
6.1.1数据基础
(1)数据分类
数据的分类和信息与知识的分类相关。从关系模型的角度讲,数据可被分为实体和关系两部分。实体是被可视化的对象;关系定义了实体与其他实体之间关系的结构和模式。关系可被显式地定义,也可在可视化过程中逐步挖掘。实体或关系可以配备属性,例如,一个苹果的颜色可以看作它的属性。实体、关系和属性在数据库设计中被广泛使用,形成关系型数据库的基础。实体关系模型能描述数据之间的结构,但不考虑基于实体、关系和属性的操作。根据不同的数字类型,在可视化中可使用不同的图形实现。
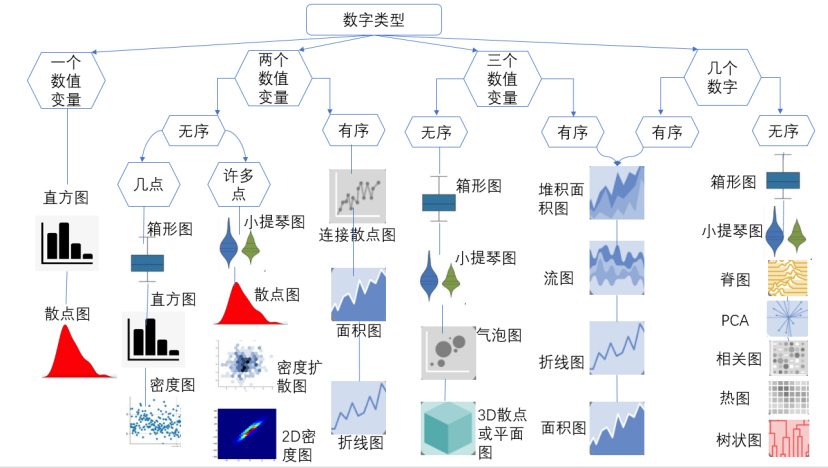
图6-1数据分类
常规的数据操作包括:数值计算,实体的变换。数据属性可分为离散属性和连续属性。离散属性的取值来自有限或可数的集合,连续属性则对应于实数域。针对这些基本数据类型的交互方法主要有:概括、缩放、过滤、查看细节、关联、查看历史和提取等。这些基本任务构成了可视语言设计的基础。
(2)数据相似度
相似度是衡量多个数据对象之间相似的数值,通常位于0和1之间。与之对应的测度是相异度,其下限是0,上限与数据集有关,可能超过1。邻近度是相似度和相异度的统一描述。计算相似度有很多种方法,一些常用的距离和相似度定义有:
①欧几里得距离。
②明科夫斯基距离。
③余弦距离。
④Jaccard相似度。
如果数据对象的属性具有多种类型,则可为每个属性计算相似度,再进行加权平均。在基于密度的数据聚类时,需要衡量数据的密度,通常定义有三类:
①欧几里得密度。
②概率密度。
③基于图结构的密度。
6.1.2数据特征
数据是一种客观存在,是关于事物的事实描述,可通过测量、记录、发现等方式去获得。数据具有五个特征,分别是无限性、原始性、易腐性、易复制性和非均质性。
(1)无限性。与实物不同,数据不会因使用而耗尽,反而会随着使用而不断地产生新的数据。“数据将成为最基本的客观产物,无论做什么,我们都在产生数据”。根据DASAR&T《2016-2045年新兴科技趋势》,全球新产生的数据量大约每两年翻一番,因此数据大爆炸是未来发展的必然趋势。
(2)原始性。数据是原始的,其本身并没有意义,只有对它进行处理分析得到对人们有价值的信息之后才拥有了意义。信息是数据提炼后的产物;信息经人脑加工后形成知识,知识具有主观性;数据、信息和知识是历史的,而智慧是关于未来的,是人们运用知识做出决策和判断的能力。
(3)易腐性。数据是一种易腐品,会随着时间的流逝而迅速贬值。根据IBM(2015)数据,60%的非结构化数据在几毫秒内就失去了真正的价值。这表明数据的价值很大程度体现在时效性上,超50%的数据在产生的瞬间就失去了价值,我们将这种现象称作为“一秒钟定律”。能得到分析处理并产生实际效用的数据则更少,据统计,全球90%的数据从未得到分析和使用。2020年被创建或复制的数据中,只有不到2%被保存并保留到2021年。
(4)易复制性。数据可以近乎零成本地进行快速复制,既可以多次循环使用,也可以多人同时使用,不同人之间在使用上不存在直接的利益冲突。易复制性导致数据具有一定程度的非竞争性和非排他性,但需要明确的是数据并不是公共品,它分为公共数据、企业数据和个人数据。
(5)非均质性。均质性在生活中普遍存在,例如出厂的商品、油电气等能源。而数据是非均质的,因为同一份数据对不同人的价值完全不同。

