主要知识点:
1. 决策树的结构
决策树是一种非参数的有监督学习方法,决策树分类器具有明显的树状结构,如下图所示,其主要包括:
根结点,即决策树最顶层结点。图里面是Gender属性,可以发现根结点的属性是没有传入连接,但是包含零个或者多个传出连接。
内部结点,如图中Marital Status和Income,此类结点的特点是每个结点只有一个传入连接,但是拥有两个或者更多的传出连接。
叶结点,又被称为终端结点,一般以类标签表示,如图中的Yes和No结点,可以较为清楚的发现该类结点只有一个传入连接,并且没有传出连接
根结点和内部结点都是非终端结点,非终端结点包含使用单个属性定义的属性测试条件,属性测试条件的每个可能结果都与该结点的一个子结点关联。以内部结点Income为例,该结点以Income这个属性来定义属性测试条件,该条件具有两个结果,<6000和>=6000,产生两个子结点。
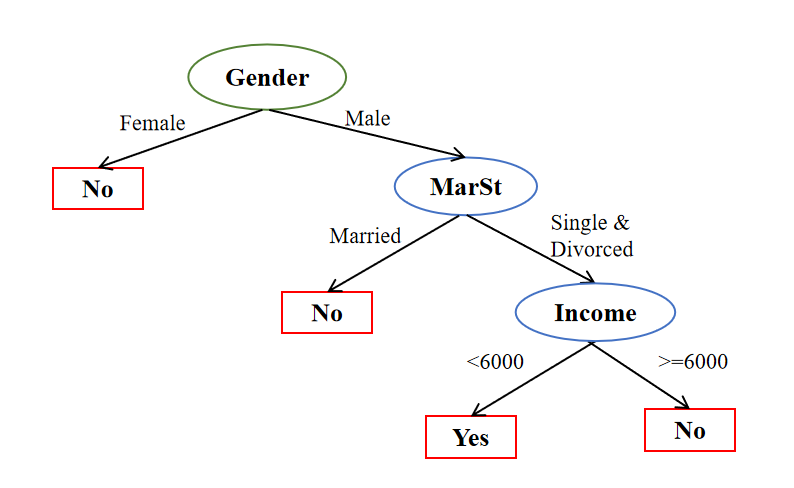
2. 结合具体金融场景,决策树的构建过程(hunt算法)
Hunt算法是许多经典决策树算法如CART,ID3和C4.5等算法的基础,在Hunt算法中,决策树是以递归的方式生长的(递归就是在程序运行的过程中调用自己,把一个大型复杂的问题层层转化为一个原问题相似的规模较小的问题来求解的过程)。结合如图所示的金融决策树,基于hunt算法将决策树的构造过程列示如下:

首先,该训练集包含10个数据对象,检查该训练集的数据对象是否为统一类别标签,可以发现该训练集包含3个类别为Yes的类别和7个类别为No的类别,因此不符合叶结点的要求,需要往下进行划分。假如此时选择Gender属性进行划分,运用属性测试条件Male和Female产生两个新的子结点,可以发现Gender=Female属性测试条件的子结点只包含4个类别为No的数据对象,没有类别为Yes的数据对象,因此该子结点变为叶结点,标签为No。另外一边Gender=Male属性测试条件的子结点包含3个类别为No的数据对象,3个类别为Yes的数据对象,确定为内部结点,需要进一步往下划分。假设此时选择Marital Status属性继续往下划分,运用属性测试条件Married和Single&Divorced产生两个新的子结点,可以发现Marital Status=Married属性测试条件的子结点只包含2个类别为No的数据对象,没有类别为Yes的数据对象,因此该子结点变为叶结点,标签为No。另外一边Marital Status=Single&Divorced属性测试条件的子结点包含1个类别为No的数据对象,3个类别为Yes的数据对象,确定为内部结点,需要进一步往下划分。假设此时选择Income属性继续往下划分,运用属性测试条件<6000和>=6000产生两个新的子结点,可以发现Income<6000属性测试条件的子结点只包含3个类别为Yes的数据对象,没有类别为No的数据对象,因此该子结点变为叶结点,标签为Yes。另外一边Income>=6000属性测试条件的子结点只包含1个类别为No的数据对象,没有类别为Yes的数据对象,因此该子结点变为叶结点,标签为No。此时所有数据对象划分完毕,产生了最终决策树。
3.决策树构建过程中的主要问题及解决思路
非终端结点是如何选择的?可以拆分为两个子问题:如何确定属性测试条件,以及如何度量属性测试条件划分后的结果好坏(即纯度)?解决思路:确定纯度度量指标。
决策树什么时候能够终止划分?解决思路:第一种即与结点相关所有的数据对象具有相同的类别标签或者具有相同的属性值,可以终止划分;第二种即提前终止,此时即使叶结点包含多个类别的数据对象,也停止划分。

