
6.6.1探索式数据分析
统计学家最早意识到数据的价值,提出一系列数据分析方法用于理解数据特性。数据分析不仅有助于用户选择正确的预处理和处理工具,还可以提高用户识别复杂数据特征的能力。探索式数据分析是统计学和数据分析结合的产物。
6.6.2联机分析处理
联机分析处理(OLAP)是一种交互式探索大规模多维数据集的方法。关系型数据库将数据表示为表格中的行数据,而联机分析处理则关注统计学意义上的多维数组。将表单数据转换为多维数组需要两个步骤。首先,确定作为多维数组索引项的属性集合,以及作为多维数组数据项的属性。作为索引项的属性必须具有离散值,而对应数据项的属性通常是一个数值。然后,根据确定的索引项生成多维数组表示。联机分析处理的核心表达是多维数据模型。这种多维数据模型又可表达为数据立方,相当于多维数组。数据立方是数据的一个容许各种聚合操作的多维表示。例如,某数据集记录了一组产品在不同日期、不同地点的销售情况,这个数据集可看成三维数组,数组的每个单元记录的是销售数量。针对这个数据立方,可以实行三种二维聚合、三种一维聚合、一种零维聚合。数据立方可用于记录包含数十个维度、数百万数据项的数据集,并允许在其基础上构建维度的层次结构。通过对数据立方不同维度的聚合、检索和数值计算等操作,可完成对数据集不同角度的理解。由于数据立方的高维性和大尺度,联机分析处理的挑战是设计高度交互性的方法。一种方案是预计算并存储不同层级的聚合值,以便减小数据尺度;另一种方案是从系统的可用性出发,将任一时刻的处理对象限制于部分数据维度,从而减少处理的数据内容。联机分析处理被广泛看成一种支持策略分析和决策制定过程的方法,与数据仓库、数据挖掘和数据可视化的目标有很强的相关性。它的基本操作分为两类(见图6-6)。
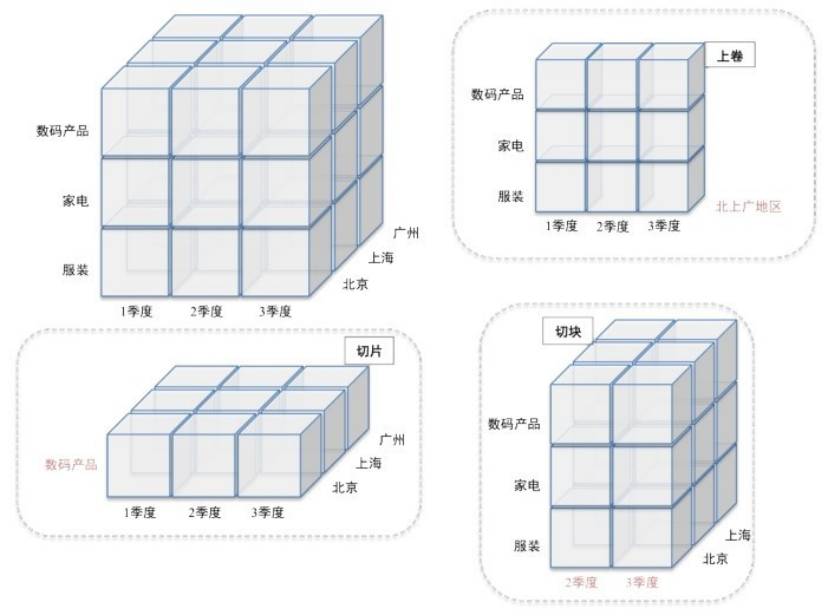
图6-6数据立方体操作的概念性可视化表示,包括:上卷、切片和切块。
①切片和切块——切片指从数据立方中选择在一个或多个维度上具有给定的属性值的数据项。切块指从数据立方中选择属性值位于某个给定范围的数据子集。两个操作都等价于在整个数组中选取子集。
②汇总和钻取——属性值通常具有某种层次结构。例如,日期包括年、月、星期等信息;位置包括洲、国家、省和城市等;产品可以分为多层子类。这些类别通常嵌套成一个树状或网状结构。因此,可以通过向上汇总或向下钻取的方法获取数据在不同层次属性的数据值。
联机分析处理是交互式统计分析的高级形式。面向复杂数据,联机分析处理方法的发展趋势是融合数据可视化与数据挖掘方法,转变为数据的在线可视分析方法。
