1、什么是密度聚类?
2、相较于划分聚类方法,密度聚类的典型优点是什么?
3、熟练使用sklearn库进行密度聚类的编程。
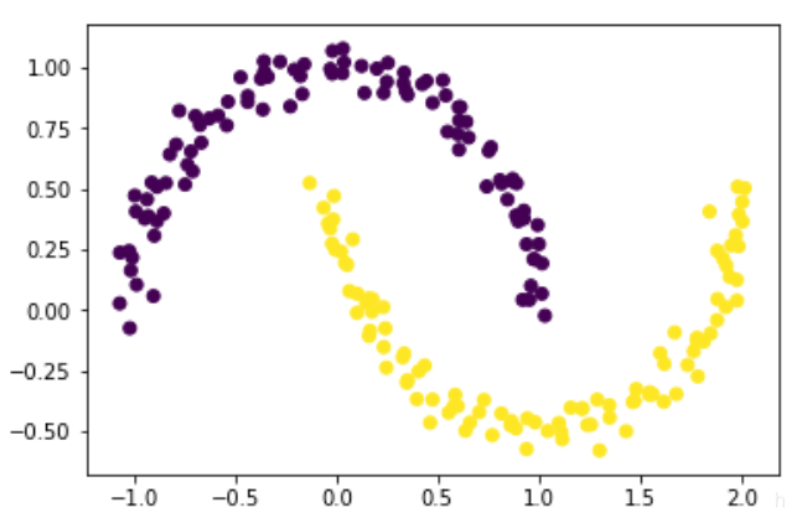
from sklearn.datasets import make_moons
#一个简单的玩具数据集可视化聚类和分类算法。
X,y = make_moons(200, noise = 0.05, random_state=0)
plt.scatter(X[:,0],X[:,1], c=y)
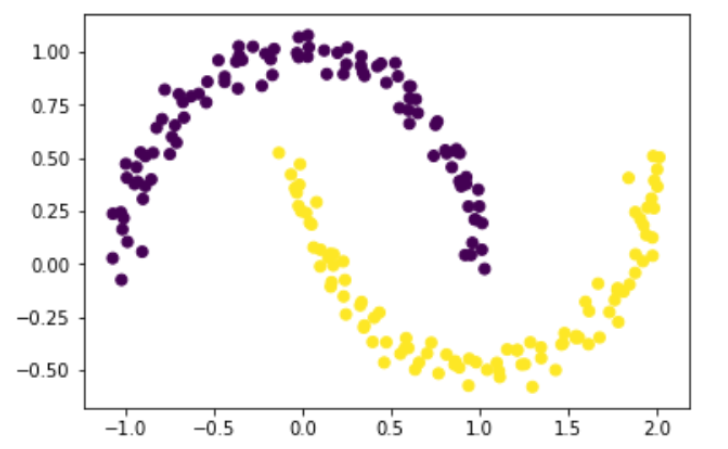
1、使用Kmeans聚类方法
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=2)
kmeans.fit(X)
labels = kmeans.labels_
kmeans.predict(X)#kmeans.predict(X)== kmeans.labels_
#模型cluster_centers_ 属性保存了聚类结果的中⼼点
centers = kmeans.cluster_centers_
#利用可视化图形查看最终聚类结果
plt.scatter(X[:,0],X[:,1], c = labels)
plt.plot(centers[:,0], centers[:,1],'ro')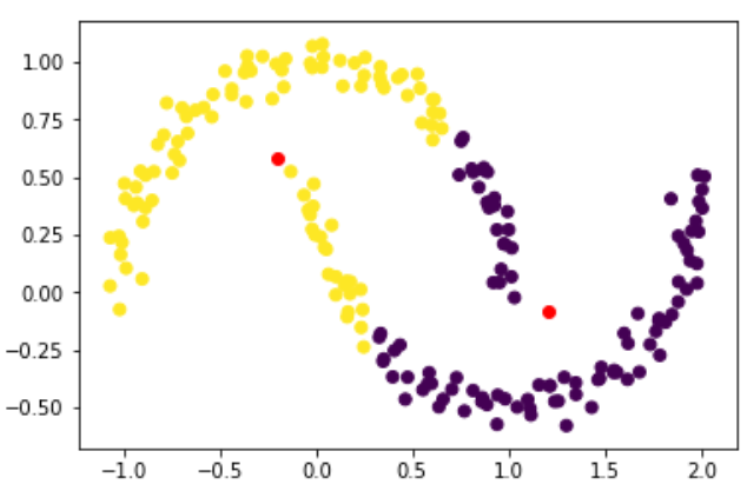
2、DBSCAN聚类
#DBSCAN聚类实践
from sklearn.cluster import DBSCAN
db = DBSCAN(eps=0.3, min_samples=10)
db.fit(X)
DBSCAN(algorithm='auto', eps=0.3, leaf_size=30, metric='euclidean',
metric_params=None, min_samples=10, n_jobs=None, p=None)
plt.scatter(X[:,0],X[:,1], c = db.labels_)