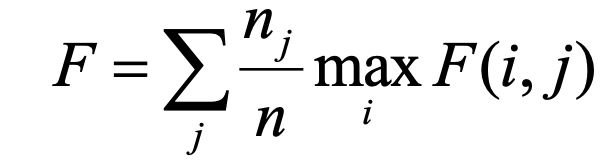Supervised Cluster Evaluation 有监督的聚类结果评估
上一节
主要知识点:
面向分类的簇有效性度量
使用分类的度量(如熵、精度、召回率、F度量等)去评估簇包含单个类的对象的程度。
熵,度量的是每个簇由单个类的对象组成的程度。对于簇t,相应的熵的计算公式如下式所示,其中p(j|t)是簇t的数据对象属于类j的概率,如下式所示,等于ntj除以nt,其中,ntj是簇t中类j的数据对象个数,nt是簇t中数据对象的个数。
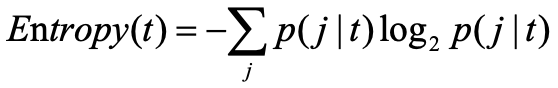

精度,即簇中一个指定类的对象所占的比例。对于簇t,关于类j的精度可以表示为下式所示,即等于p(j|t)。
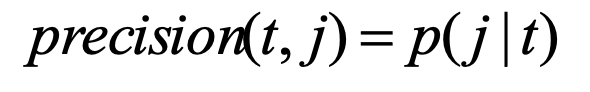
召回率,度量的是簇包含一个指定类的所有对象的程度。对于簇t,关于类j的召回率可以表示为下式所示,即等于ntj除以nj,其中,nj是类j所包含的数据对象的个数。
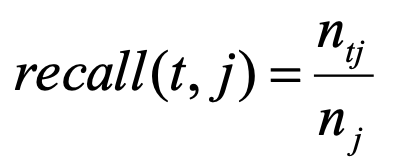
F度量,和分类问题一样,它是精度和召回率的组合,度量在多大程度上,簇只包含一个特定类的对象和包含该类的所有对象。对于簇t,关 于类j的F度量可以表示为下式所示。
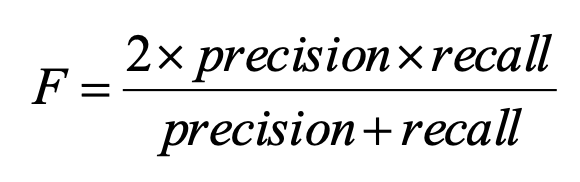
2.面向相似性的簇有效性度量
一种是理想的簇相似矩阵,如果数据对象i和j在同一个簇中,其第ij项为1,否则为0。另外一种是理想的类相似度矩阵,如果数据对象i和j在同一个类,其第ij项为1,否则为0。那么依据同一个簇的任意两个对象也应当在同一类的思想,取矩阵的相关度作为簇有效性的度量。
3.关于层次聚类有效性的度量方法
基本思想:基于F度量,评估层次聚类是否对于每个类,都至少有一个相对较纯的簇并且包含了该类的大部分对象。
计算步骤:步骤一,针对每个类,计算簇层次结构中每个簇的F度量;步骤二,对于每个类,取不同簇中最大的F度量;步骤三,通过计算每类的F度量的加权平均,计算层次聚类的总F度量。相应的计算公式如下式所示,其中i表示簇i,j表示类j,nj表示类j的数据对象个数,即类的大小,n为总体数据对象的个数。