本课程必备软件资源:
一、八爪鱼采集器
下载地址:
https://www.bazhuayu.com/download
二、 python解释器(已有的无需重复安装)
下载地址:
https://www.python.org/downloads/
三、安装PyCharm Community Edition 版本
下载地址:
https://www.jetbrains.com.cn/pycharm/download

安装步骤:
如何用pycharm新建工程?
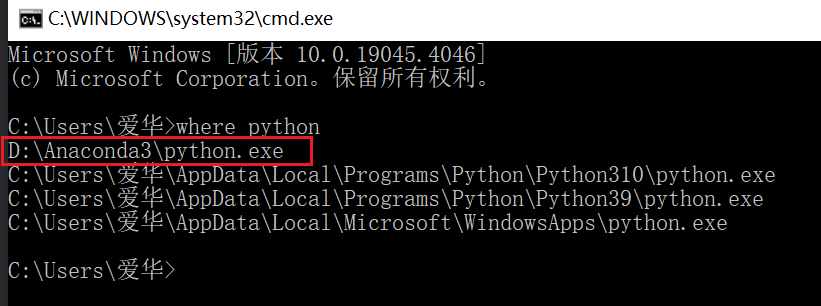
1,打开cmd命令提示符窗口,运行where python
找到python解释器所在位置。
提示:如果安装有anaconda3,则选择anaconda3下面的解释器。没有安装,则随机选择一个python3.7以上的python解释器即可。记住这个路径。
2,打开pycharm,新建工程。
选择:使用已配置好的解释器,选择:add interpreter,添加解释器。
