暂无搜索结果
-
1 绪论
-
1.1 机器学习发展历程
-
1.2 深度学习的发展历史
-
1.3 特征表示与表示学习
-
1.4 深度学习主流框架
-
1.5 多模态数据读取实验
-
2 全连接神经网络
-
2.1 线性模型与感知机
-
2.2 前馈神经网络
-
2.3 反向传播算法
-
2.4 深度宽度模型W&D
-
2.5 MLP-Mixer
-
2.6 慢病发病风险预警建模
-
3 卷积神经网络
-
3.1 卷积神经网络原理
-
3.2 经典的卷积神经网络模型
-
3.3 医学影像诊断
-
3.4 医学目标检测
-
3.5 医学图像分割
-
3.6 医学文本处理
-
4 循环神经网络
-
4.1 循环神经网络原理
-
4.2 LSTM & GRU
-
4.3 医学文本处理
-
4.4 多变量回归问题建模
-
5 注意力机制与Transformer
-
5.1 注意力机制原理
-
5.2 注意力机制分类
-
5.3 自注意力机制
-
5.4 Transformer及应用
-
5.5 ViT模型及应用
-
6 图神经网络
-
6.1 图数据概述
-
6.2 无监督图表示学习
-
6.3 图神经网络原理
-
6.4 蛋白质分子性质预测
-
7 自监督学习与度量学习
-
7.1 Siamese网络架构
-
7.2 自监督对比学习
-
7.3 有监督对比学习
-
7.4 对比学习应用-CV
-
7.5 对比学习应用-NLP
-
7.6 对比学习应用-Graph
-
7.7 多模态对比学习-CLIP
-
7.8 自监督重建MAE
-
8 深度生成模型
-
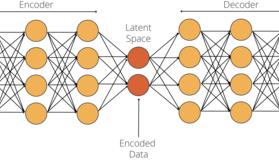
8.1 变分自动编码器VAE原理
-
8.2 生成对抗网络GAN原理
-
8.3 Diffusion模型原理
-
8.4 可控生成方法
-
8.5 医学数据增强
-
8.6 跨模态数据生成
-
9 深度强化学习
-
9.1 多臂赌博机问题
-
9.2 马尔科夫决策过程
-
9.3 Q-learning
-
9.4 策略梯度
-
9.5 演员-批判家方法
-
9.6 强化学习求解最短路径
-
10 深度迁移学习
-
10.1 迁移学习概述
-
10.2 Fine-Tune范式
-
10.3 BERT 原理
-
10.4 GPT原理
-
10.5 LLM大模型的微调
-
10.5.1 低秩微调LORA
-
10.5.2 适配器微调Adapter
-
10.5.3 P-tuning微调
-
10.5.4 混合专家模型MoE
-
10.6 基于对抗学习的迁移
-
10.7 多中心医学数据处理
-
11 概率图模型
-
11.1 贝叶斯定理
-
11.2 朴素贝叶斯模型
-
11.3 贝叶斯网络
-
11.4 临床数据建模
-
12 模型蒸馏技术
-
12.1 移动计算问题
-
12.2 模型蒸馏技术
-
12.3 互相学习
-
13 联邦学习
-
13.1 横向联邦学习模式
-
13.2 纵向联邦学习模式
-
13.3 联邦迁移学习
-
13.4 主要模型方法
-
13.5 非独立同分布问题
-
14 元学习
-
14.1 元学习范式
-
14.2 基于度量的学习
-
14.3 基于参数初始化
-
14.4 双层规划
-
14.5 MAML and Reptile
-
15 深度学习模型解释
-
15.1 可解释性综述
-
15.2 可视化解释CAM
-
15.3 事后解释post-hoc
-
15.4 Shapley值解释
-
15.5 局部代理解释LIME
-
15.6 反事实解释
-
16 终身学习与持续学习
-
16.1 终身学习
-
16.2 灾难性遗忘
-
16.3 持续学习
-
17 课程实验说明
-
17.1 实验指导书
-
17.2 实验报告模板
-
17.3 实验参考代码
-
17.4 实验参考数据
-
17.5 实验案例描述

选择班级