时间序列分析与预测
一、学习目标
1. 了解时间序列的概念、种类和构成要素
2. 掌握时间序列图形描述和增长率分析方法
3. 了解时间序列预测程序
4. 掌握平稳序列的移动平均法
5. 掌握平稳序列的指数平滑预测方法
6. 掌握趋势型序列的预测方法
7. 理解复合型序列的分解预测
二、知识指南
知识点
1. 时间序列分解
2. 时间序列的描述性分析
3. 时间序列预测的程序
4. 平稳序列-移动平均法
5. 平稳序列-指数平滑法
6. 线性趋势预测
7. 复合型序列的分解预测
重点:
1. 时间序列的分解
2. 增长速度的计算方法;
3. 平稳序列的预测方法;
4. 复合型序列分解预测
5. 测定季节指数的方法
难点:
1.能够结合具体的实例,计算时间序列的序时平均数及增长速度;
2.直线趋势的分析和预测方法的灵活运用;复合型序列分解预测。
三、主要内容
知识点一: 时间序列分解
一、时间序列的构成要素
1.定义:同一现象在不同时间上的相继观察值排列而成的数列。
2.特点:
形式上由现象所属的时间和现象在不同时间上的观察值两部分组成;
排列的时间可以是年份、季度、月份或其他任何时间形式;
3.分类:
(1)平稳序列(stationary series)
基本上不存在趋势的序列,各观察值基本上在某个固定的水平上波动;
或虽有波动,但并不存在某种规律,而其波动可以看成是随机的;
(2)非平稳序列 (non-stationary series)
有趋势的序列:线性的
有趋势、季节性和周期性的复合型序列
4.构成要素
(1)趋势(trend)
呈现出某种持续向上或持续下降的状态或规律
(2)季节性(seasonality)也称季节变动(Seasonal fluctuation)
时间序列在一年内重复出现的周期性波动
(3)周期性(cyclity)也称循环波动(Cyclical fluctuation)
围绕长期趋势的一种波浪形或振荡式变动
(4)随机性(random)也称不规则波动(Irregular variations)
除去趋势、周期性和季节性之后的偶然性波动
二、时间序列的分解方法
1.构成要素:时间序列的构成要素分为四种,即趋势(T)、季节性或季节变动(S)、周期性或循环波动(C)、随机性或不规则波动(I)非平稳序列。
2.分解模型
乘法模型
Yi=Ti×Si×Ci×Ii
加法模型
Yi=Ti+Si+Ci+Ii
其中最常用的是乘法模型。乘法模型的基本假设是,四个因素是由不同的原因形成的,但相互之间存在一定的关系,它们对事物的影响是相互的,因此时间序列中各观察值表现为各种因素的乘积。利用乘法模型可以将四个因素很容易地从时间序列中分离出来,因而乘法模型在时间序列分析中被广泛应用。本节及以后各节介绍的时间序列构成分析方法,也均以乘法模型为例。
知识点二:时间序列的描述性分析
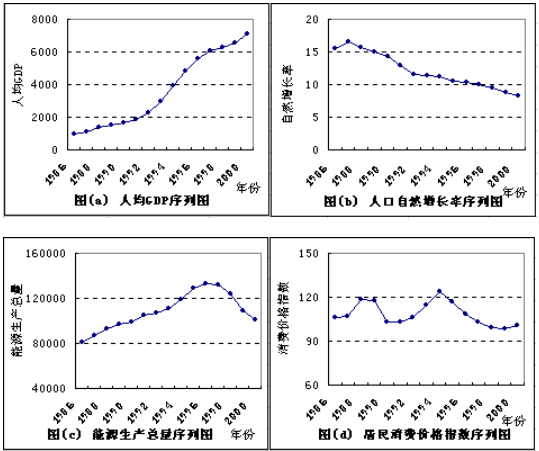
一、图形描述
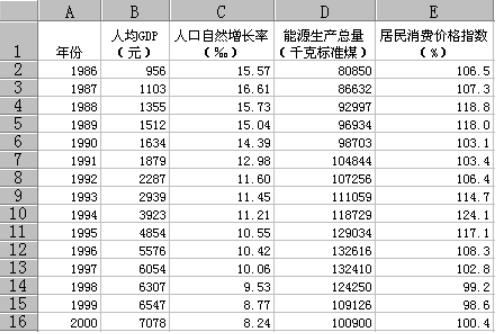
例题分析,资料如下表
二、水平分析
(一) 发展水平
1.概念:社会经济现象在各时间上的观测值,称为发展水平。
2.根据研究的着眼点,可将发展水平分为基期水平和报告期水平。
报告期水平是所要研究的时间的发展水平。
基期水平是用来作对比基准的时间的发展水平。
着眼点在哪个时间,那个时间的数值便为报告期水平,基期水平可能是某一固定基期水平,也可能是着眼点的前一期水平。
(二)平均发展水平
1.概念:也称序时平均数或动态平均数,是对时间数列中不同时间上的发展水平计算的平均数。
2.序时平均数

三、时间数列的增长量和平均增长量
(一)增长量
1.概念:时间数列中计算的差值称作增长量,它说明时间数列在一定时间内增减的绝对数量。它是报告期水平减去基期水平的差数。即:
增长量 = 报告期水平 — 基期水平
2.种类:由于选用基期的不同,增长量又分为逐期增长量和累计增长量。
逐期增长量 = 报告期水平 - 前一期水平
累计增长量 = 报告期水平 - 固定基期水平
两种增长量之间的关系是:累计增长量等于相应各个逐期增长量之和。即
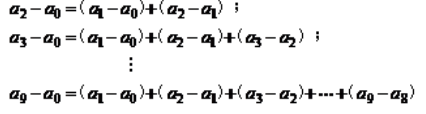
(二)平均增长量
