Fiancial Classification Evaluation-Model Evaluation 分类算法在金融应用中的结果评估——模型结果评价
上一节
下一节
主要知识点:
1. 如何获取分类模型的测试集?
保持方法,它将标记的集合随机的划分为两个不相交的集合,一个作为训练集,另外一个作为测试集。一般分为三个步骤:第一步,将标记的数据集划分为两个部分,训练集和测试集,如图所示;第二步,从训练集中学习出分类模型;第三步,运用测试集验证模型的性能。
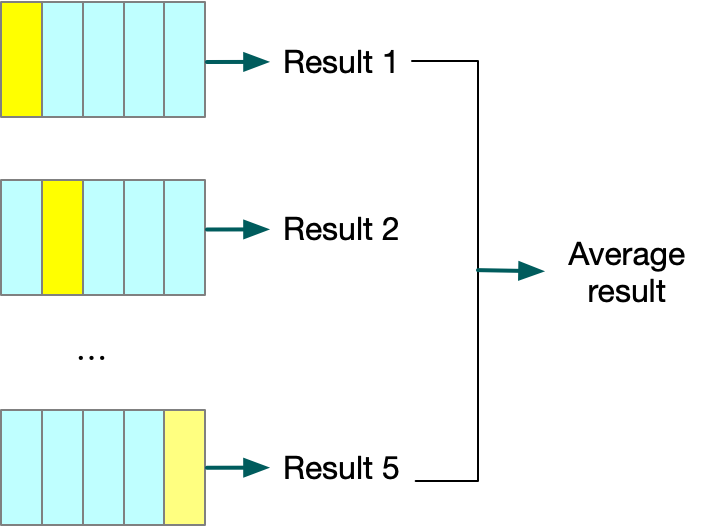
交叉验证法,它有效的利用标记的集合中所有的标记实例进行训练和测试。第一步,由于交叉验证又被称为k折交叉验证,所以首先需要选择k的大小。一般来讲,k通常为5或者10;第二步,将标记数据集划分为k个相等大小的分区;第三步,选择一个分区作为测试集,其他的k-1个分区作为训练集;第四步,使用训练集训练分类模型;第五步,使用测试集验证模型的性能;第六步,保存测试结果;第七步,重复第三步到第六步k次;第八步,将结果进行平均处理作为最后的结果。如下 图suo示,是一个5折交叉验证方法的示意图。
