
生物神经元模型
• 1904年生物学家发现神经元结构
整个神经元内部具有一致的脉冲电位信号
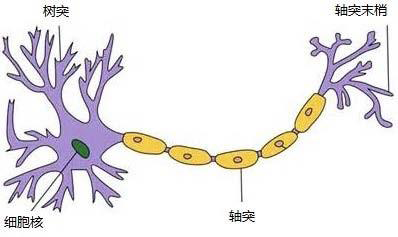
通过多个树突获取信息,通过轴突传递信号
轴突末端有多个突触,将信号输出
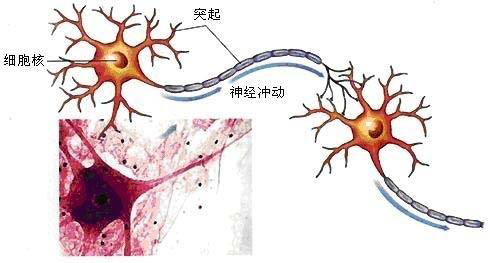
多个神经元之间通过轴突、树突形成连接,构成神经元网络。
神经元之间能够逐级传递脉冲电位信号
神经元之间连接数量的多少、粗细等生物特征表示了连接强度
人工神经元
– 1943年,美国心理学家沃伦·麦卡洛克Warren McCulloch和数理逻辑学家沃尔特·皮茨Walter Pitts参考生物神经元的结构,提出抽象神经元模型MP。
– 后来经过完善形成人工神经元模型。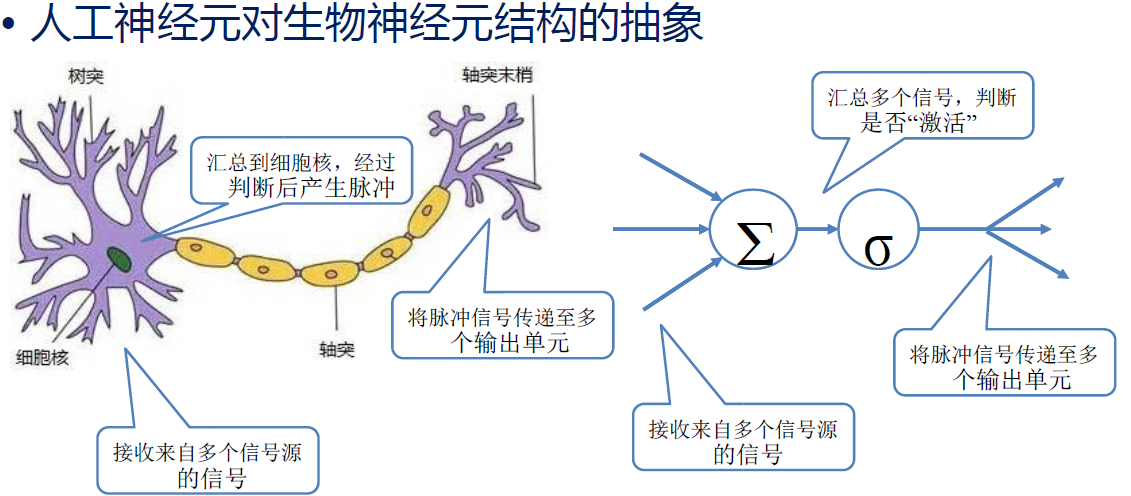
神经元如何“学习”?