Polaris是由斯坦福大学开发的用于分析多维数据立方的可视化工具,它针对基于表格的数据进行可视化及分析,可以认为是对表格数据(诸如电子表格数据、关系型数据库数据等)的一种可视化扩展。它继承了经典的数据表单的基本思想,在表格各单元中使用嵌入式的可视化元素替代数值和文本。当前系统支持各类统计可视化方法,如柱状图、饼图、甘特图、趋势线等。Polaris的商业版本Tableau已经取得极大的成功。
6.6.3数据挖掘
数据挖掘指设计特定算法,从大量的数据集中去探索发现知识或者模式的理论和方法,是知识工程学科中知识发现的关键步骤。面向不同的数据类型可以设计特定的数据挖掘方法,如数值型数据、文本数据、关系型数据、流数据、网页数据和多媒体数据等。
数据挖掘的定义有多种。直观的定义是通过自动或半自动的方法探索与分析数据,从大量的、不完全的、有噪声的、模糊的、随机的数据中提取隐含在其中的、人们事先不知道的、潜在有用的信息和知识的过程。数据挖掘不是数据查询或网页搜索,它融合了统计、数据库、人工智能、模式识别和机器学习理论中的思路,特别关注异常数据、高维数据、异构和异地数据的处理等挑战性问题。
基本的数据挖掘任务分为两类:基于某些变量预测其他变量的未来值,即预测性方法;以人类可解释的模式描述数据。在预测性方法中,对数据进行分析的结论可构建全局模型,并且将这种全局模型应用于观察值可预测目标属性的值。而描述性任务的目标是使用能反映隐含关系和特征的局部模式,以对数据进行总结。
直观地说,数据挖掘指从大量数据中识别有效的、新颖的、潜在有用的、最终可理解的规律和知识。而可视化将数据以形象直观的方式展现,让用户以视觉理解的方式获取数据中蕴含的信息。两者的对比见图6-7。
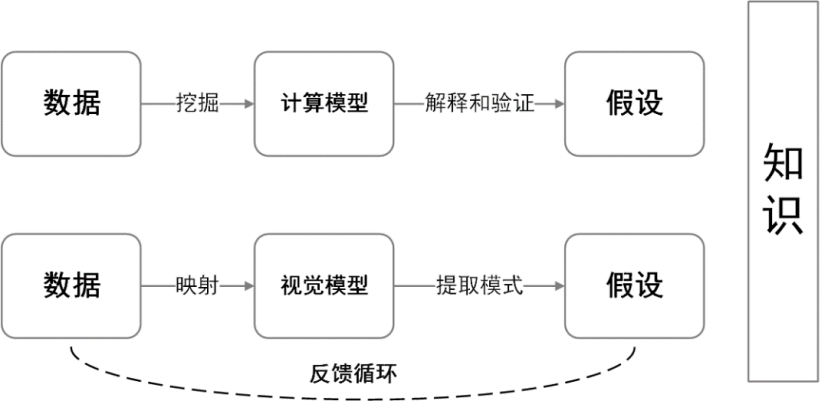
图6-7数据挖掘与信息可视化的流程对比
(1)分类(预测性方法)
给定一组数据记录,每个记录包含一组标注其类别的属性。分类算法需要从训练集中获得一个关于类别和其他属性值之间关系的模型,继而在测试集上应用该模型,确定模型的精度。通常,一个待处理的数据集可分为训练集和测试集两个部分,前者用于构建模型,后者用于验证。图6-8展示了利用决策树进行数据分类的过程,客户经理可以使用决策树对含有多维属性的用户数据进行分类,用来筛选出用户群中的高端用户。
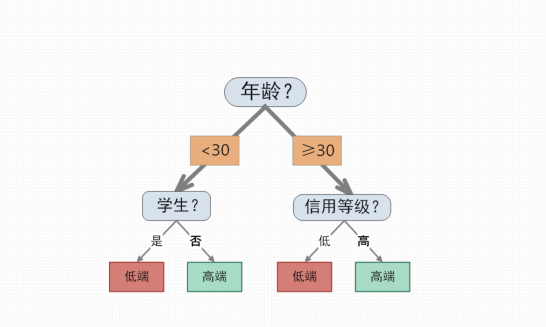
