监督学习 弱监督学习 无监督学习
• 全监督学习:方法丰富、研究充分、性能好、成本高
• 无监督学习:方法简单、数据成本低、性能难以提升
• 弱监督学习: 对部分数据引入监督
使用间接的答案信息 是一种思路 是一类方法的总称
例7.8 远距离监督用于关系抽取
• 文本中的实体之间存在大量关系,如下面百度百科段落:
• 假设我们要训练一个模型,自动识别上述关系,一般来说,需要大量标注数据。
•关键问题:如何获取标注信息?
优势:同一个页面出现的确定信息自动做上标记,生成带有标记的样本。
远距离监督的缺点:
• 方法简单,但远距离监督信息来源有限。
• 往往不准确,容易引起错误。
远距离监督的优点:
• 方法简单。
• 数据量可以做的很大。
半监督学习的核心思想:
一部分数据带有人工标记知识
另一部分数据无标记
通过学习有标记数据,逐渐扩展无标记数据
例7.9 社交网络上的半监督学习(基于图)
• 在一个社交网络上,有些人喜欢音乐,有些人喜欢体育。
– 已知各有几个人的喜好标签,
– 并且知道所有人之间的社交关联(如关注、转发等)
• 如何判断其余人的喜好?
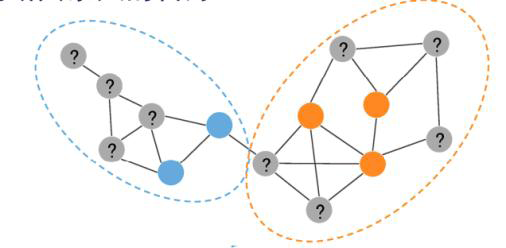
• 解决思路:
根据特征信息计算节点之间的相似度
认为相似度越高的节点,标签越倾向于一致
从有标签样本出发,根据相
似度将标签“传播”到未标记样本
最终实现标签标记
迁移学习
• 人类具有举一反三的能力。
打乒乓球—打网球
下国际象棋—下中国象棋
• 计算机是否可以实现类似的功能?
任务A 与 任务B 具有某种相似性
利用任务A的学习经验,解决任务B
即迁移学习。
迁移学习的类型
• 样本迁移:
寻找任务A标注数据中,直接能够用于任务B的数据
训练任务B的模型
• 特征迁移:
估计任务A和B之间的“差距”,设计一个变换方程,将任务A的数据转换为任务B的数据,再进行训练
• 模型迁移:
使用任务A训练得到的模型,经过某种变换直接应用于任务B
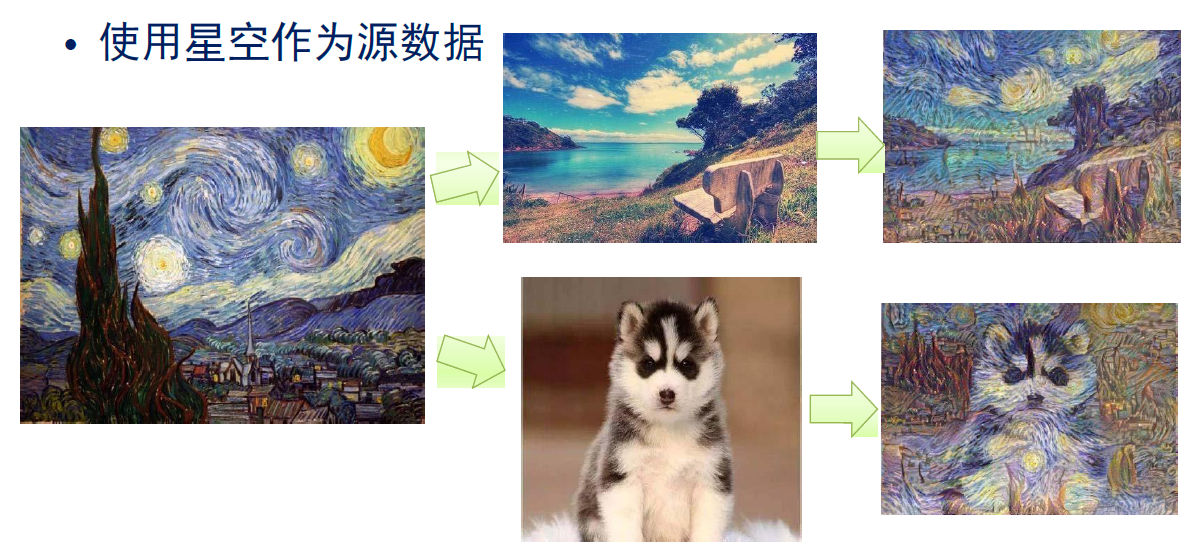
例7.10 图像风格的迁移学习
• 给定某种风格的图画样本,如梵高油画集合
• 训练模型,能够表达梵高图片中的某些风格
• 给定不具有该风格的图像
• 不改变内容,仅将梵高风格添加到图片中
例7.10 图像风格的迁移学习
https://blog.csdn.net/aaronjny/article/details/79681080