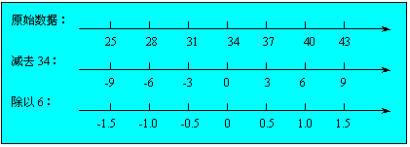
例题分析:
9个家庭人均月收入标准化值计算表 |
家庭编号 | 人均月收入(元) | 标准化值 z |
1
2
3
4
5
6
7
8
9 | 1500
750
780
1080
850
960
2000
1250
1630 | 0.695
-1.042
-0.973
-0.278
-0.811
-0.556
1.853
0.116
0.996 |
经验法则表明:当一组数据对称分布时
约有68%的数据在平均数加减1个标准差的范围之内
约有95%的数据在平均数加减2个标准差的范围之内
约有99%的数据在平均数加减3个标准差的范围之内
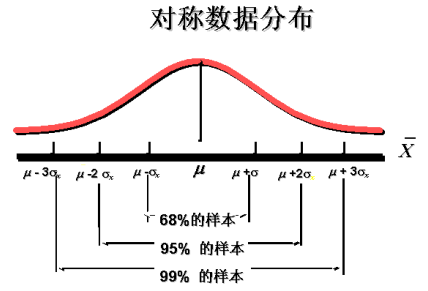
*离群点:在平均数加减3个标准差之外的数。
切比雪夫不等式
如果一组数据不是对称分布,经验法则就不再使用,这时可使用切比雪夫不等式,它对任何分布形状的数据都适用
对于任意分布形态的数据,根据切比雪夫不等式,至少有(1-1/k2)的数据落在均值加减k个标准差之内。其中k是大于1的任意值,但不一定是整数
对于k=2,3,4,该不等式的含义是
至少有75%的数据落在平均数加减2个标准差的范围之内
至少有89%的数据落在平均数加减3个标准差的范围之内
至少有94%的数据落在平均数加减4个标准差的范围之内