Methods for expressing attribute test conditions 属性测试条件划分方法
上一节
下一节
主要知识点:
属性测试条件的表达方法
属性测试条件的表达一方面依赖于属性的类型,即针对标称、序数、区间和比率属性,表达方式具有相异性;另一方面依赖于划分路数的选择,即选择二元划分产生两条分枝,或者选择多路划分产生多条分枝。
标称属性:依据属性值的个数,选择二元或者多路划分,产生不同组合
序数属性:依据属性值的个数,选择二元或者多路划分,产生不同组合
连续属性:选择多路划分,可以使用离散化的策略进行划分,但需保证划分后的属性值范围互斥,且覆盖了包含数据集里的最小值和最大值之间的整个属性值范围;选择二元划分,可以选择最小和最大属性值之间的任何可能值用来构造比较测试。
2.如何决定最优划分?
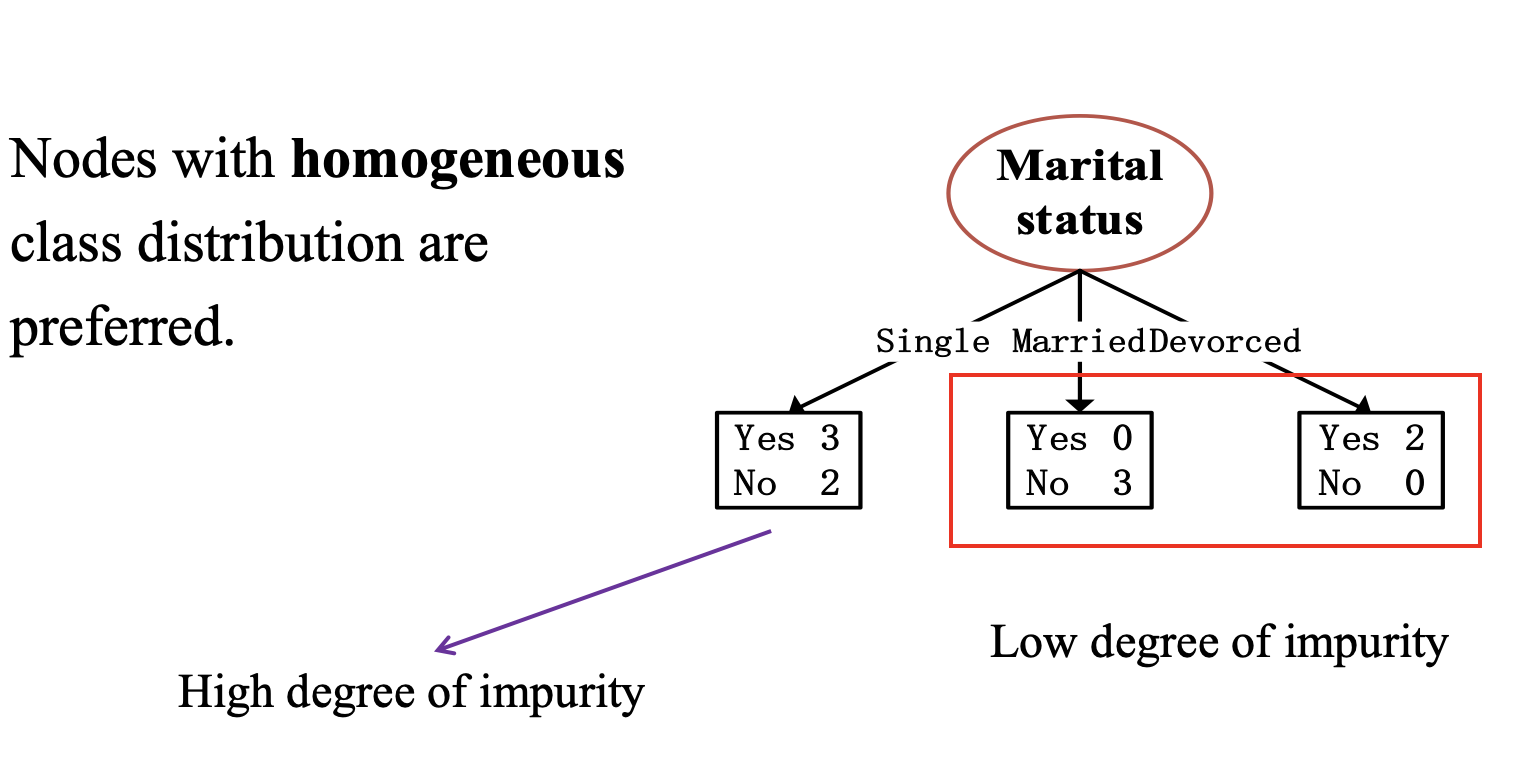
Hunt算法中,理想情况下,分裂准则期待每个分支上的输出分区都尽可能的“纯”,即所有数据对象都属于同一个类别,即优先考虑将结点划分为更同质化的属性测试条件。如图所示,以属性Marital Status为例,多路划分中,最左边分枝产生的结果为3个类别为Yes的数据对象和2个类别为No的数据对象,纯度较低,杂质度较高;中间分枝产生的结果为0个类别为Yes的数据对象和3个类别为No的数据对象,纯度高,杂质度低;最右边分枝产生的结果为2个类别为Yes的数据对象和0个类别为No的数据对象,纯度高,杂质度低。