平均增长量是时间数列中逐期增长量的序时平均数,它表明现象在一定期间内平均每期增加(减少)的数量。计算公式为:

式中![]() 表示分子中求和的逐期增长量的个数。
表示分子中求和的逐期增长量的个数。
根据逐期增长量和累计增长量之间的关系,平均增长量还可以用下式计算:

式中“时间数列的项数”指包括最初水平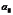 在内的项数,即
在内的项数,即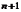 项。
项。
四、增长率分析
(一)发展速度
发展速度是两个不同时期发展水平的比值,表明报告期水平已经发展到基期水平的百分之几或若干倍。
计算公式为: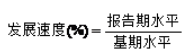
在时间数列中,由于采用的基期不同,发展速度可以分为环比发展速度和定基发展速度。
1.环比发展速度
环比发展速度是报告期水平与前一期水平之比。说明现象在相邻两个时间上发展变化的程度。即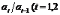 ,…,
,…,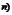 ,其中
,其中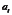 表示各时间上的现象观测值,
表示各时间上的现象观测值, 表示时间数列中除去最初项之外的项数。
表示时间数列中除去最初项之外的项数。
2.定基发展速度
定基发展速度是报告期水平与固定基期水平之比。说明现象相对于固定基期水平在一定时期内总的发展变化程度。即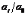 ?(
?(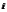 =1,2,…,,其中
=1,2,…,,其中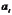 表示各时间上的现象观测值,表示固定基期水平,表示时间数列中除去最初项之外的项数。
表示各时间上的现象观测值,表示固定基期水平,表示时间数列中除去最初项之外的项数。
两者之间的关系为:
第一,定基发展速度等于相应时期内环比发展速度的连乘积。
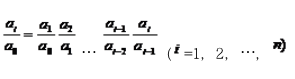
第二,两个相邻时期的定基发展速度之比等于相应时期的环比发展速度。
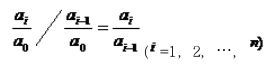
实际工作中,经常利用上述关系式对发展速度指标进行推算或换算。
(二)增长速度
1.概念:增长速度也称增长率,是增长量与基期水平之比,用于描述现象的相对增长程度。它可以根据增长量求得,也可以根据发展速度求得。
2.计算公式为:

3.种类:当式中的发展速度是环比发展速度时,相应的增长速度叫环比增长速度;
当式中的发展速度是定基发展速度时,相应的增长速度叫定基增长速度。
环比增长速度与定基增长速度之间不存在如发展速度那样环比的连乘等于定基的关系。
(三)应用速度指标时应注意的问题
1.当时间序列中的观察值出现0或负数时,不宜计算增长率。
例如:假定某企业连续五年的利润额分别为5、2、0、-3、2万元,对这一序列计算增长率,要么不符合数学公理,要么无法解释其实际意义。在这种情况下,适宜直接用绝对数进行分析;
2.在有些情况下,不能单纯就增长率论增长率,要注意增长率与绝对水平的结合分析。我们用增长1%的绝对值来反映速度与绝对水平之间的结合

(四)平均发展速度和平均增长速度
1.种类:平均速度可分为平均发展速度和平均增长速度。二者的关系是:平均增长速度=平均发展速度-1
2.计算方法:有水平法平均发展速度和累计法平均发展速度两种。相应地,平均增长速度也有这样两种
第一个计算公式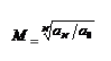 第二个计算公式
第二个计算公式 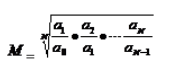
知识点三 : 时间序列预测的程序
一、确定时间序列的成分
1.确定趋势成分
确定趋势成分是否存在,可以从绘制时间序列的线图入手,观察线图后,就可以看出时间序列中是否存在趋势,以及所存在的趋势是线性的还是非线性的。
