
除了布尔逻辑检索之外,计算机检索中还经常用到截词检索、位置检索、限制检索、加权检索和聚类检索技术。
2.2.1 截词检索
截词检索在西文检索系统中较常用,即检索者将检索词在他认为较合适的地方加上截词符断开,利用词的一个局部进行检索。截词符可用来屏蔽未输入字符,解决由于派生词列举不全而造成的漏检,提高了检索效率。根据截词的位置,截词检索可分为前截断、中截断和后截断三种。
1.前截断
前截断即后方一致,就是将截词符放在检索词需截词的前边,表示前边截断了一些字符,只要检索和截词符后面一致的信息。例如,输入“?ware”,就可以查找到“software”“hardware”等词根为“ware”的信息。
2.中截断
中截断即前后一致,也就是将截词符放在检索词需截词的中间,表示中间截断了一些字符,要求检索和截词符前后一致的信息。例如,输入“colo?r”,就可以查找到“colour”“color”等信息。
3.后截断
后截断即前方一致,就是将截词符放在检索词需截词的后边,表示后边截断了一些字符,只要检索和截词符前面一致的信息。例如,输入“com?”,就可以查找到“computer”“computerized”等以“com”开头的词。
不同的检索系统对于截词符有不同的规定,有的用“?”,也有的用“*”“!”“#”“$”等。
2.2.2位置检索
位置检索即通过位置算符指明检索词在记录中的位置关系,限定检索词之间的间隔距离或前后关系,可以使检索结果更准确。常见的用位置算符来进行限制检索的情况主要有以下几种。
1.(W)与(nW)
W是With的缩写。(W)算符表示在此算符两侧的检索词必须按输入时的前后顺序排列,且两词之间除了可以用一个空格、一个标点符号或一个连词符之外,不得有任何其他的单词或字母。(nW)由(W)引申而来,表示在两个检索词之间最多可以插入n个单元词,但两个检索词的位置关系不可颠倒。
例如,输入“computer(1W)retrieval”可检索到含有“computer information retrieval”“computer document retrieval”等的信息。
2.(N)与(nN)
N是Near的缩写。(N)算符表示在此算符两侧的检索词必须紧密相连,但词序可颠倒。(nN)由(N)引申而来,表示两个检索词之间最多可以插入n个单元词。
例如,输入information(N)retrieval可检索到含有"retrieval information""informationretrieval”等的信息。
3.(F)
F是Field的缩写。(F)表示在此运算符两侧的检索词必须出现在同一字段中,如出现在题名字段、主题字段、文摘字段中等,两词的前后顺序不限,两词之间允许插入其他的词或者字符的个数也不限。
例如,输入“computer(F)control”可检索到在某一字段中(题名字段或主题字段或文摘字段等)同时包含“computer”和“control”的文献信息记录。
4.(L)
L是Link的缩写。(L)表示在此运算符两侧的检索词必须同在叙词字段(DE)中出现,而且两词之间具有词表规定的等级关系(从属关系),(L)前面的词为主标题词,(L)后面的词为副标题词,(L)用来连接主标题词和副标题词。(L)运算符只适用于有正式词表而且词表中的词具有从属关系的数据库。
例如,输入“television(L)high definition”,命中记录的规范词字段(DE)中出现的匹配词是“television high definition”。其中,“high definition”是“television”的下位词。
5.(S)
S是Subfield的缩写。(S)表示在此运算符两侧的检索词必须出现在同一个子字段中(子字段是指字段中的一部分,通常由数据库确定,可以是一个句子、一个段落),两词在同一子字段中的相对次序不限,两词中间插入其他词的数量也不限。
