
2.5.1数据可视化流程简介
数据可视化不是简单的视觉映射,而是一个以数据流向为主线的一个完整流程,主要包括数据采集、数据处理和变换、可视化映射、用户交互和用户感知。一个完整的可视化过程,可以看成数据流经过一系列处理模块并得到转化的过程,用户通过可视化交互从可视化映射后的结果中获取知识和灵感。通用的数据可视化流程模型如图2-31所示。
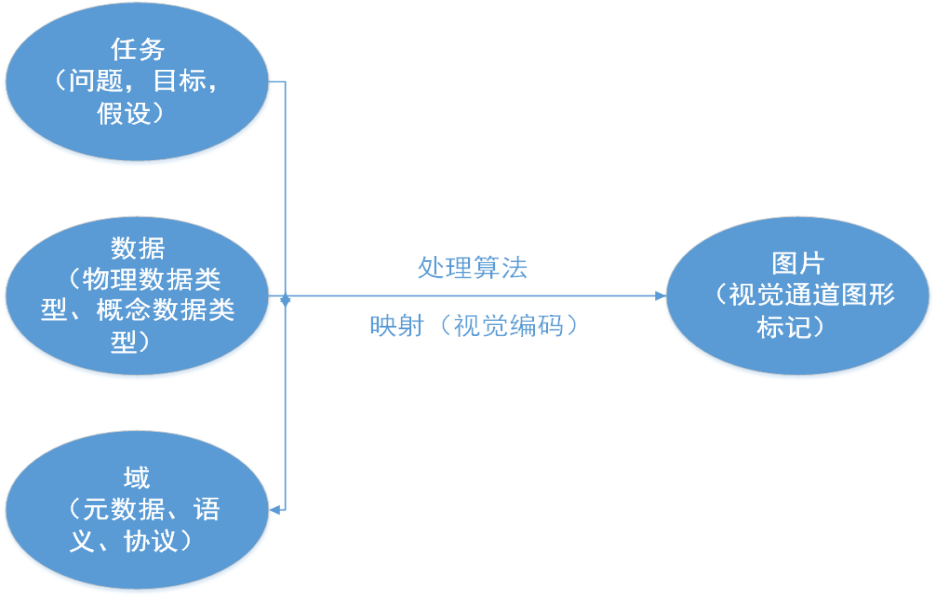
图2-31通用的数据可视化流程模型
2.5.2可视化流程模型
(1)线性模型
基于1990年RobertB.Haber和DavidA.McNabb提出的线性模型,我们可以绘制可视化线性流程模型,如图2-32所示。
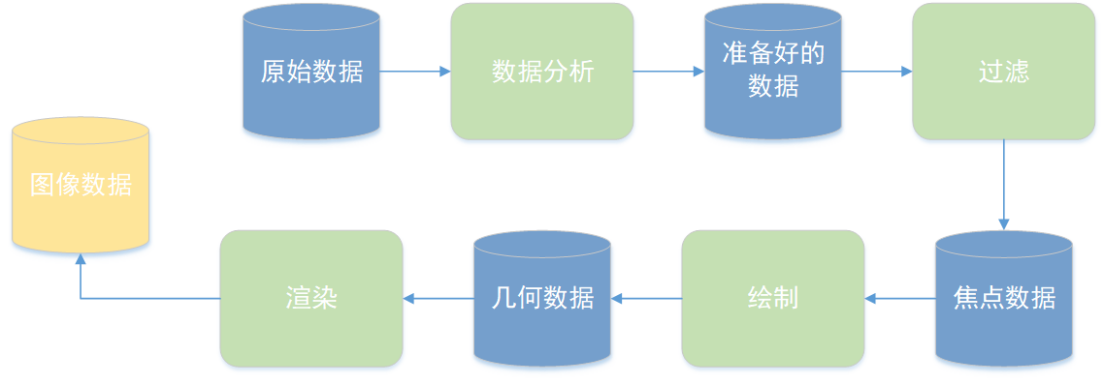
图2-32可视化线性流程模型
这个处理模型非常先进,整个流程是线性的。它把数据分成五大阶段,分别要经历四个流程,每个过程的输入是上一个过程的输出。从图上看非常直观,很好理解。
(2)嵌套模型
另一种模型是嵌套模型,如图2-33所示。

图2-33嵌套模型
嵌套模型的上半部分基本上就是我们之前说的分析、处理两步,下半部分是对可视化结果的各类验证。本质上就是一个验证加迭代的过程。
(3)循环模型
我们知道很多事都不是一蹴而就的,需要不断迭代,所以有人提出了循环模型。循环模型的两张图其实都是把线性模型首尾连起来,如图2-34所示。
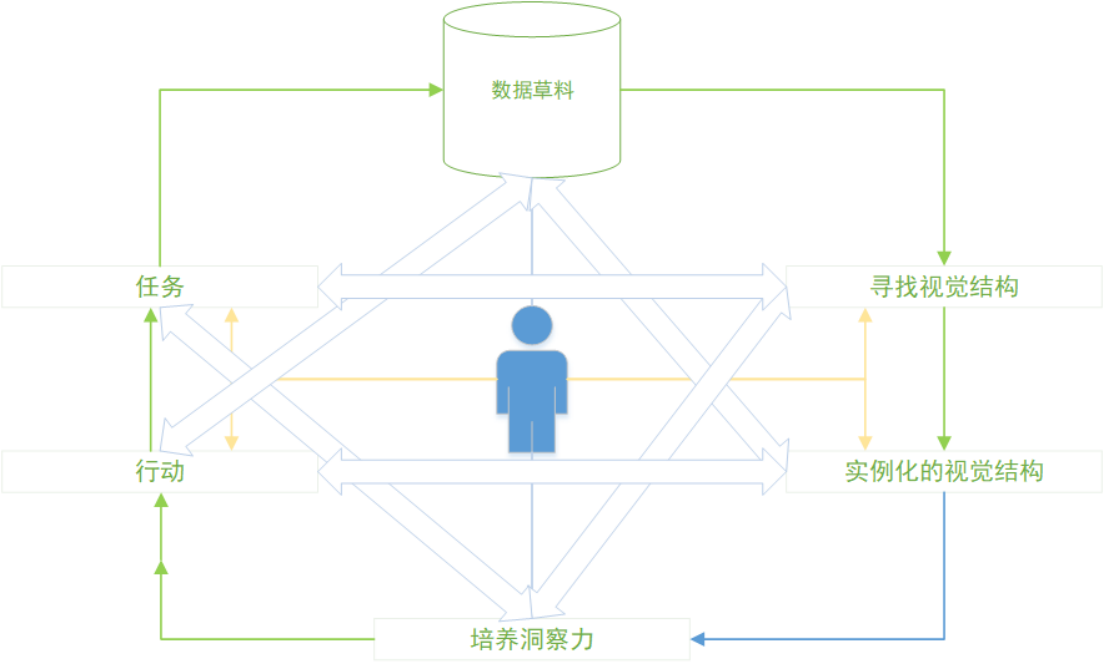
图2-34循环模型
(4)目前应用最广的模型
对比之前的线性模型,其实也很类似,不过其在最后加入了用户交互的部分,且让每个步骤都变成了循环的。这是目前应用最广的可视化流程模型,后继几乎所有著名的信息可视化系统和工具都支持、兼容这个模型。如图2-35所示。
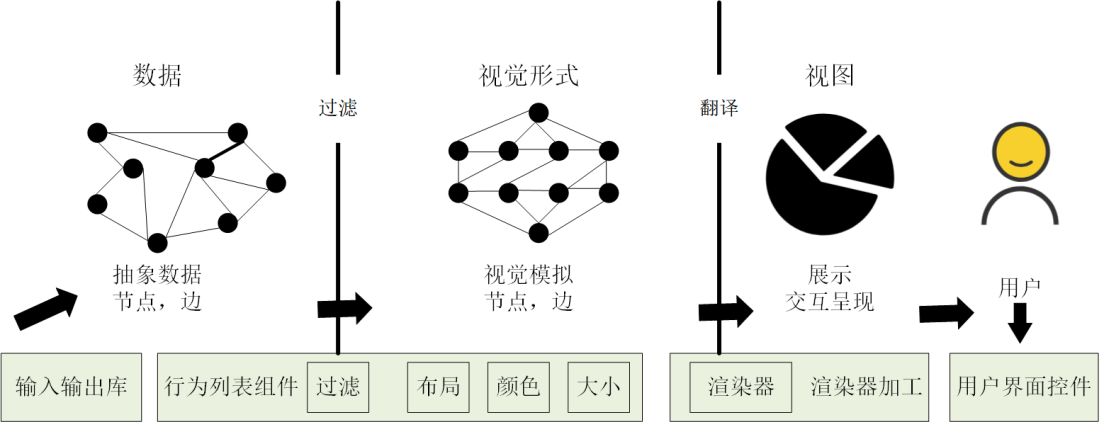
图2-35目前应用最广的模型
2.5.3数据可视化流程的实施步骤
