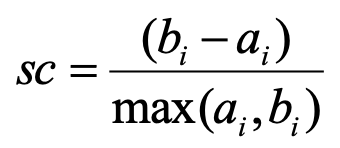Unsupervised Cluster Evaluation 无监督的聚类结果评估
上一节
下一节
主要知识点:
1.簇评估
无监督簇评估,即在不考虑外部信息的情况下对聚类结果的优良性进行度量。
有监督簇评估,即对聚类结果与外部提供的信息如类别标签的匹配程度进行度量。
2.簇的凝聚度和分离度
簇的凝聚度是用来确定簇中的对象密切相关程度的一种度量,可以定义为关于簇质心的邻近度的和,即在k-均值算法里提到的目标函数误差的平方和SSE,可写成式(1)的形式,如果用欧几里得距离来进行度量,可写成式(2)的形式。其中,ci是第i个簇的质心。
簇的分离度是用来确定某个簇不同于其他簇的度量,可以定义为组平方和SSB,即簇质心ci到所有数据点总均值c的距离的平方和,如式(3)所示,其中,mi是第i个簇的大小,c是所有数据对象的均值。

3.轮廓系数
是一种结合了凝聚度和分离度的方法。
廓系数的计算过程,以数据对象i为例,第一步,首先计算它到簇中所有其他对象的平均距离,记为ai;第二步,计算其到其他不包含数据对象i的任意簇的所有对象的平均距离,对于其他所有的簇,找出最小值,记为bi;第三步,数据对象i的轮廓系数的计算公式如下式所示。轮廓系数的取值范围为-1到1,当ai等于0时,取最大值1,当bi等于0时,取最小值-1,当轮廓系数越大时,表示更好的凝聚性。