判断趋势成分是否存在的另一种方法是利用回归分析拟合一条趋势线,然后对回归系数进行显著性检验。如果回归系数显著,就可以得出线性趋势显著的结论。
2.确定季节成分
确定季节成分是否存在,至少需要两年的数据,而且数据需要按季度、月份、周或天等来记录。确定季节成分也可以从绘制时间序列的线图入手,但这里需要一种特殊的时间序列图,即年度折叠时间序列图。绘制该图时,需要将每年的数据分开画在图上,也就是横轴只有一年的长度,每年的数据分别对应纵轴。如果时间序列只存在季节成分,年度折叠时间序列图中的折线将会有交叉;如果时间序列既含有季节成分又含有趋势,那么年度折叠图时间序列图中的折线将不会有交叉,而且如果趋势是上升的,后面年度的折线将会高于前面年度的折线,如果趋势是下降的,后面年度的折线将低于前面年度的折线。
二、选择预测方法
在确定了时间序列的类型后,预测程序的第2步就是选择适当的预测方法。利用时间序列数据进行预测时,通常假定过去的变化趋势会延续到未来,这样就可以根据过去已有的形态或模式进行预测。时间序列的预测方法既有传统方法,如简单平均法、移动平均法、指数平滑法等,也有较为精确的现代方法,如Box-Jenkins的自回归模型(ARMA)。
一般来说,任何时间序列中都会有不规则成分存在,而商务与管理数据中通常不考虑周期性,所以只剩下趋势成分和季节成分。这里介绍的预测方法主要是针对平稳序列、含有趋势成分或季节成分的时间序列。
不含趋势和季节成分的时间序列,即平稳时间序列,由于这类数列只含随机成分,只要通过平滑就可以消除随机波动,因此,这类预测方法也称为平滑预测方法。对于只含有趋势成分的时间序列,可以利用趋势预测方法。对于既含有趋势又含有季节成分的时间序列,则采用季节性预测方法,这些方法对于既含有季节成分也含有随机成分的时间序列同样适用。
三、预测方法的评估
在选择了某一种特定的方法进行预测时,需要评价该方法的预测效果或准确性。评价的方法就是找出预测值与实际值的差距,这个差值就是预测误差。最优的预测方法也就是预测误差达到最小的方法。预测误差的计算方法有几种,包括平均误差、平均绝对误差、均方误差、平均百分比误差和平均绝对百分比误差等。选择哪种方法取决于预测者的目标、对方法的熟悉程度等。
1.平均误差
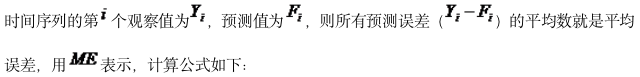
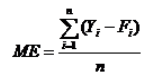
运用平均误差进行预测精度的测量在有些情况下是不恰当的。因为各项预测值和实际值之间的离差可能有正有负,当这种情况出现的时候,平均误差就有可能出现正值与负值相互抵消的情况,造成平均误差有偏低的倾向,最终产生预测精度较高的假象。因此,用平均误差来测定预测精度只适合于预测值与实际值的离差无负值的情况。
2.平均绝对误差
平均绝对误差是将预测误差绝对值后计算的平均误差,用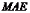 表示,其计算公式为:
表示,其计算公式为:
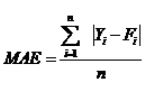
相对于平均误差,用平均绝对误差计算预测精度更准确,因为平均绝对误差对各项测量值与实际值之间的离差进行了绝对值化,不会再出现正负相互抵消的情况。
3.均方误差
均方误差是通过平方消去误差的正负号后计算的平均误差,用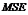 表示,其计算公式为:
表示,其计算公式为:
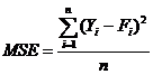
均方误差用将测量值与实际值之间的离差平方化的方法,避免了正负相抵从而造成的误差偏低的情况,更能够真实反映误差的实际水平。但同平均绝对误差相比较而言,均方误差指标的数值会更大一些。
4.平均百分比误差
平均百分比误差是对误差的一种相对度量值,消除了时间序列数据的水平和计量单位的影响,用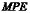 表示,其计算公式为:
表示,其计算公式为:
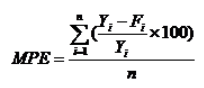
5.平均绝对百分比误差