可视化整体可分为三步:分析-处理-生成。在这里只做简要介绍,具体实施会在后文详细介绍。
(1)分析
进行一个可视化任务时,我们首当其冲的当然是要分析,分析又分为三部分:任务、数据、领域。
首先,我们要分析我们这次可视化的出发点和目标是什么。我们遇到了什么问题、要展示什么信息、最后想得出什么结论、验证什么假说等等。数据承载的信息多种多样,不同的展示方式会使侧重点有天壤之别。只有想清楚以上问题,才能确定我们要过滤什么数据、用什么算法处理数据、用什么视觉通道编码等等。
其次,我们要分析我们的数据,这是至关重要的一步。因为每次可视化任务拿到的数据都是不同的,数据类型、数据结构均有变化,数据的维度也可能成倍增加。抽象的数据类型如何对应现实中的概念,不同的数据类型如何进行视觉编码,这些我们在下一篇数据模型中进行介绍。
最后,我们针对不同的领域,也要进行相应的分析。毕竟术业有专攻,可视化的侧重点要跟着领域做出相应的变化。
(2)处理
处理可以分为两部分:对数据的处理和对视觉编码的处理。
①数据处理
在可视化之前我们要对数据进行数据清洗、数据规范、数据分析。
数据清洗和规范是必不可少的步骤。首先把脏数据、敏感数据过滤掉,其次再剔除和我们目标无关的冗余数据,最后调整数据结构到我们系统能接受的方式。
数据分析中最简单的方法当然是一些基本的统计方法,如求和、中值、方差、期望等等;复杂的方法有数据挖掘种的各种算法,这是又一个领域了,在此不赘述。
最后的可视化结果中我们肯定不可能把所有的数据统统展示出来,于是又涉及到包括标准化(归一化)、采样、离散化、降维、聚类等数据处理的方法,这些概念之后可以单独写篇文章来介绍。
②设计视觉编码
视觉编码的设计是指如何使用位置、尺寸、灰度值、纹理、色彩、方向、形状等视觉通道,以映射我们要展示的每个数据维度。在视觉编码2.3小节有所提及。
(3)生成
这个阶段基本上就是把之前的分析和设计付诸实践,在制作或写代码过程中,再不断调整需求、不断地迭代(有可能要重复前两步),最后产出我们想要的结果。