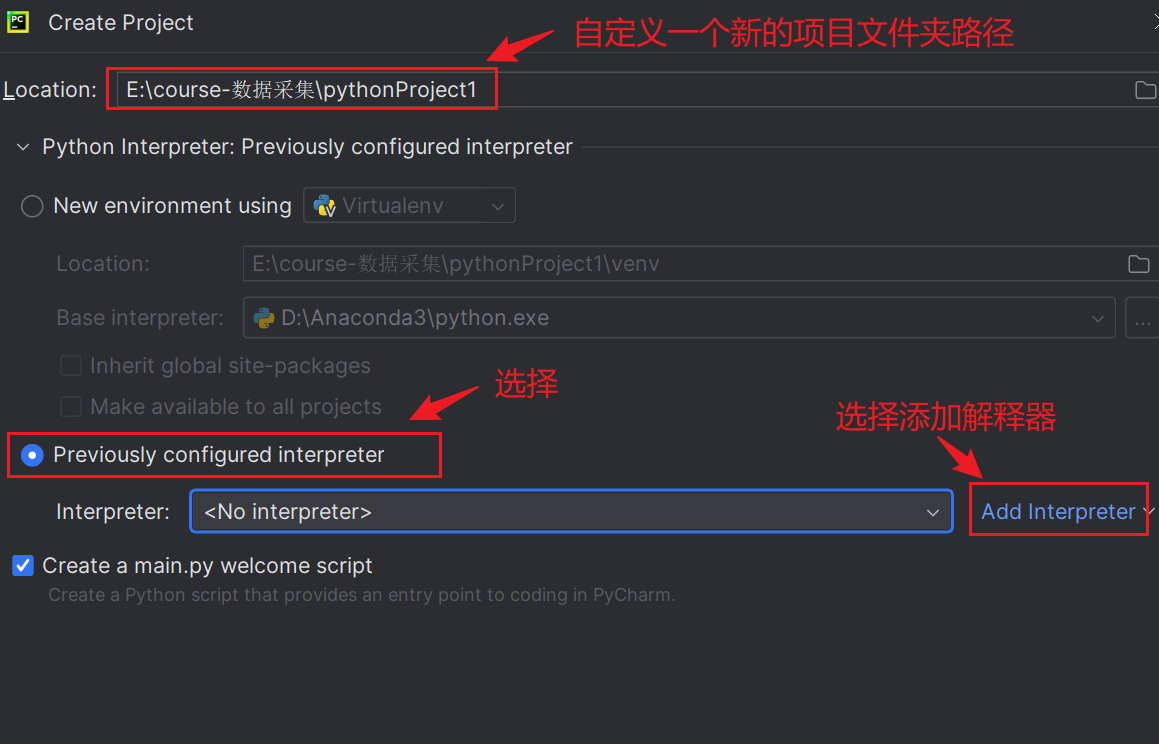
3,add python Interpreter窗口,选择system interpreter,单击右侧省略号
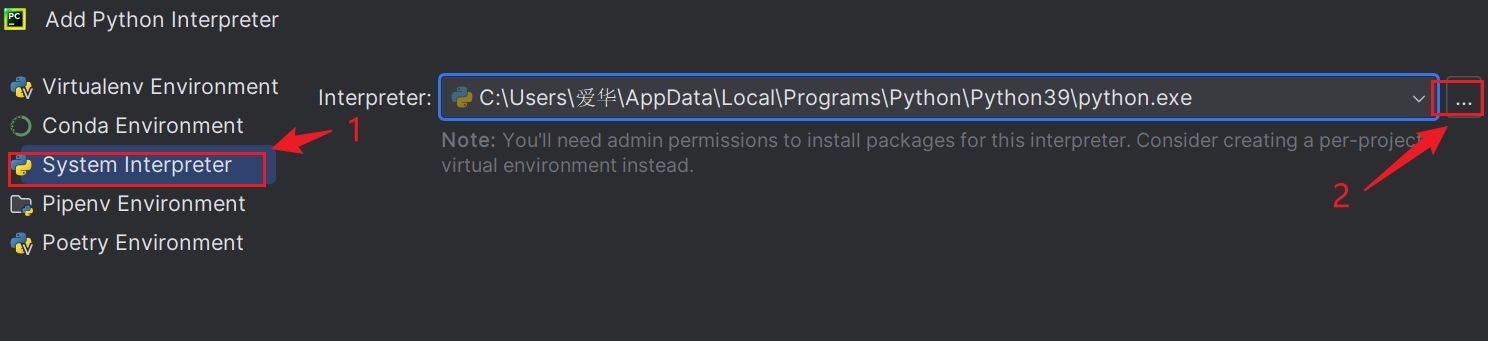
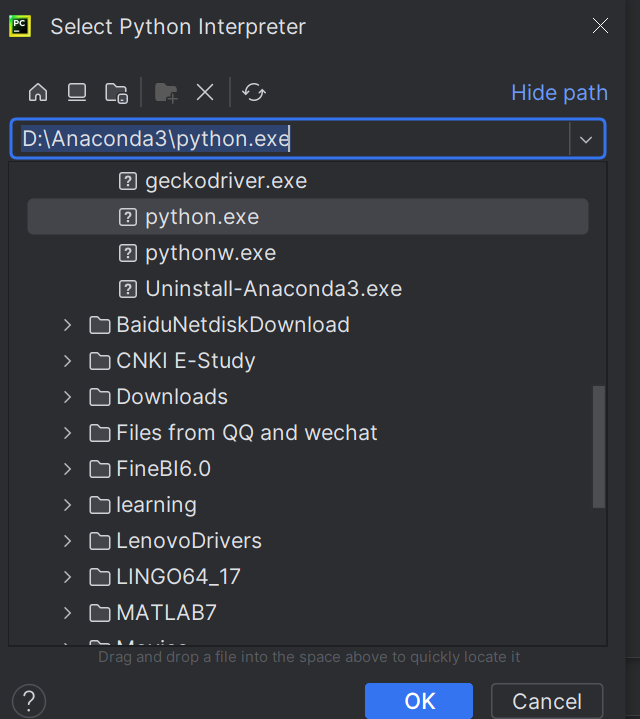
4,根据第一步查找到的路径,找到python解释器。按OK添加。按OK确认。按按create。创建新工程成功。
四、安装本课程必要的第三方库及插件(重要,务必提前配置安装)
1、安装第三方库
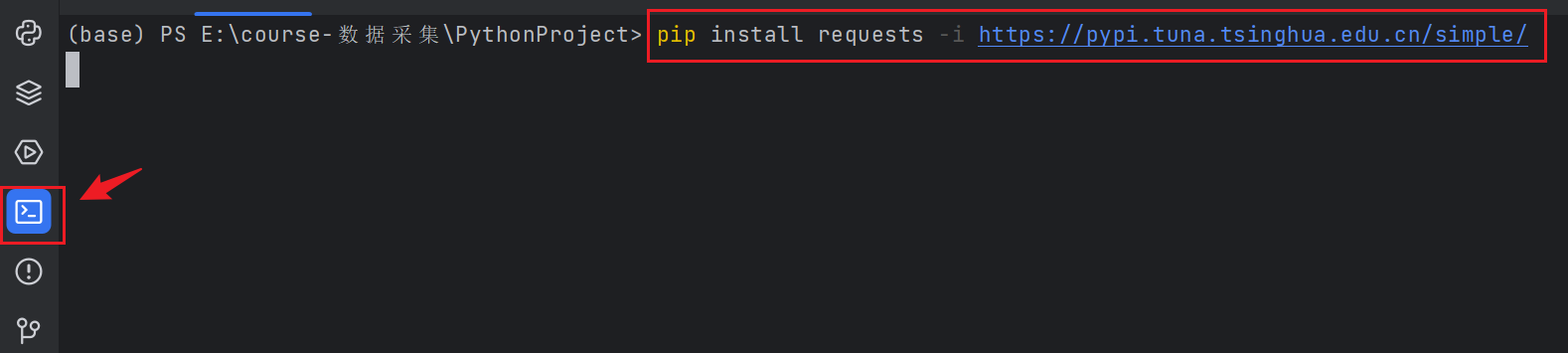
以安装requests库为例(其他库类似安装),打开pycharm,在terminal终端运行(或者在cmd终端/anaconda prompt终端运行):
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple/
