
强化学习的基本思想:
–首先,强化学习(Reinforcement Learning, RL) 并不是一个独立的方法,而是一种机器学习的模式,或者说是一种思路。
–强化学习认为,计算机单纯通过感知环境,与环境交互,并且从交互中获得评价反馈,就可以适应所处的环境。从我们看来,就相当于计算机学习得到了环境下的某些知识,实现了机器学习。
–强化学习的思想,来源于自然界生物的学习能力。
–比如我们常常觉得小猫天然会爬树、小狗天然会游泳。
–但实际上小猫、小狗的这种能力,并不是天然的,而是在树上、水里通过适应环境学习得到的。这种学习是不需要正确答案来“教”的,单纯靠适应环境、不断尝试就可以实现。
强化学习与之前介绍的有监督学习,有类似的地方,也有区别。
典型的有监督学习,可以看作一个“开环”的流程。
我们从“环境”中提取一些样例数据,数据中带有监督信息。
然后我们根据输入值和监督信息来设计算法,训练模型去学习监督信息。
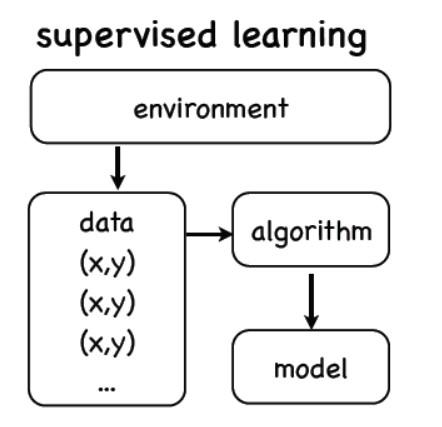 《开环》
《开环》
强化学习中,我们从环境中得到的是合理的行动方式,行为。
这些行为没有监督信息,即我们只知道在这个环境中可以干什么,但不知道后果。
经过算法计算后,模型把计算结果返回给“环境”,这时环境才给我们“奖赏”,即动作产生的后果。
我们用这个奖赏来训练、更新模型。可以看出,强化学习的整个过程形成一个“闭环”。
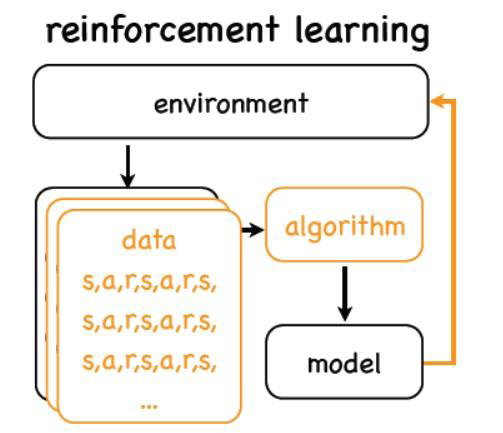 《闭环》
《闭环》
强化学习与无监督学习也不完全一样:
无监督学习:完全没有提供环境的奖励信号,没有监督信号
强化学习:环境所提供的“奖励”,实际上就是监督信号。
因此,强化学习近年来成为机器学习和人工智能的一个新的研究领域。
我们通过例子来进一步讲解。
例7.11 小孩学习走路
为了得到强化学习的抽象框架,我们以小孩学习走路为例来介绍。
我们设想一下,一个一岁的小孩学习走路的过程:
(1)小孩作为一个独立的个体。
(2)小孩在确定的环境中,有明确的目标:从当前位置走到妈妈怀里。
(3)小孩能够掌握基本的走路动作,比如抬腿迈步、挥手等。
(4)如果成功走到妈妈怀里,则得到奖励:笑脸、怀抱;
反之则受到惩罚:摔跤、找不到妈妈,等。
通过反复多次练习,小孩能够学会走路。
从刚才的描述中,我们可以抽象出小孩学习走路的关键要素:
主体(小孩)
环境(地板、墙、起点、目的地)
动作(迈步、挥手)
奖惩(笑脸、怀抱、摔跤)

强化学习的基本思想
我们把图中的各个要素做进一步抽象,就可以强化学习的结构图。其中:
agent为智能体,对应于例子中的小孩。agent具有明确的目标,并且能感知自己所处的环境和状态。
agent根据目标来指导自己的行为,在每一步,agent选择一个可行的动作,并通知环境自己的动作。
– 环境根据agent的动作,推断两件事情:
1)agent执行完该动作之后会产生什么后果,是奖励,还是惩罚?
2)执行完动作之后,agent会处于什么样的状态?
– Agent接收到环境的反馈,更新自己的状态,
同时用得到的奖励来更新自己的模型参数。
– 重复以上过程。
例7.12 旅行商问题的强化学习
旅行商问题:从A点出发到达F点,如何行动,使得整体路程最短?