平均绝对百分比误差同平均百分比误差相比,消除了由于预测误差的数值正负号求和的结果将会相互抵消所带来的影响,用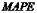 表示,其计算公式为:
表示,其计算公式为:
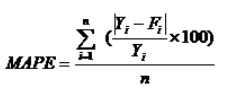
上面介绍的预测误差的计算方法中哪种最优,还没有一致的看法。本章采用均方误差来评价预测方法的优劣。
四、利用最佳预测方法进行预测
知识点四: 平稳序列-移动平均法
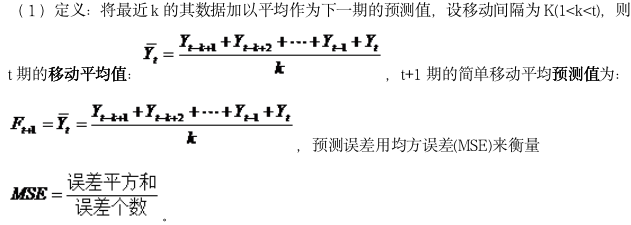
1.定义:对简单平均法的一种改进方法,通过对时间序列逐期递移求得一系列平均数作为趋势值或预测值。
2.分类:简单移动平均法和加权移动平均法(不介绍)。
3.简单移动平均:
(2)特点:
将每个观察值都给予相同的权数;
只使用最近期的数据,在每次计算移动平均值时,移动的间隔都为k;
主要适合对较为平稳的时间序列进行预测;
应用时,关键是确定合理的移动间隔长;
对于同一个时间序列,采用不同的移动步长预测的准确性是不同的;
选择移动步长时,可通过试验的办法,选择一个使均方误差达到最小的移动步长。
例:已知某商场1988~2008年的年销售额如下表所示,试运用简单移动平均法预测预测2009年该商场的年销售额。
解:采用Excel进行移动平均时,在【数据分析】选项中选择【移动平均】,并在对话框中输入数据区域和移动间隔即可。输出结果如表所示。各年销售量的走势及预测值如图所示。
从中我们可以看到,3期移动平均的预测值为106千万元,而5期移动平均的预测值为106.2千万元。到底我们应该选择哪一个移动间隔呢?这里我们比较两种预测方法的均方误差,3期移动平均的均方误差为347/18=19.28,5期移动平均的均方误差为347.6/16=21.725。我们发现3期的均方误差小于5期的均方误差,所以移动步长选择3期,2009年的销售额为106千万元。
表 简单移动平均法预测表
年份
| 销售额
(千万) | 3期移动平均预测 | 预测误差 | 误差平方 | 5期移动平均预测 | 预测误差 | 误差平方 |
1998 | 98 |
|
|
|
|
|
|
1999 | 97 |
|
|
|
|
|
|
1990 | 100 |
|
|
|
|
|
|
1991 | 101 | 98.3 | 2.7 | 7.11 |
|
|
|
1992 | 96 | 99.3 | -3.3 | 11.1 |
|
|
|
1993 | 104 | 99.0 | 5.0 | 25 | 98.4 | 5.6 | 31.36 |
1994 | 103 | 100.3 | 2.7 | 7.11 | 99.6 | 3.4 | 11.56 |
1995 | 102 | 101.0 | 1.0 | 1 | 100.8 | 1.2 | 1.44 |
1996 | 106 | 103.0 | 3.0 | 9 | 101.2 | 4.8 | 23.04 |
1997 | 107 | 103.7 | 3.3 | 11.1 | 102.2 | 4.8 | 23.04 |
1998 | 102 | 105.0 | -3.0 | 9 | 104.4 | -2.4 | 5.76 |
1999 | 98 | 105.0 | -7.0 | 49 | 104 | -6 | 36 |
2000 | 96 | 102.3 | -6.3 | 40.1 | 103 | -7 | 49 |
2001 | 101 | 98.7 | 2.3 | 5.44 | 101.8 | -0.8 | 0.64 |
2002 | 105 | 98.3 | 6.7 | 44.4 | 100.8 | 4.2 | 17.64 |
2003 | 104 | 100.7 | 3.3 | 11.1 | 100.4 | 3.6 | 12.96 |
2004 | 103 | 103.3 | -0.3 | 0.11 | 100.8 | 2.2 | 4.84 |
2005 | 110 | 104.0 | 6.0 | 36 | 101.8 | 8.2 | 67.24 |
2006 | 103 | 105.7 | -2.7 | 7.11 | 104.6 | -1.6 | 2.56 |
