
9.10 The Normal Distribution
The normal distribution, also known as a Gaussian distribution, is a very important distribution in statistics (we will see why below). It is known for its iconic bell shape.
Random Samples
We can sample from the normal distribution using the rnorm() function. It takes three arguments:
n: how many data points we want to samplemean: the population (theoretic) meansd: the population (theoretic) standard deviation
rnorm(n = 5, mean = 5, sd = 2)
## [1] 4.564656 7.496730 6.937214 5.514461 5.985538
There is a special normal distribution called the standard normal which is simply a normal distribution with mean 0 and standard deviation 1. These are the default values of norm functions, so we can sample from the standard normal very easily.
rnorm(n = 5)
## [1] 2.2130967 1.7633171 0.2901826 -1.3893091 2.1754976
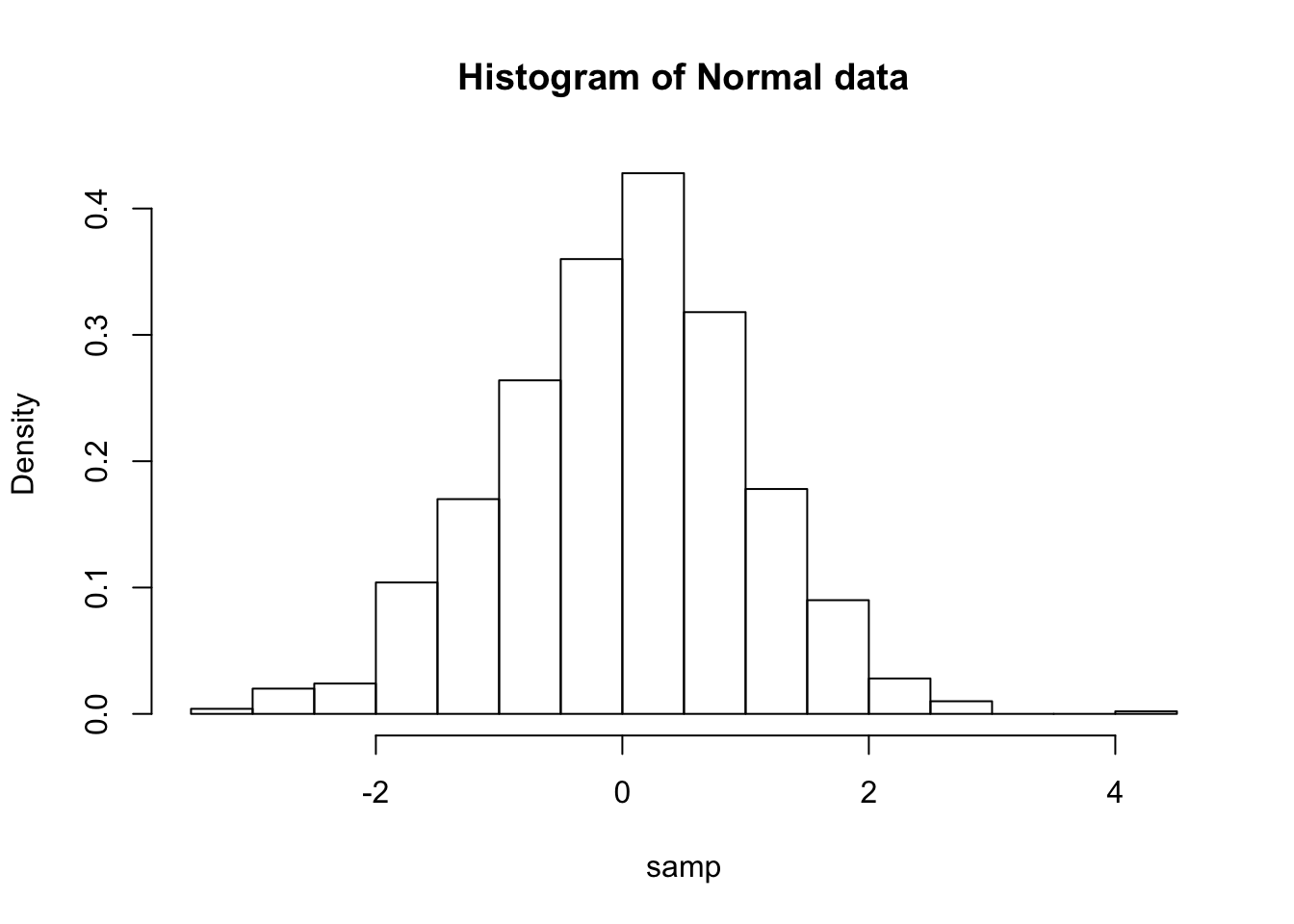
The normal distribution is a continuous distribution, so we shouldn’t visualize samples from it with a standard bar plot. (Why not?) Instead, a histogram will be more suitable.
