
7.3 无监督学习
上一节
下一节
有监督学习的最大问题:标注数据的稀缺和昂贵
有监督学习的最大问题:需要专业人士完成标注

无监督学习的特点:
有明确的学习目标
有样本数据
不需要人工标注知识
提升难度大
无监督学习方法:聚类
– 人类和许多动物都有“归堆” 的能力。这就是聚类。
– 聚类算法根据某种“相似程度” 或者“距离”,把距离近或者相似度高的实例归到一类。
– 与分类类似,大部分聚类也需要事先指定聚类的数目。
例7.6 支持向量机模型(SVM)
• 问题:
– 假设我们有如下的样本集合,
– 通过聚类算法,将无序样本划分为 k=3 个类别。
思路:
– 首先假设每个类别都聚集在某个“中心点”附近。
– 最初时,任选3个样本作为“中心点”。
– 逐一计算剩下的样本与“中心点”的距离,距离谁近,就归到哪类。
– 根据最新的类别划分情况,重新计算“中心点”。
– 循环该过程,直至中心点不再改变。
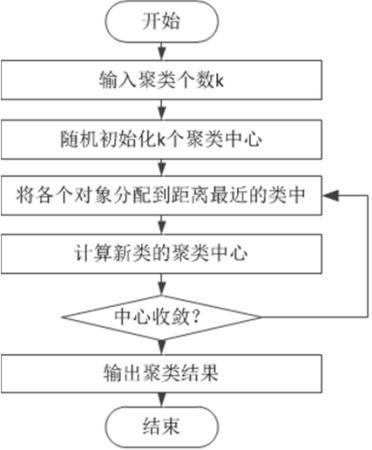
• 关键问题:初始选择的3个点,很重要!
– 选择两两距离最远的3个点。
– 随机划分样本成3堆,以3堆的平均重心作为初始点。
• 关键问题:距离计算方法。
– 聚类大量依赖于距离或者相似度计算。因此确定一种距离非常重要。
无监督学习方法:自动编码器
例7.7 自动编码器的应用
(1)图像抗噪
原始图像添加噪声之后再进入编码器,试图生成没有噪声的图像
例7.7 自动编码器的应用
(2)数据降维
– 原始数据生成的模型往往仍然规模比较大
– 此时可以使用自动编码器做一次降维,不损失信息的情况下,降低空间使用。

