
10.3 Spark 基本概念
上一节
下一节
Spark是一个快速的企业级大规模数据处理引擎,可以运行在Hadoop的集群管理器中,并且可以与Hadoop进行相互操作。 Spark是由Scala语言编写的,是在JVM中运行。并且能够让应用程序在处理过程中能够可靠地在内存中分发数据,从根本上避免低效率的磁盘访问,并以内存速度进行计算。
通过Scala,Python等交互式语言,开发在Spark上运行的程序较为容易,并且需要的代码量比Java大幅减少。
Spark提供了一系列的库,包括用于交互式的Spark SQL 和DataFrame,用于机器学习的MLib、用于实时分析的Spark Streaming。
但是需要注意的是,与Hadoop提供了用于存储的HDFS和用于计算的MR。Spark不提供任何特定的存储介质。Spark就是一个计算引擎,可以把数据存储在内存里进行处理。
Spark具有从存储在HDFS或Hadoop API支持的其他存储系统(包括本地文件系统,亚马逊S3, Hive 等)中的任何文件创建分布式数据集的能力。
最重要的是,Spark不需要Hadoop来运行它。 但是Spark可以运行基于Hadoop文件系统的数据。
Spark由4个架构组件:Spark SQL, Spark Streaming, SparkMLlib, Spark GraphX构成。
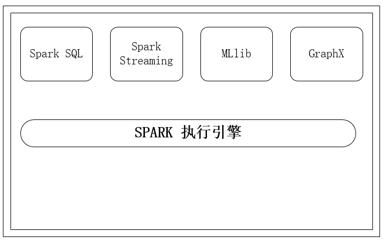
Spark组件是一个统一的技术架构,为使用者提供了一个在程序中整合了SQL,流和机器学习的强大功能。这种统一性的有点如下:
无需在系统之间对数据进行复制或ETL处理
把多种处理类型组合到一个程序中
代码复用
只需学习一套系统
只需维护一套系统