• 1949年心理学家Donald Hebb提出了神经心理学理论,解释了神经元学习的规律:
– 神经网络的学习体现在突触部位
– 突触联结两个神经元,连接强度能够随着神经元的活动而变化
– 两个神经元的“活性”越大,突触连接强度越大。
• Hebb的理论最大的突破,是认识到:
– 神经元之间的连接强度是可以变化,
– 这种变化能力,是神经网络处理信息、学习知识的源泉
• Hebb的理论后来被称为Hebb学习规则,成为连接主义流派的主要原理。
– Hebb学习规则可以使神经网络具有统计能力,从而把输入信息按照相似性划分为若干类。
– 与人类观察和认识世界的过程非常吻合
从Hebb到感知机
1957年,Rosenblatt在纽约时报上发表文章
Electronic ‘Brain’ Teaches Itself,首次提出了可以模型人类感知能力的机器,并称之为感知机。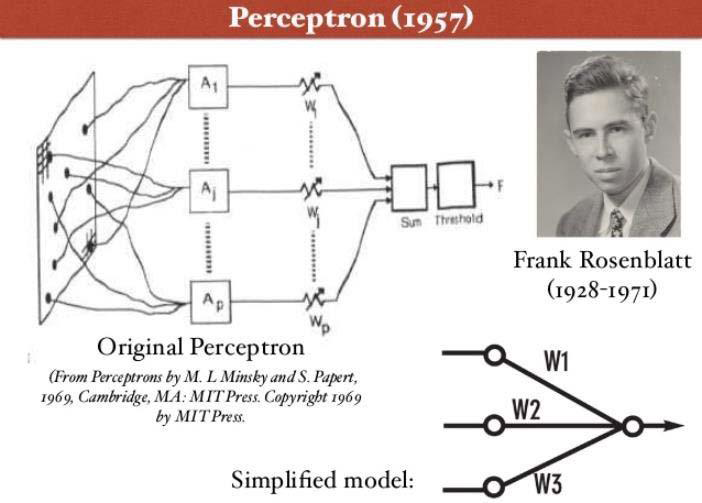
感知机:线性模型
• Frank的感知机模型能够通过大量“实例”来训练神经元的“权重”。
对于某个实例,如果感知机对其类型判断错误,则神经元的权重降低,作为惩罚。
反之,则提高权重,作为奖励。
直至对于所有实例,神经元都能够无误区分。
• 1960年,维德罗改进了感知器的训练方式
提出以“误差最小”准则来训练神经元的权重,创造了第一个线性分类器。
目前机器学习思想的鼻祖。
1969,人工神经网络遇冷
1969年,有关感知机、神经网络的研究进入繁荣期,马文·明斯基写了一本书《感知机》。他提出了著名的XOR问题和感知器数据线性不可分问题。并提出,如果将感知器增加到两层,计算量过大,而且现有的感知器算法将失效。所以,他认为研究更深层的网络是没有价值的。这几乎宣判了人工神经网络死刑。导致此后长达十余年的神经网络发展低谷。
从感知机到多层网络的 BP 算法
– 此后,人工神经网络研究成为小众,但仍有人在坚持。
– 1974 年,哈佛大学博士研究生保罗提出了 BP 算法的思想,但未得到重视
– 1985 -1986,鲁梅尔哈特,他的学生辛顿(Hitton)等人,重新发现了 BP 算法,并成功用于训练多层感知器(MLP),在非线性分类问题中大获成功,突破了人工神经元异或瓶颈。

MLP 与 BP 算法
人们陆续证明:神经网络的层数决定了其分类能力,双隐层的网络就可以解决任意复杂度的分类问题!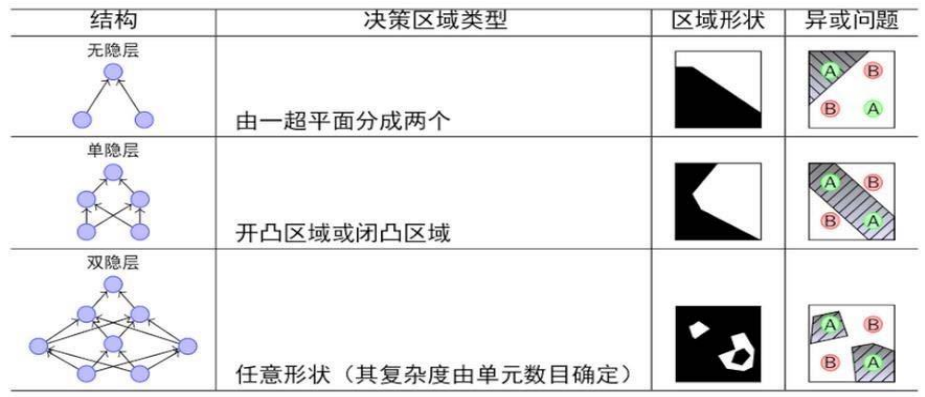
1980:复兴的人工神经网络
– 历史总是惊人的相似,多层网络和 BP 算法大获成功,神经网络的学者们再次登上了《纽约时报》的专访。
– 就连娱乐界都开始受到了影响, 1984 《终结者 1》上映,机器人终结者的扮演者施瓦辛格有一句经典台词:“我的 CPU 是一个神经网络处理器,一个会学习的计算机。”
神经元层数瓶颈
1、MLP 理论上虽然可以有“多层”,但有效的只有三层。随着层数增加,计算量指数级增加,但性能并没有实质提高。