例如,输入“robot(W)control(S)print",可以检索出子字段中同时含有"robot control”和“print”的文献信息记录。
不同的检索系统有不同的位置运算符。目前,Dialog联机检索系统是该功能最为详尽的检索系统。
上述位置运算符可以同时应用于同一个检索式中,检索系统按从左到右的顺序执行运算。如果在一个检索式中既有位置算符,又有布尔逻辑算符,系统优先执行位置算符。
2.2.3限制检索
限制检索泛指检索系统中提供的缩小或约束检索结果的检索方式,主要有字段限制检索、范围限制检索等。
1.字段限制检索
字段限制检索是指限定检索词在数据库记录中的一个或几个字段范围内查找的一种检索方法。在检索系统中,数据库设置的可供检索的字段通常有两种:表达文献主题内容特征的基本字段和表达文献外部特征的辅助字段。不同的检索系统设定的字段会有不同,常见的字段及代码如表2.1所示。
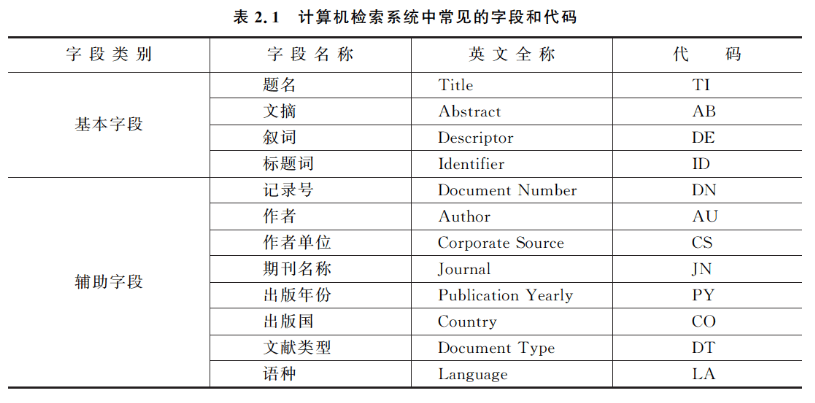
表2.1将常见字段分成基本字段和辅助字段,其中,基本字段用来表达信息的内容特征,检索字段符用后缀方式,即/TI、/AB、/DE、/ID等。例如,“pattern/AB”表示要检索的是文摘中含有“pattern”的所有信息。辅助字段用来表达信息的形式特征,检索字段符用前缀方式,即AU=、CS=、JN=、LA=等。例如,“AU=Levis”表示要检索的是作者是“Levis”的所有信息。
2.范围限制检索
除上述限制检索外,计算机检索系统一般还提供了范围限制检索功能,用以对数字信息进行限制检索。常用的检索符如下。
(1):或一:包含范围。
(2)>:大于。
(3)<:小于。
(4)=:等于。
(5)>=:大于或等于。
(6)<=:小于或等于。
3.使用高级检索、二次检索
现在的一些检索系统一般具有高级检索(又称“Advanced”或“Expert”)功能,它比简单检索功能更完备、精确,不仅可以实现多字段、多检索式的逻辑组合检索,而且对检索的限定更具体、全面,基于字符图形界面的高级检索系统,十分直观,易于操作。另外,可使用二次检索,在当前检索结果中进一步检索。
2.2.4加权检索
加权检索是某些检索系统中提供的一种定量检索技术。加权检索同布尔检索、截词检索等一样,也是文献检索的一个基本检索手段,但与它们不同的是,加权检索的侧重点不在于判定检索词或字符串是否在数据库中存在、与别的检索词或字符串是什么关系,而在于判定检索词或字符串在满足检索逻辑后对文献命中与否的影响程度。加权检索的基本方法是:在每个提问词后面给定一个数值表示其重要程度,这个数值称为权,在检索时,先查找这些检索词在数据库记录中是否存在,然后计算存在的检索词的权值总和。如果权值之和达到或超过预先给定的阈值,该记录即为命中记录。
运用加权检索可以命中核心概念文献,因此它是一种缩小检索范围、提高检索准确率的有效方法。但并不是所有系统都能提供加权检索这种检索技术,而能提供加权检索的系统,对权的定义、加权方式、权值计算和检索结果的判定等方面,又有不同的技术规范。
2.2.5聚类检索
聚类检索是在文献进行自动标引的基础上,构造文献的形式化表示——文献向量,然后通过一定的聚类方法,计算出文献与文献之间的相似度,并把相似度较高的文献集中在一起,形成一个个的文献类的检索技术。根据不同的聚类水平的要求,可以形成不同聚类层次的类目体系。在这样的类目体系中,主题相近、内容相关的文献便聚在一起,而相异的则被区分开来。聚类检索的出现,为文献检索尤其是计算机化的信息检索开辟了一个新的天地。文献自动聚类检索系统能够兼有主题检索系统和分类检索系统的优点,同时具备族性检索和特性检索的功能。因此,这种检索方式将有可能在未来的文献检索中大有用武之地。几乎所有的计算机检索系统都有布尔逻辑运算、截词检索和限制检索,而不同的检索系统又会有一些特殊的检索技术和功能。

