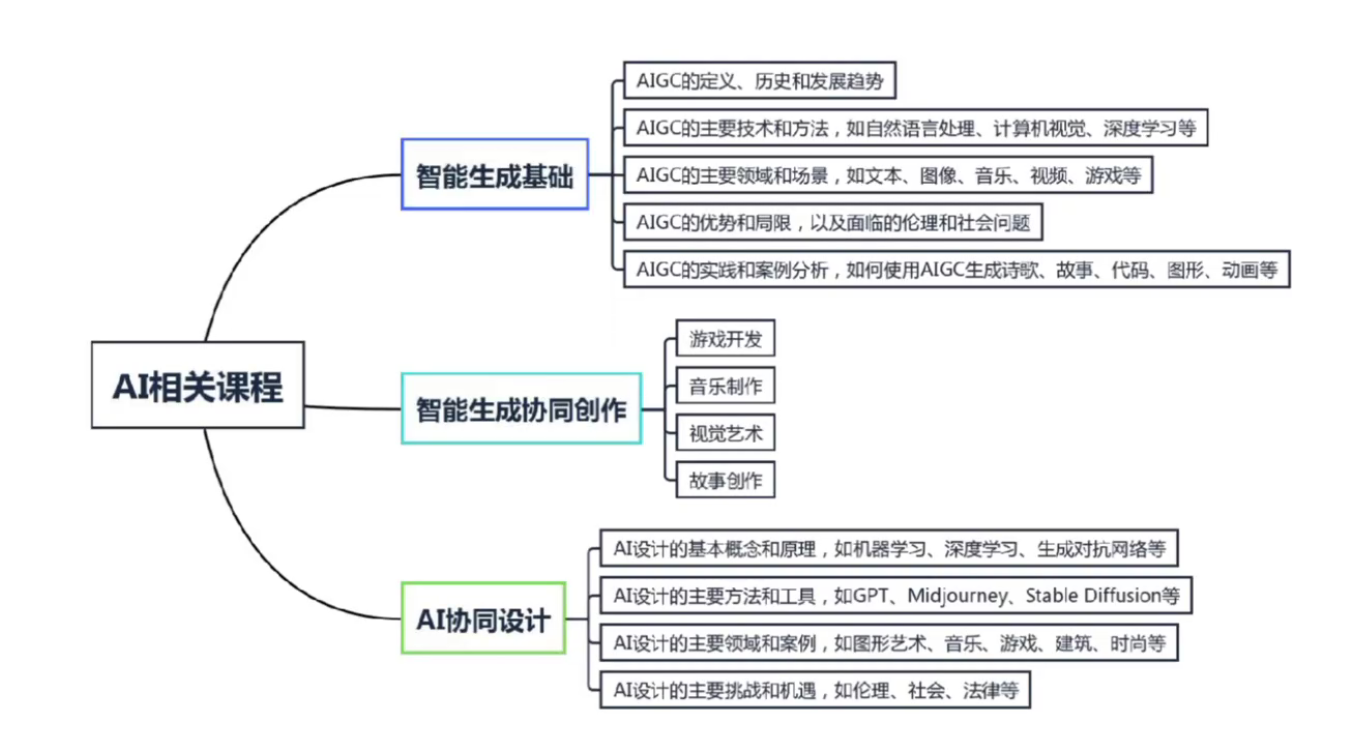
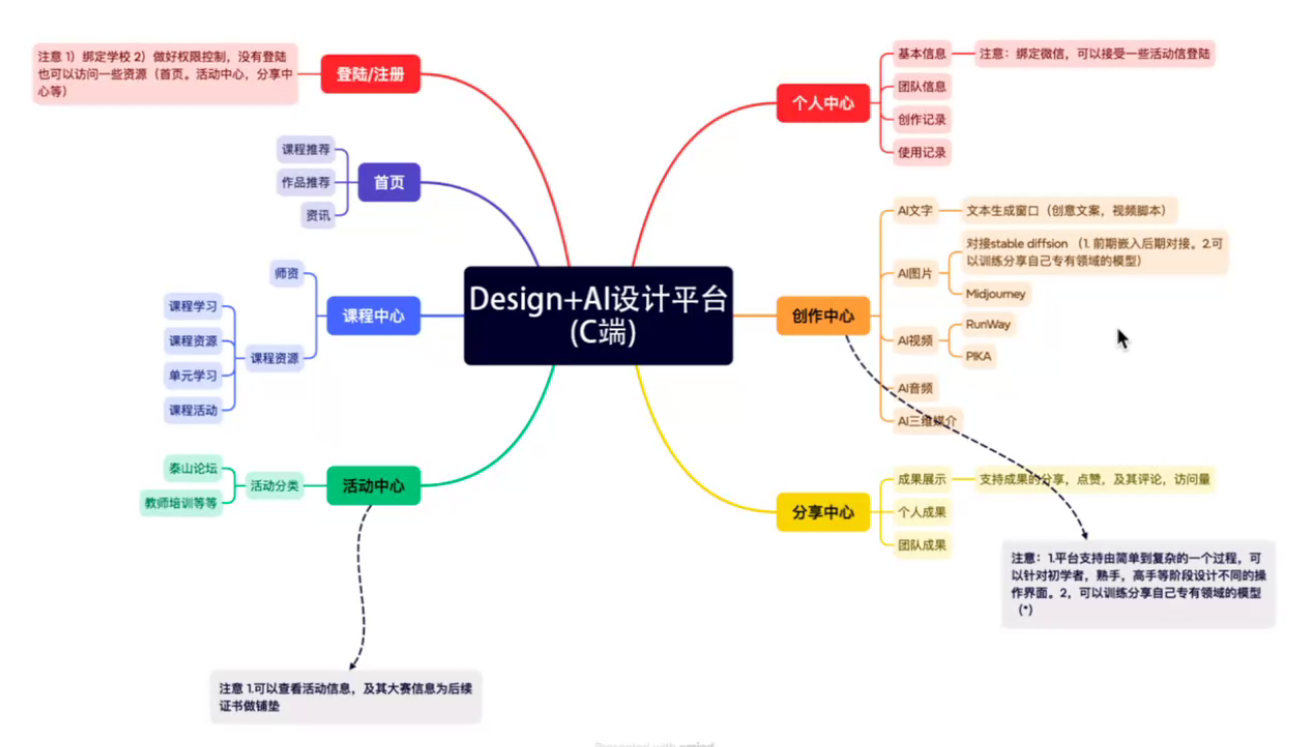
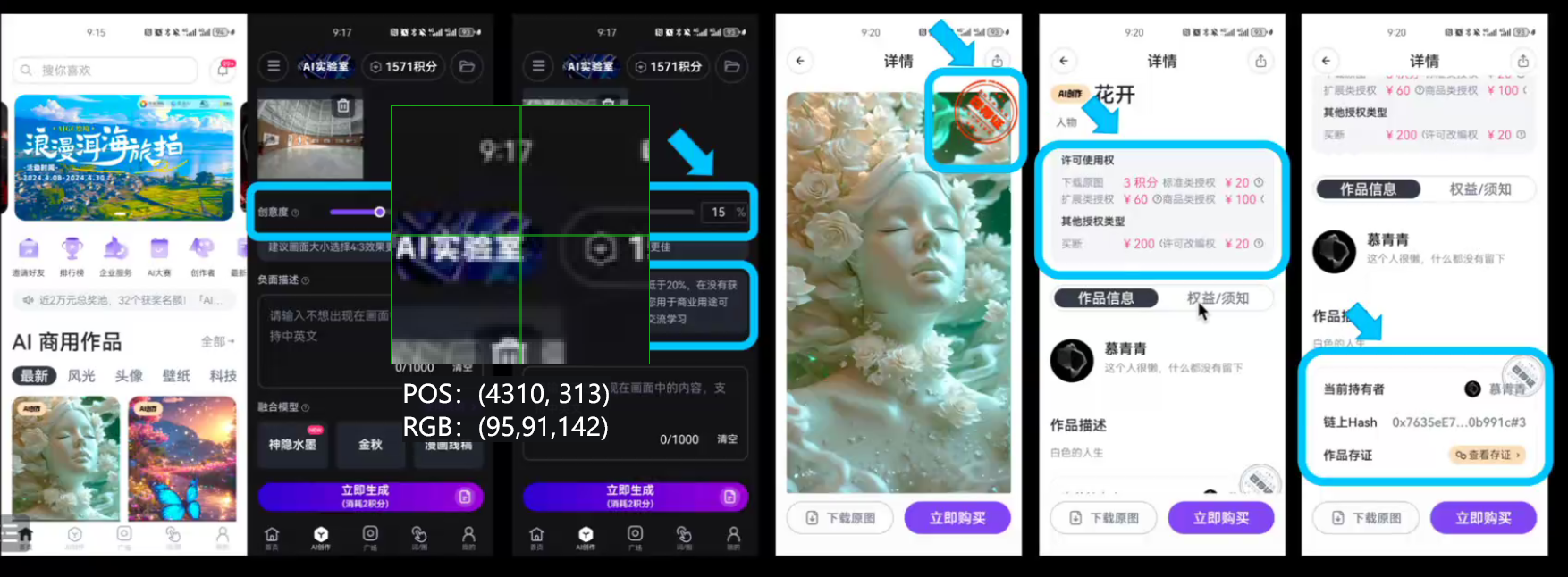
-
1 理论基础
-
2 实践应用
-
3 思考拓展
知识链接:
基础认知:

AIGC生成式动画的方法:
AIGC(生成式人工智能)生成式动画的方法涵盖了多种技术和算法,这些技术主要利用深度学习模型,特别是生成模型和扩散模型,来创建具有连续性和动态效果的动画内容。以下是一些主要的AIGC生成式动画的方法:
1. 文本到视频(Text-to-Video, T2V)
核心思路:
输入:文本描述(如故事情节、角色动作等)。
输出:生成与文本描述相符的视频片段。
代表模型:
CogVideo:基于两阶段的Transformer架构,先生成视频帧,再进行帧间插值,实现高质量的视频生成。
IMAGEN VIDEO:由Google开发,基于Imagen模型的时序扩展,用于生成视频内容。