2007 | 112 | 105.3 | 6.7 | 44.4 | 105 | 7 | 49 |
2008 | 103 | 108.3 | -5.3 | 28.4 | 106.4 | -3.4 | 11.56 |
2009 |
| 106.0 |
|
| 106.2 |
|
|
合计 |
|
|
| 347 |
|
| 347.6 |
知识点五: 平稳序列-指数平滑法
1.定义:是加权平均的一种特殊形式,对过去的观察值加权平均进行预测的一种方法。 观察值时间越远,其权数也跟着呈现指数的下降,因而称为指数平滑。
指数平滑法是生产预测中常用的一种方法,也用于中短期经济发展趋势预测。所有预测方法中,指数平滑是用得最多的一种。简单全期平均法是对时间序列的过去数据一个不漏地全部加以同等利用;移动平均法则不考虑较远期的数据,并在加权移动平均法中给予近期资料更大的权重;而指数平滑法则兼容了全期平均和移动平均所长,不舍弃过去的数据,但是仅给予逐渐减弱的影响程度,即随着数据的远离,赋予逐渐收敛为零的权数。
也就是说指数平滑法是一种特殊的加权移动平均法,是在移动平均法基础上发展起来的一种时间序列分析预测方法,它是通过计算指数平滑值,配合一定的时间序列预测模型对现象的未来进行预测。其原理是任一期的指数平滑值都是本期实际观察值与前一期指数平滑值的加权平均。
2.分类:有一次指数平滑、二次指数平滑、三次指数平滑等。
3.特点:一次指数平滑法也可用于对时间序列进行修匀,以消除随机波动,找出序列的变化趋势。
4.一次指数平滑法
(1)定义:只有一个平滑系数,观察值离预测时期越久远,权数变得越小。
(2)预测模型: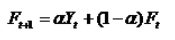
Yt为t期的实际观察值
Ft 为t期的预测值
a为平滑系数 (0 <a<1)
(3)计算过程:
在开始计算时,没有第1个时期的预测值F1,通常可以设F1等于1期的实际观察值,即F1=Y1;
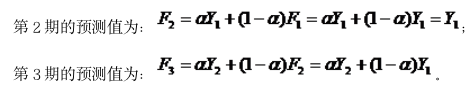
(4)预测误差:
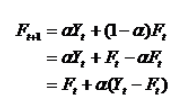
Ft+1是t期的预测值Ft加上用a调整的t期的预测误差(Yt-Ft);
(5)a的确定
知识点六: 线性趋势预测
线性趋势(linear trend)是指现象随着时间的推移而呈现出稳定增长或下降的线性变化规律。通常我们进行线性预测的时候,首先,要判定我们所研究的现象是否呈现的是线性的变化规律,如果该现象的散点图围绕一条隐蔽的直线上下波动或者该现象时间序列各逐期增长量大体相同或相似,我们就可以认定该现象呈现的是线性的变化规律。然后就可以选择线性趋势的预测模型进行预测。
线性趋势的预测模型可以表示为:

例1 某企业2001年至2007年某产品的销售量如下表所示,试用最小平方法配合直线趋势方程,并预测2008年的销售量。
表1 某企业某种产品销售量统计表
年 份 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 |
销售量(万件) | 12.4 | 13.8 | 15.7 | 17.6 | 19.0 | 20.8 | 22.7 |
解:先建立最小平方法计算表(见表2)

表2 最小平方法计算表
年份 | 序号 ![]() | 销售量![]() | ![]()
| ![]()
| ![]()
|
2001 | 1 | 12.4 | 1 | 12.4 | 12.27 |
2002 | 2 | 13.8 | 4 | 27.6 | 13.99 |
2003 | 3 | 15.7 | 9 | 47.1 | 15.71 |
2004 | 4 | 17.6 | 16 | 70.4 | 17.43 |
2005 | 5 | 19.0 | 25 | 95.0 | 19.15 |
2006 | 6 | 20.8 | 36 | 124.8 | 20.87 |
2007 | 7 | 22.7 | 49 | 158.9 | 22.59 |
合计 | 28 | 122.0 | 140 | 536.2 | 122.01 |
· 
知识点七: 复合型序列的分解预测
一、确定并分离季节成分
1.计算季节指数