samp <- rnorm(1000) hist(samp, freq = FALSE, main = "Histogram of Normal data")
We can also plot an approximation to the continuous density based on our sample.
plot(density(samp), xlab = "x", ylab = "Density", main = "Approximate Distribution")
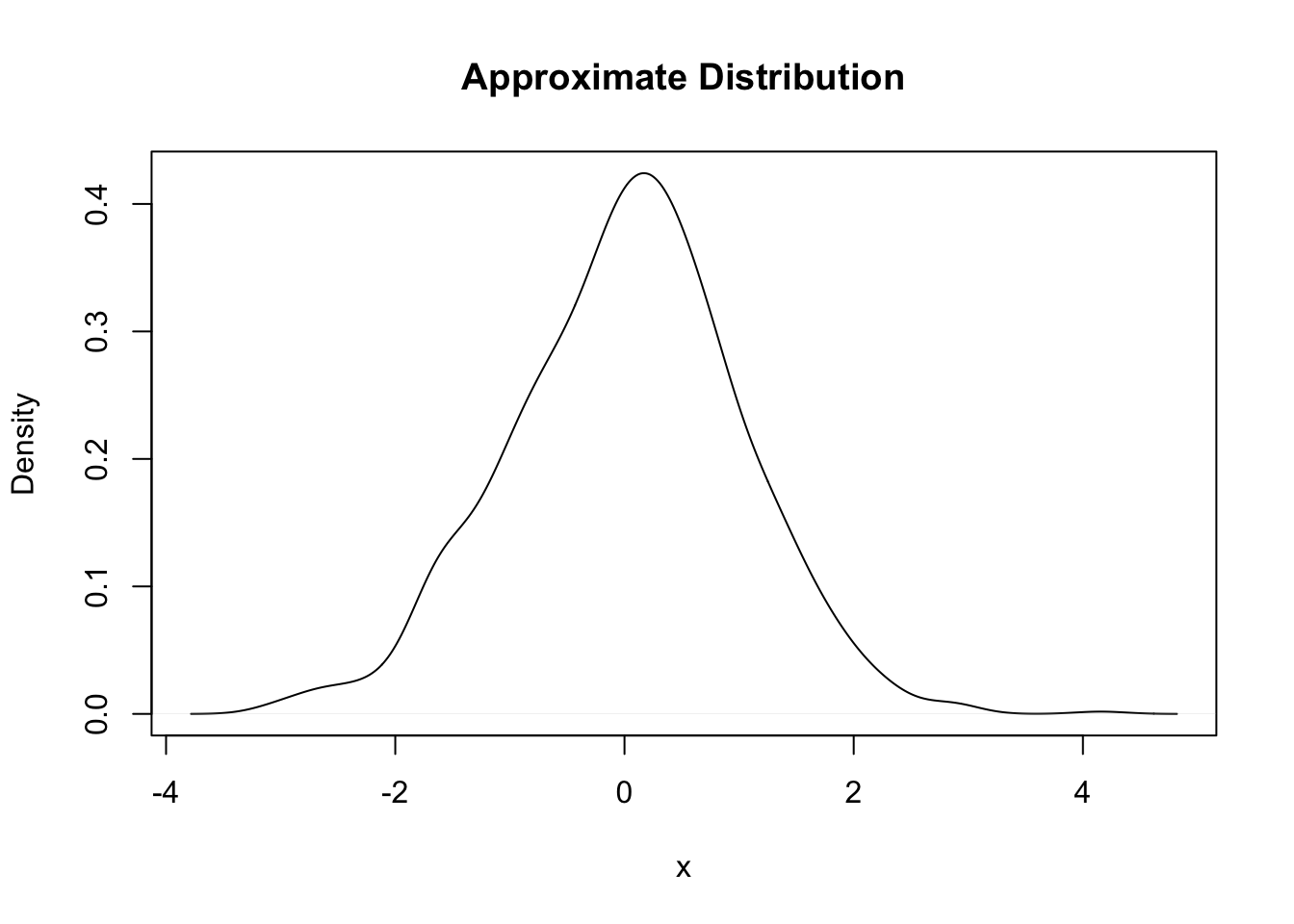
This approximation is achieved by choosing a “kernel” along with an appropriately sized bandwidth (similar to choosing the width of bars in a histogram). We won’t worry much about the details, but just know that different kernels and bandwidths will give different density approximations, so be aware of this, and try out some choices to see what differences you get (?density to see how to modify the default values).