Text2Video-Zero:基于图像扩散模型,引入跨帧注意力机制进行时序建模,并通过显著性检测实现背景平滑。
2. 图像到视频(Image-to-Video)
核心思路:
输入:静态图像(或图像序列)及可能的控制条件(如姿态、动作描述等)。
输出:根据输入图像生成的视频片段。
代表模型:
AnimateDiff:基于图像扩散模型,训练一个运动建模模块来学习运动信息,从而生成视频。该模型可以在保持原有图像生成模型参数不变的情况下,通过优化运动建模模块来生成动画。
VideoCrafter1:由腾讯AI Lab开发,基于扩散模型,采用空间和时序注意力操作来实现高质量视频生成。
Stable Video Diffusion:由Stability AI开发,在Stable Diffusion模型的基础上增加时序层,用于视频生成。
3. 视频编辑与风格化
核心思路:
输入:已有的视频片段及可能的控制条件(如风格、特效等)。
输出:经过编辑或风格化处理的视频内容。
技术方法:
视频编辑:使用深度学习模型对视频进行裁剪、拼接、添加特效等操作。
视频风格化:通过深度学习模型改变视频的风格,如将视频转换为卡通风格、油画风格等。
4. 角色动画与动态化
核心思路:
输入:角色图像、姿态信息或动作描述。
输出:生成角色动画或动态图像。
技术方法:
逆向运动学(IK):用于求解关节参数,使角色模型从一种姿态平滑过渡到另一种姿态。
物理约束与动作生成:引入物理定律和约束条件,生成符合现实规律的动画动作。
蒙皮动画:通过骨骼驱动模型表面的网格,实现角色模型的动态效果。
5. 扩散模型与视频生成
核心思路:
利用扩散模型(Diffusion Models)的潜力,在图像和视频领域进行扩展,实现视频内容的生成。
具体实现:
通过在扩散模型的架构中引入时间层,并结合大规模视频数据集进行训练,生成具有时间连续性的视频。
使用条件采样技术,根据输入文本、图像或视频片段生成对应的视频内容。
结论
AIGC生成式动画的方法多种多样,涵盖了从文本到视频、图像到视频、视频编辑与风格化、角色动画与动态化等多个方面。这些方法的共同点是利用深度学习模型,特别是生成模型和扩散模型,来捕捉和生成视频内容的连续性和动态效果。随着技术的不断发展,AIGC生成式动画的质量和效率将不断提升,为创意产业和数字媒体领域带来更多可能性。