季节指数(seasonal index)刻画了序列在一个年度内各月份或季度的典型季节特征。在乘法模型中,季节指数是以其平均数等于100%为条件而构成的,它反映了某一月份或季度的数值占全年平均数值的大小。
季节指数的计算方法有多种,这里只介绍移动平均趋势剔除法。该方法的基本步骤是:
(1)计算移动平均值(如果是季度数据采用4项移动平均,月份数据则采用12项移动平均),并将其进行中心化处理,也就是将移动平均的结果再进行一次2项移动平均,即得出中心化移动平均值(CMA)。
(2)计算移动平均的比值,也称为季节比率,即将序列的各观察值除以相应的中心化移动平均值,然后再计算出各比值的季度(或月份)平均值。
(3)季节指数调整。由于各季节指数的平均数应等于1或100%。若根据第2步计算的季节比率的平均值不等于1,则需要进行调整。具体的方法是:将第2步计算的每个季节比率的平均值除以他们的总平均值。
下面通过实际例子说明季节指数的计算过程。
表1 某企业某商品销售量及四项移动平均计算表
年份 | 季别 | 销售量
(千件)Y | 四季移动平均
(千件) |
| 中心化移动均值
(CMA) | 比值
(Y/CMA) |
1994 | 1
2
3
4 | 5
7
13
18 | —
10.75
10.75
11.00
11.25
11.25
11.50
12.00
12.50
13.50
14.00
14.50
15.25
16.00
17.75
19.00
19.25
20.00
— |
| —
—
10.750
10.875 | —
—
120.93
165.52 |
1995 | 1
2
3
4 | 5
8
14
18 |
| 11.125
11.250
11.375
11.750 | 44.94
71.11
123.08
153.19 |
1996 | 1
2
3
4 | 6
10
16
22 |
| 12.250
13.000
13.750
14.250 | 48.98
76.92
116.36
154.39 |
1997 | 1
2
3
4 | 8
12
19
25 |
| 14.875
15.625
16.875
18.375 | 53.78
76.80
112.59
136.05 |
1998 | 1
2
3
4 | 15
17
20
28 |
| 19.125
19.625
—
— | 78.43
86.62
—
— |
将表1中的Y/T重新加以排列得表2。
将表2中每年同季的数值加以平均,所得相对数即是季节比率。各季季节比率的合计数为404.92,大于400,因此,需要调整,调整系数为0.98785(400÷404.92),用这个系数分别以各季的季节比率,得调整后的季节比率。
表2 季节比率计算表 单位:%
| 第一
季度 | 第二
季度 | 第三
季度 | 第四
季度 | 合计 |
1994 | — | — | 1.2093 | 1.6552 | — |
1995 | 0.4494 | 0.7111 | 1.2308 | 1.5319 | — |
1996 | 0.4898 | 0.7692 | 1.1636 | 1.5439 | — |
1997 | 0.5378 | 0.7680 | 1.1259 | 1.3605 | — |
1998 | 0.7843 | 0.8662 | — | — | — |
合计 | 2.2613 | 3.1145 | 4.7296 | 6.0915 | — |
季节比率 | 0.5653 | 0.7786 | 1.1824 | 1.5229 | 4.0492 |
调整后的
季节比率 | 0.5584 | 0.7792 | 1.1680 | 1.5044 | 4 |
2.分离季节性成分
计算出季节指数后,就可将实际观察值分别除以相应的季节指数,将季节性成分从时间序列中分离出去。用公式表示即为: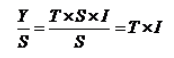
结果即为季节成分分离后的序列,见表3中的第5列,它反映了在没有季节因素影响下时间序列的变化形态。
二、建立预测模型并进行预测
从剔除季节成分后的商品销售量的时间序列(表3第5列)可以看出,商品销售量具有明显的线性趋势。因此,用一元线性模型来预测各季度的商品销售量。