需要安装的第三方库有:
(1)requests
(2)lxml
(3)beautifulsoup4
(4)parsel
(5)selenium
2、检验环境是否配置成功:
在当前工程文件夹下面,新建test.py文件,执行以下代码。若能成功运行,说明环境配置成功。
(1)单击工程文件夹,右键,选择:新建—Python File—test.py文件
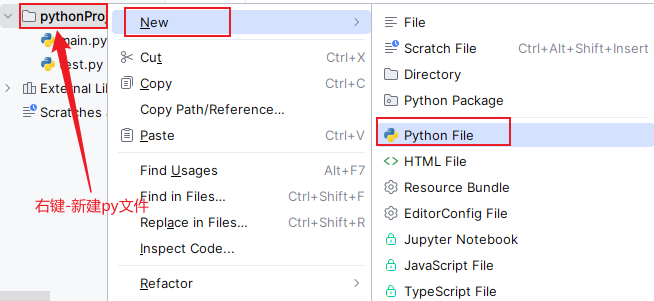
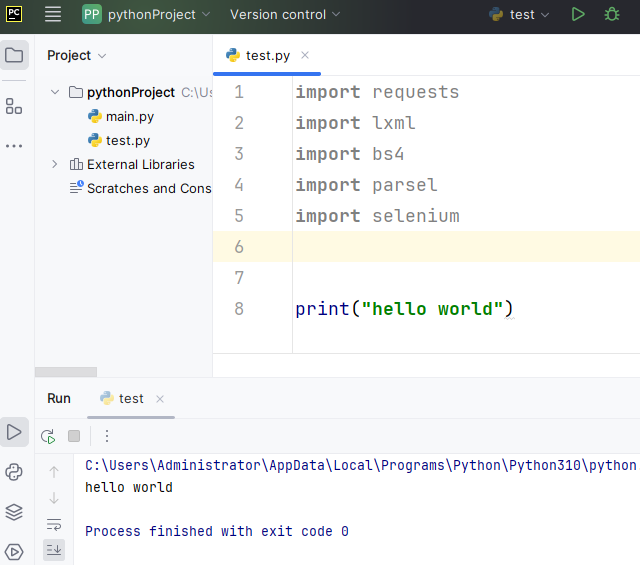
(2)在test.py文件中输入以下测试代码:
import requests
import lxml
import bs4
import parsel
import selenium
print("hello world")
(3)在代码区单击右键(或者单击运行按钮)—Run 'test' 运行当前文件。
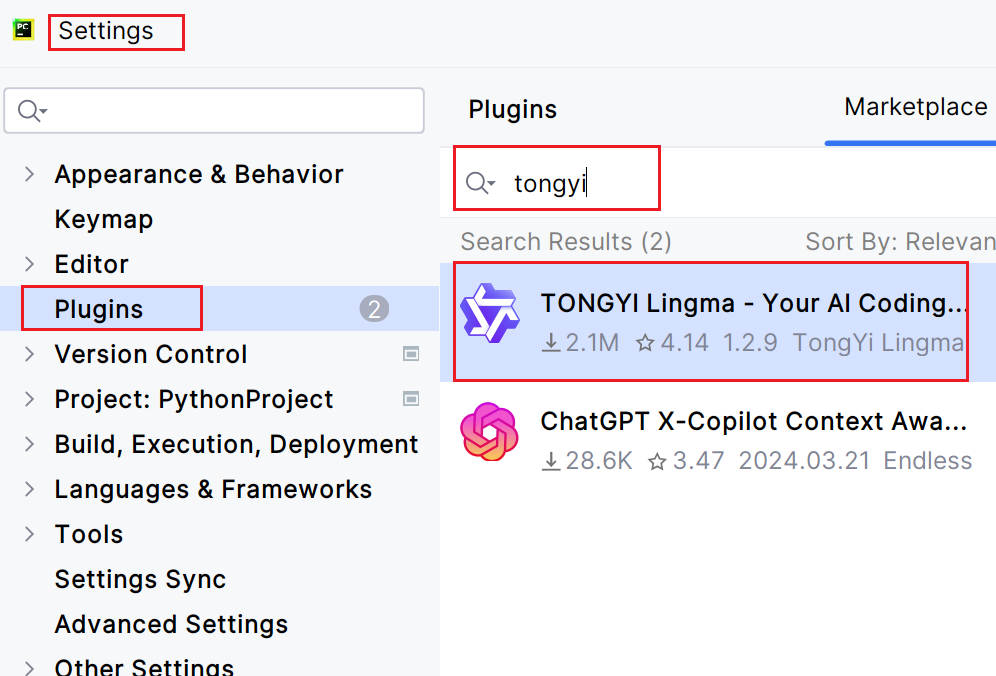