Density Functions
If our sample had an infinite number of draws from the normal distribution, we would get an extremely smooth bell-shaped curve. It looks like this:
curve(dnorm(x), xlim = c(-3, 3), main = "The Standard Normal Distribution", ylab = "Density")
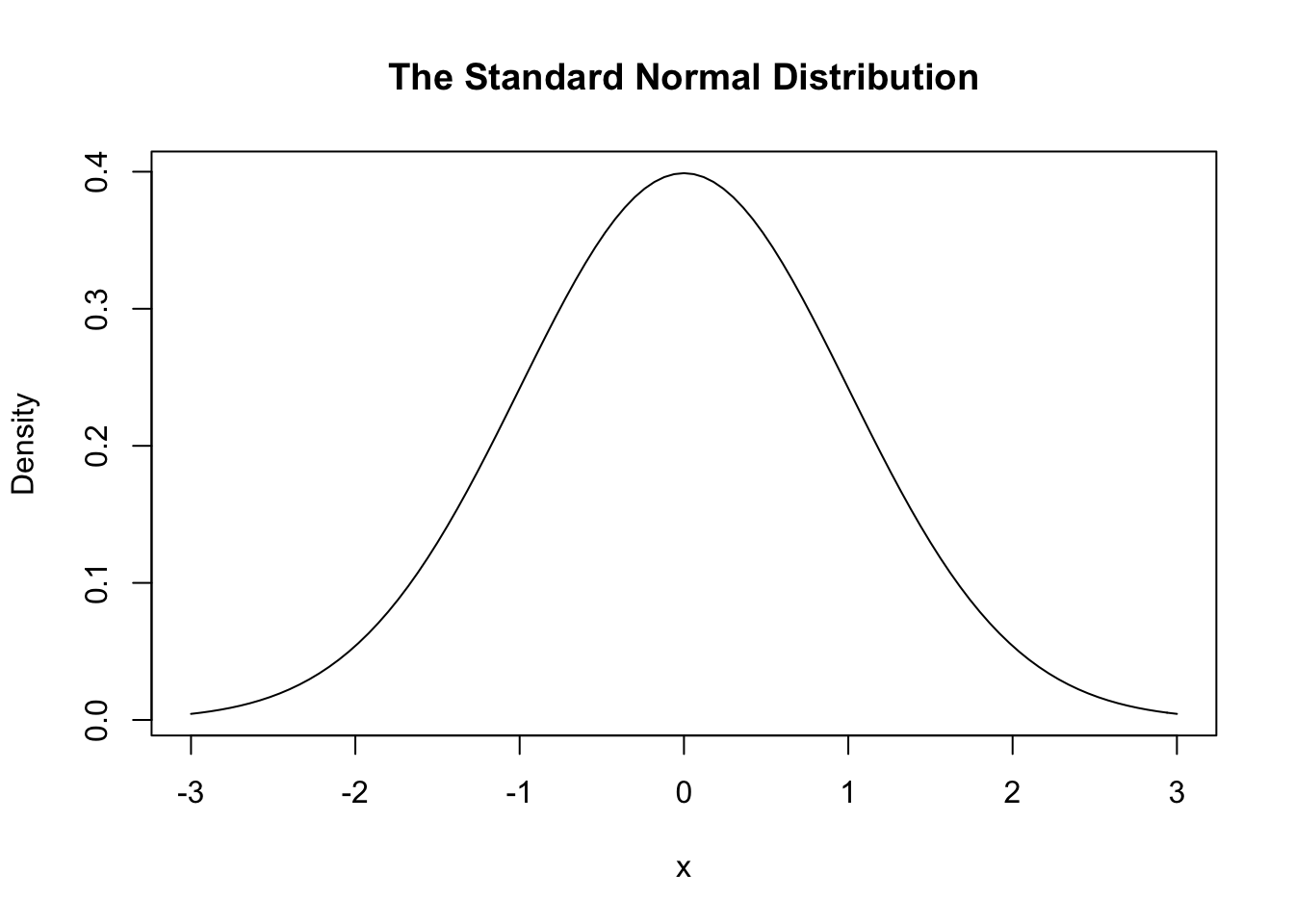
Here dnorm() is the density function of normal distribution. The curve() function is used to plot a smooth curve. It takes a function as an input (here the normal PDF), computes the function values at numerous different values selected from its domain, and then plots these pairs and connects them with line segments.