首先建立预测模型: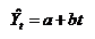
然后利用上例中的数据,采用最小二乘的方法拟合数据可以得到估计的回归方程为
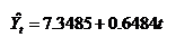
根据该方程进行预测,可以得到各期的预测值见表3第6列。
表3 1994—1998年各季度商品销售量的预测值
年/季 | 时间
编号 | 销售量
(千件)Y | 季节指数(S) | 季节分离后
的序列(Y/S) | 回归趋势值 | 最终预测值 | 预测误差 |
(1) | (2) | (3) | (4) | (5)=(3)/(4) | (6) | (7)=(6)×(4) | (8)=(3)-(7) |
1994/1
2
3
4 | 1
2
3
4 | 5
7
13
18 | 0.5584
0.7792
1.1680
1.5044 | 8.9542
8.9836
11.1301
11.9649 | 7.9969
8.6453
9.2937
9.9421 | 4.4655
6.7364
10.8550
14.9569 | 0.5345
0.2636
2.1450
3.0431 |
1995/1
2
3
4 | 5
6
7
8 | 5
8
14
18 | 0.5584
0.7792
1.1680
1.5044 | 8.9542
10.2669
11.9863
11.9649 | 10.5905
11.2389
11.8873
12.5357 | 5.9137
8.7574
13.8844
18.8587 | -0.9137
-0.7574
0.1156
-0.8587 |
1996/1
2
3
4 | 9
10
11
12 | 6
10
16
22 | 0.5584
0.7792
1.1680
1.5044 | 10.7450
12.8337
13.6986
14.6238 | 13.1841
13.8325
14.4809
15.1293 | 7.3620
10.7783
16.9137
22.7605 | -1.3620
-0.7783
-0.9137
-0.7605 |
1997/1
2
3
4 | 13
14
15
16 | 8
12
19
25 | 0.5584
0.7792
1.1680
1.5044 | 14.3266
15.4004
16.2671
16.6179 | 15.7777
16.4261
17.0745
17.7229 | 8.8103
12.7992
19.9430
26.6623 | -0.8103
-0.7992
-0.9430
-1.6623 |
1998/1
2
3
4 | 17
18
19
20 | 15
17
20
28 | 0.5584
0.7792
1.1680
1.5044 | 26.8625
21.8172
17.1233
18.6121 | 18.3713
19.0197
19.6681
20.3165 | 10.2585
14.8202
22.9723
30.5641 | 4.7415
2.1798
-2.9723
-2.5641 |
三、 计算最后的预测值

这个预测值是不含季节性因素的,也就是说,如果没有季节因素的影响,商品销售量的预测值为20.9649千件。如果要求出含有季节性因素的销售量的最终预测值,则需要将上面的预测值乘以第一季度的季节指数,结果为11.7068千件(20.9649×0.5584)。1999年各季度啤酒销售量的预测值如表4所示。
表4 1999年各季度商品销售量的预测值
年/季 | 时间编号 | 季节指数(S) | 回归预测值 | 最终预测值 |
1999/1
2
3
4 | 21
22
23
24 | 0.5584
0.7792
1.1680
1.5044 | 20.9649
21.6133
22.2617
22.9101 | 11.7068
16.8411
26.0017
34.4660 |
误差均方来衡量预测误差的大小
确定a时,可选择几个进行预测,然后找出预测误差最小的作为最后的值
不同的a会对预测结果产生不同的影响;
一般而言,当时间序列有较大的随机波动时,宜选较大的a ,以便能很快跟上近期的变化;
当时间序列比较平稳时,宜选较小的a;
选择a时,还应考虑预测误差。