3、推荐安装插件:
(1)AI助手:TONGYI Lingma
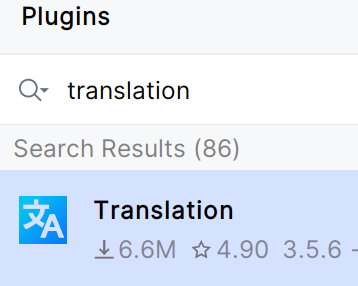
(2) 翻译插件:Translation
(3)汉化插件 Chinese (Simplified) Language Pack (可选)
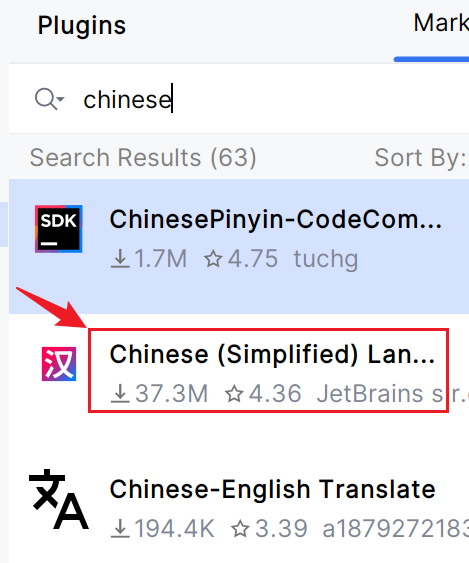
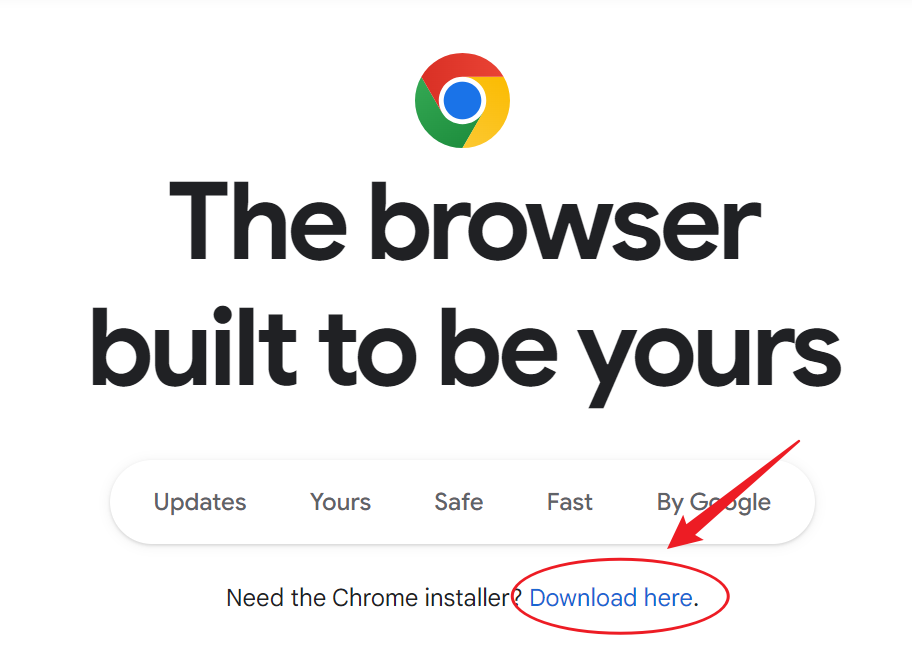
五、下载google浏览器及浏览器驱动(参考6.4.1小节)(不用安装)
google浏览器下载地址:
https://www.google.cn/intl/en_uk/chrome/
下载驱动:
https://chromedriver.chromium.org/downloads
驱动下载参考博文:
六、安装截图软件:snipaste(可选)
移步资料模块下载使用
七、安装vscode
下载地址:
https://code.visualstudio.com/