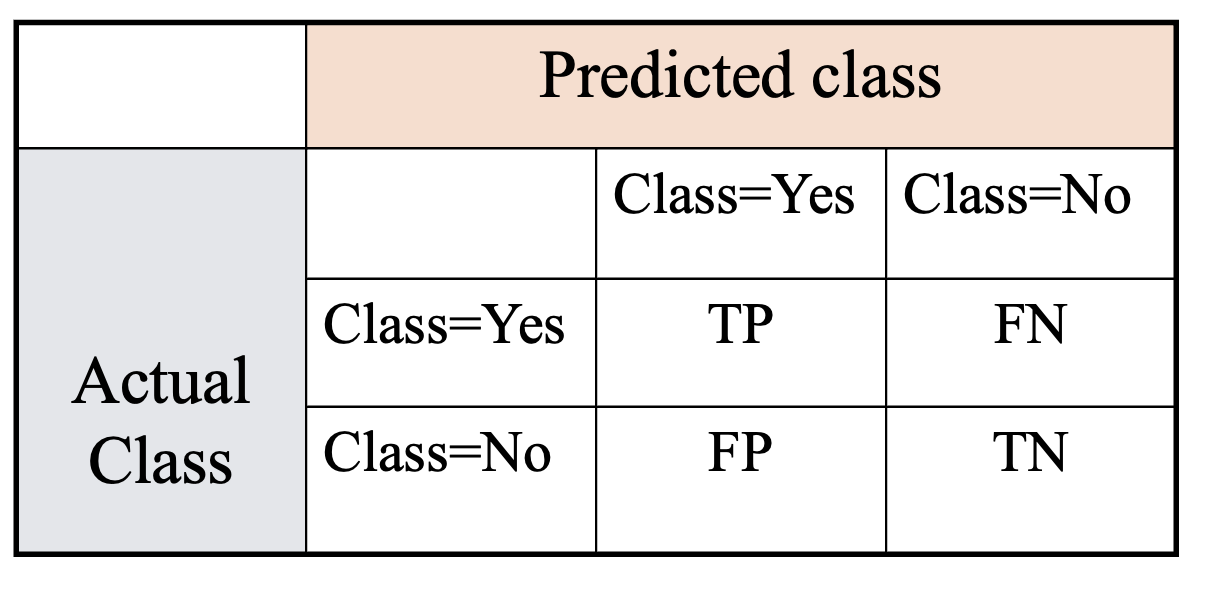
2.评估金融分类模型结果的指标——混淆矩阵
如下表所示,是一个混淆矩阵的基本结构,它通过四种计数总结了分类器准确或者错误预测的样本的数量:TP真正,ture positive,表示的被分类模型正确预测的正样本数;FN假负,false negative,表示的是被分类模型错误预测成负类的正样本数;FP假正,false positive,表示的是被分类模型错误预测成正类的负样本数;TN真负,ture negative,表示的被分类模型正确预测的负样本数。
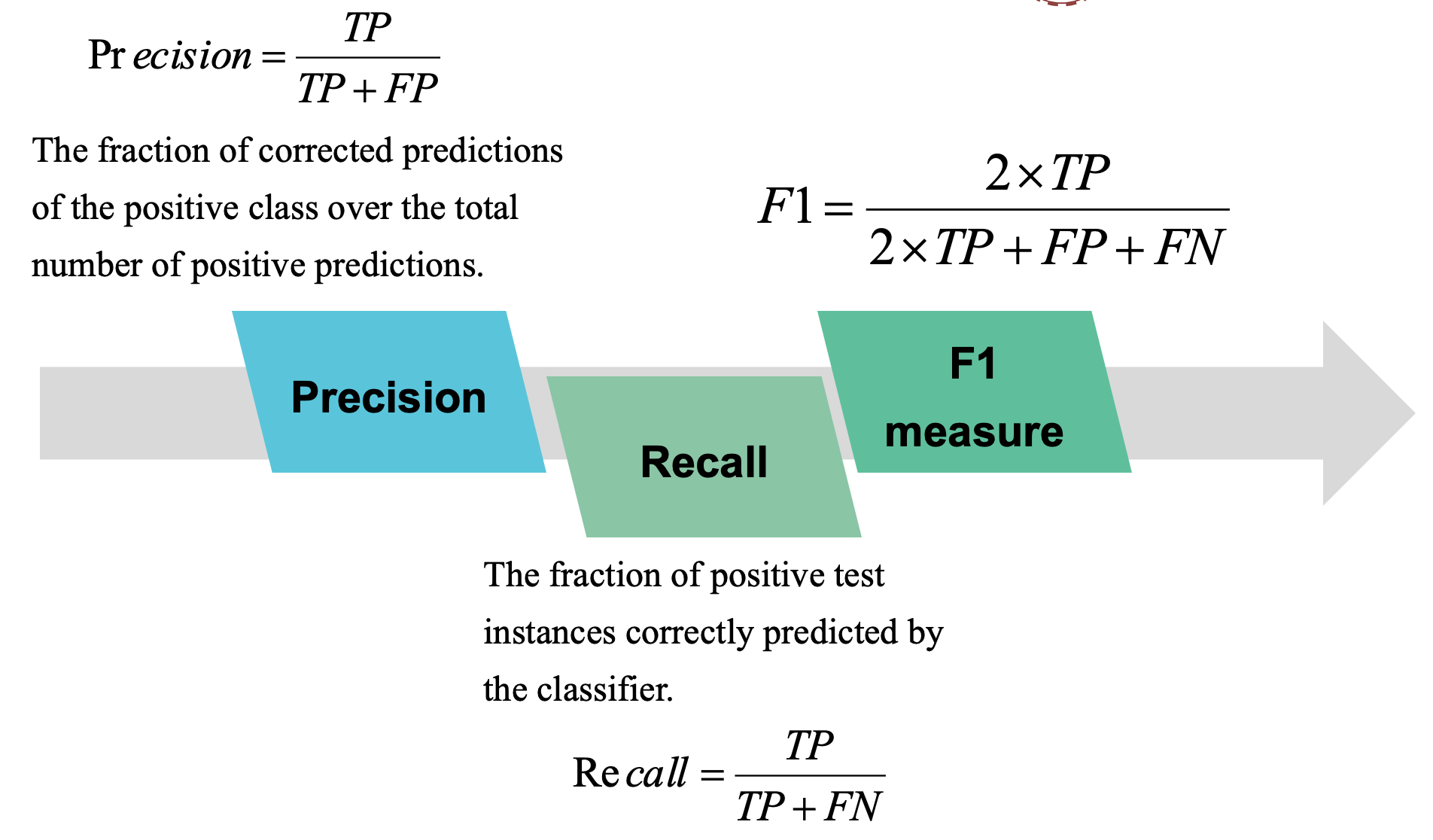
3.评估金融分类模型结果的指标——精度,召回率,F-度量
精度表示分类器预测为正类的样本中实际为正类的样本所占的比例。
召回率表示为分类器能够正确预测的正样本所占的比例。
F-度量是由精度和召回率合成出来的指标。