This distribution is always bell-shaped (it is sometimes called the normal curve). However the location and spread are determined by two parameters: The mean parameter (or ) specifies the center of the distribution, and the sd parameter (or ) controls the spread (tall and narrow vs. wide and flatter).
curve(dnorm(x, mean = 2, sd = 0.5),
xlim = c(-4, 4), col = "red",
main = "The Normal Distribution", ylab = "Density")
curve(dnorm(x, mean = -1, sd = 1),
add = TRUE,
col = "blue")
text(x = c(-1, 2), y = c(0.2, 0.4), # adds some text to the plot
labels = c("N(-1, 1.0)", "N(2, 0.5)"),
col = c("blue", "red"))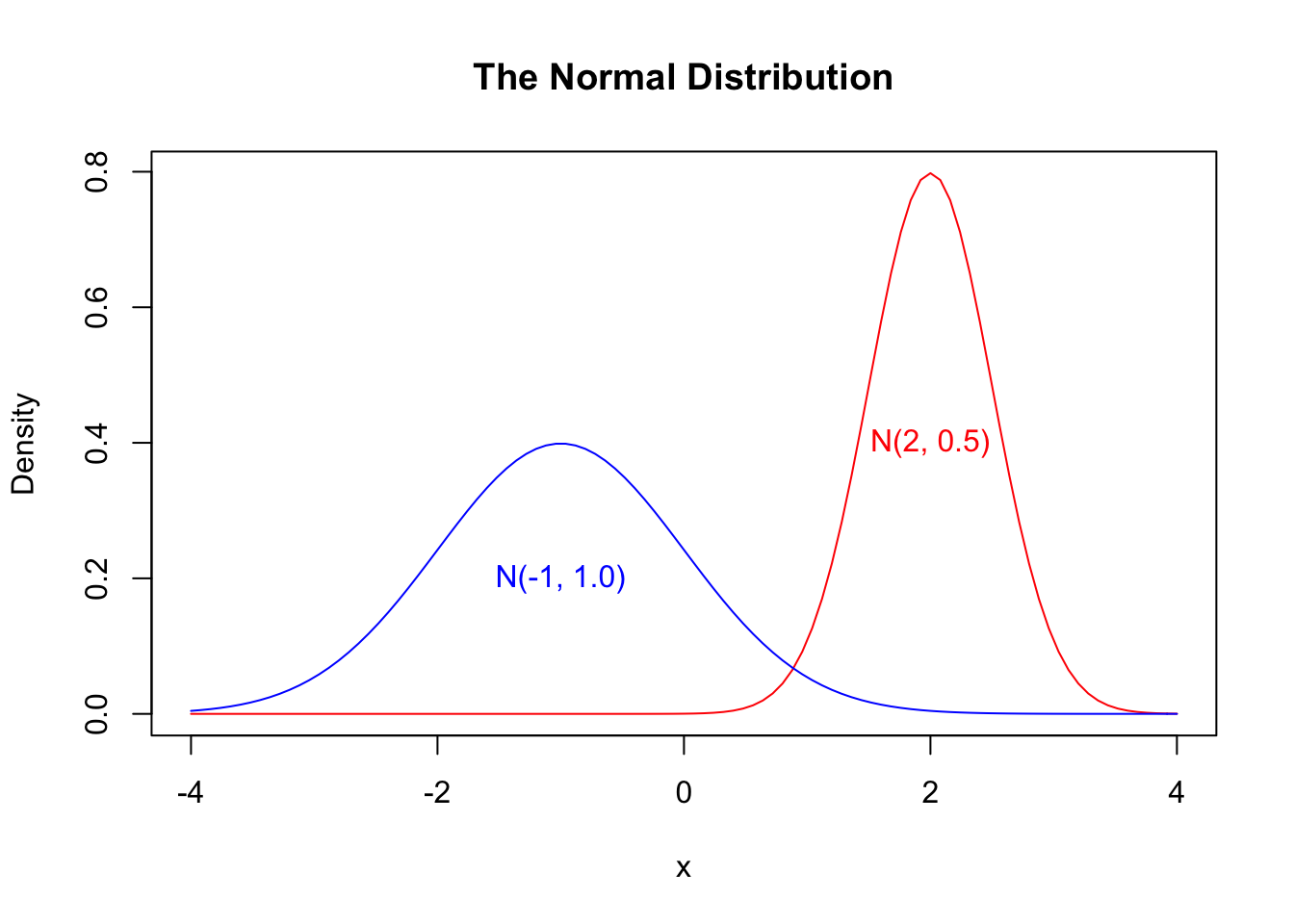
Cumulative Distribution Functions
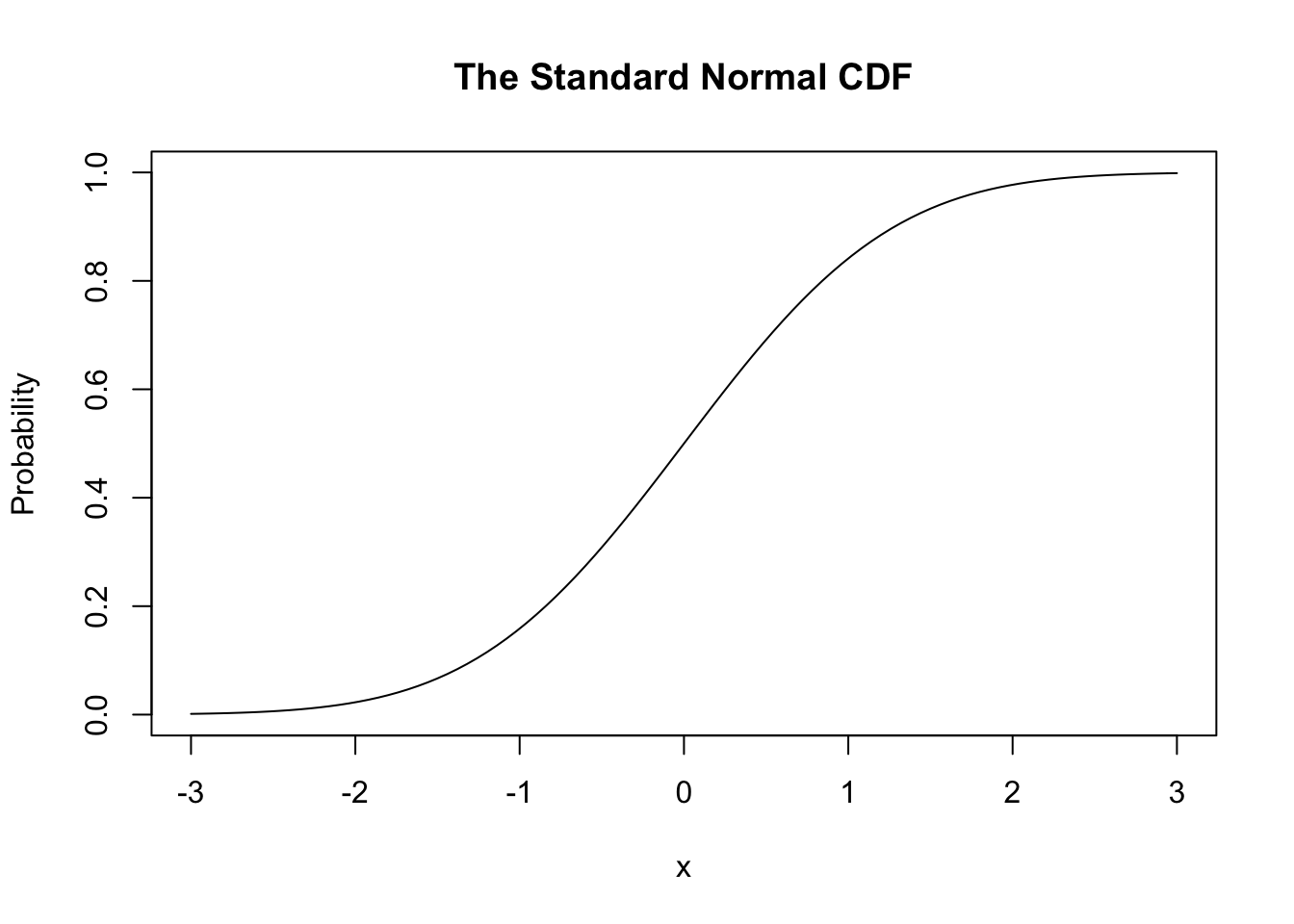
The (standard) normal CDF looks like this,
curve(pnorm(x), xlim = c(-3, 3), main = "The Standard Normal CDF", ylab = "Probability")
Normality
We can also check whether our data looks normal using a Q-Q plot.