图6-8利用决策树进行数据分类的过程
(2)聚类(描述性方法)
给定一组数据点以及彼此之间的相似度,将这些数据点分成多个类别,满足:位于同一类的数据点彼此之间的相似度大于与其他类的数据点的相似度。聚类技术的要点是,在划分对象时不仅要考虑对象之间的距离,还要求划分出的类具有某种内涵描述,从而避免传统技术的某些片面性。
(3)概念描述(描述性方法)
概念描述即对某类数据对象的内在特征进行描述并概括。概念描述分为特征性描述和区别性描述,特征性描述描述的是这一类对象所具有的相同的特征,区别性描述则关注不同类对象之间存在的区别。生成一个类的特征性描述只涉及该类对象中所有对象的共性,生成区别性描述的方法很多,如决策树方法、遗传算法等。图6-9展示了分类、聚类和概念描述等技术的区别。
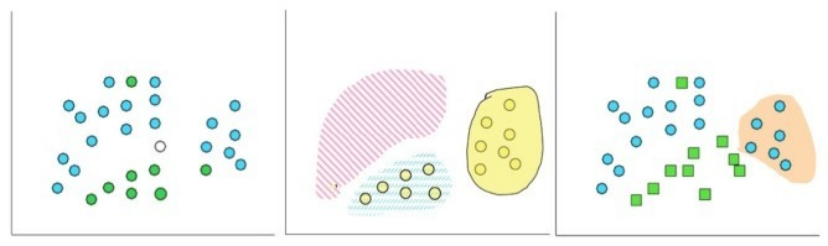
图6-9数据挖掘的主要操作示意图:分类、聚类和概念描述
(4)关联规则挖掘(描述性方法)
关联规则描述在一个数据集中一个数据与其他数据之间的相互依存性和关联性。数据关联是数据库中存在的一类重要的可被发现的知识。若两个或多个变量的属性值之间存在某种规律性,就称为关联。关联可分为简单关联、时序关联、因果关联。如果两个或多个数据之间存在关联关系,那么其中一个数据可通过其他数据预测。关联规则挖掘则是从事务、关系数据中的项集合对象中发现频繁模式、关联规则、相关性或因果结构。
(5)序列模式挖掘(描述性方法)
针对具有时间或顺序上的关联性的时序数据集,序列模式挖掘就是挖掘相对时间或其他模式出现频率高的模式。序列模式挖掘主要针对符号模式,而数字曲线模式属于统计时序分析中的趋势分析和预测范畴。
(6)回归(预测性方法)
回归在统计学上定义为:研究一个随机变量对另一组变量的相依关系的统计分析方法。其中,线性回归是利用数理统计中的回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。此外,当自变量为非随机变量、因变量为随机变量时,分析它们的关系称为回归分析;当两者都是随机变量时,称为相关分析。
(7)偏差检测(预测性方法)
大型数据集中常有异常或离群值,统称为偏差。偏差包含潜在的知识,如分类中的反常实例、不满足规则的特例、观测结果与模型预测值的偏差、量值随时间的变化等。偏差检测的基本方法是,寻找观测结果与参照值之间有意义的差别。偏差预测的应用广泛,如信用卡诈骗监测、网络入侵检测等。偏差检验的基本方法就是寻找观察结果与参照值之间的差别。