我们按照强化学习的框架去映射一下。
智能体:旅行商
状态:智能体当前所处的节点,如:{A, B, C, D, E, F}
动作:智能体可以从一个状态走到下
一个状态,如:{A -> B, C -> D, etc}
奖励:智能体每行动一步,都会消耗一定的距离,作为奖惩信号。
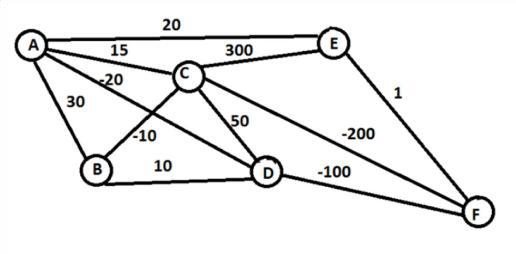
• 在这个框架中,每一种成功从A走到F的路径,都是一个“策略”,即问题可能的解。
• 我们要求解其中消耗距离最短的策略。
这种强化学习我们又称为“Policy based”学习。
• 在这个问题中,比如智能体从 A 开始,可以选 (B, C, D, E),然后判断 D 最优,就走到 D。此时,可以选(B, C, F),判断F 最优,就走到 F,完成任务。此时得到一个可行的“策略”。然后计算这个策略产生的“奖励”,用来更新模型。
• 然后再次重复这个过程,不断更新模型。
强化学习的类型
• 上述例子就是基于策略的强化学习。这种类型的方法重点在寻找最优的动作组合。
•• 还有其他的类型,比如:
– Value based方法, 目标是找到最优的奖励总和。
– Action based方法, 目标是寻找每一步的最优行动。
近几年,强化学习得到了越来越多的关注。下面我们通过几个典型的例子来了解一下强化学习目前的应用情况。
强化学习的应用
• 我们介绍的第一个例子,是自动驾驶。在自动驾驶研究的早期,人们需要精心设计大量规则,来指导汽车驾驶。实际上,自动驾驶本身是一个与环境交互非常密切的活动。人工驾驶规则总是无法覆盖环境的多样性。这时
候使用强化学习就非常适合。
• 在引入强化学习后,汽车的自动驾驶动作会被迅速评估,得到其安全程度、合理程度等信息。
• 然后模型通过在虚拟环境中大量练习、反复试错,完成模型的训练。
• 避免了制定规则,完全让模型自主学习和探索。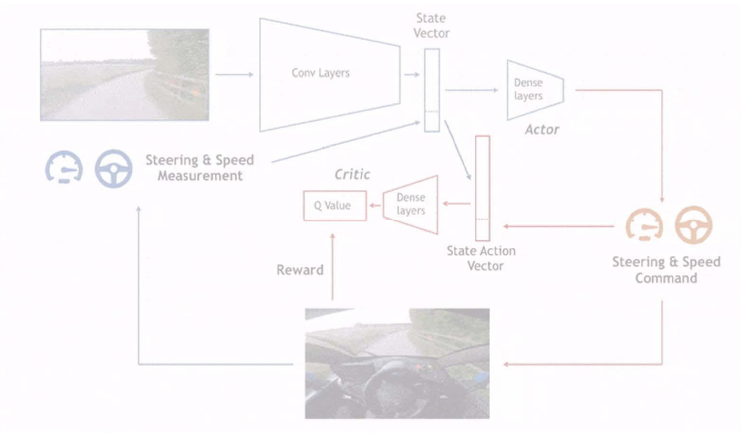
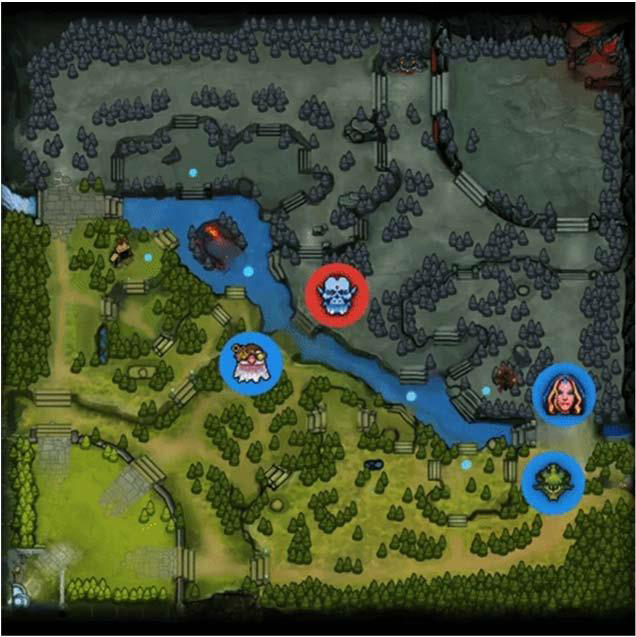
• 强化学习的第二种应用,是AI游戏和电子竞技。这个领域也是需要大量环境交互操作。目前,除了熟知的围棋,强化学习也开始应用于电子游戏竞技活动种,如Dota、星际争霸等等。而且均取得了不错的进展。
2018年6月 OpenAI 模型在Dota2中战胜业余人类选手,
2018年7月展示强化学习在多人射击游戏中的使用
• 此外,强化学习还可以用来做虚拟生命的建模,比如deepmind
做出的火柴人学走路的模型:
• 模型令人惊讶之处在于,经过大量学习之后,火柴人走路的姿态、方式有了明显的改观。
• 很多时候这种姿态,与刚学会走路的孩、或者与自然界中真实的动物的行走方式有类似之处。
展望
• 强化学习的过程,实际上就是智能体适应环境的过程。与真实的生命过程也有类似之处。
• 目前,强化学习作为机器学习和人工智能的一个重要分支,受到越来越多的关注,许多学者也开始认为,强化学习代表了人工智能未来发展的方向。