qqnorm(samp, pch = 16, col = rgb(0, 0, 0, alpha = 0.5)) #transparent grey qqline(samp, col = "red")
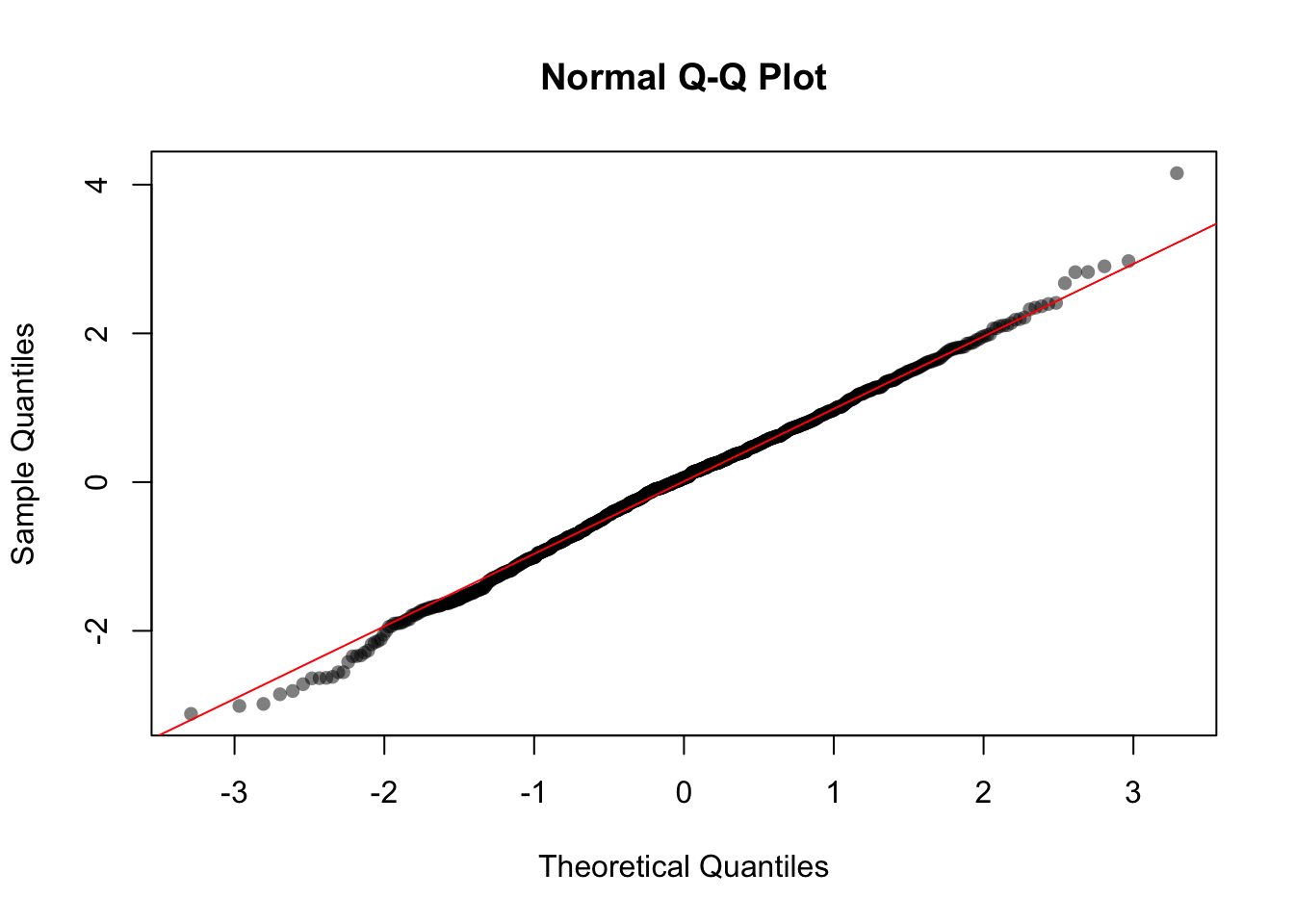
Here our data closely follows the ideal line, which confirms that our sampled data is approximately normally distributed.