2、BP 算法对三层以上的神经元网络,实际上无法有效训练。
此后 20 年,人工神经网络因 BP 算法而建立起完整的理论框架,却因“多层”问题无法解决,始终未得到突破。
SVM 兴起,人工神经网络再次衰退
– 90 年代中期,由 Vapnik 等人发明的 SVM 算法诞生,很快就在若干个方面体现出了对比神经网络的优势:无需调参;高效;全局最优解。SVM 迅速打败了神经网络算法成为主流。
– 当时,标准神经网络 MLP 有 3 层神经元。
– SVM 本质上可以看做一种 2 层网络,层数少,需要的样本量小。优化算法清晰、简单。
– 在 1990 年代,大量 2 层结构的优化算法模型提出,促使统计机器学习方法成为主流。人工神经网络则再次陷入低谷。
1981 契机
1981 年的诺贝尔医学奖,分发给了 David Hubel、Torsten Wiesel 和Roger Sperry。前两位的主要贡献是:发现了人的视觉系统的信息处理是分级。
大脑处理视觉信号的原理
大脑的工作过程,是一个对接收信号不断迭代、不断抽象概念化的过程。这个过程其实和我们的常识是相吻合的,复杂的图形,往往就是由一些基本结构组合而成的。同时我们可以看出:大脑是一个深度架构,认知过程也是深度的。
1989,BP 用于卷积网络
在 BP 算法提出 3 年之后,嗅觉敏锐的 LeCun 发现多层卷积神经网络与视觉处理过程的相似性,并将 BP 算法用于训练神经网络,实现了手写数字识别算法。
1998 LeNet-5
此后,1998 年 LeCun 在文章《Gradient-based learning applied to document recognition》中提出 LeNet-5,是卷积神经网络的第一个正式模型。
2001,互联网泡沫
• 上世纪 90 年代后期,互联网兴起。短短几年时间,互联网经历了一次跨越发展,导致 2001 年的互联网泡沫破裂。
• 随着互联网泡沫破裂,投资撤回,许多研究方向被迫中断。• 如果当时互联网没有这次风波,或许卷积网络能够早 10 年应用。
2006,深度学习元年
加拿大多伦多大学教授Geoffrey Hinton 在《科学》上的一篇论文中提出了两个观点:
(1) 多层人工神经网络模型有很强的特征学习能力,深度学习模型对原始数据有更本质的表述
(2) 深度神经网络可以采用逐层训练方法优化。将上层训练好的结果作为下层训练过程中的初始化参数。
深度学习的繁荣
• 从 2006 年起,各种神经网络模型又开始得到重视。
• 2010 年用于语音识别的 DNN 结构
• 2012 年用于语言模型的 RNN 结构
• 2013 用于图像处理的 CNN 结构
• 2016 用于机器翻译的 seq2seq 结构
• 2016 年开始,人们更多开始关注脑科学和神经科学,相继提出 LSTM、Attention、Memory 机制。

