
Spark SQL
上一节
下一节
5.1 Spark SQL
1、Spark SQL
Spark SQL是Spark生态系统中非常重要的组件,其前身为Shark。Shark是Spark上的数据仓库,最初设计成与Hive兼容,但是该项目于2014年开始停止开发,转向SparkSQL。Spark SQL全面继承了Shark,并进行了优化。
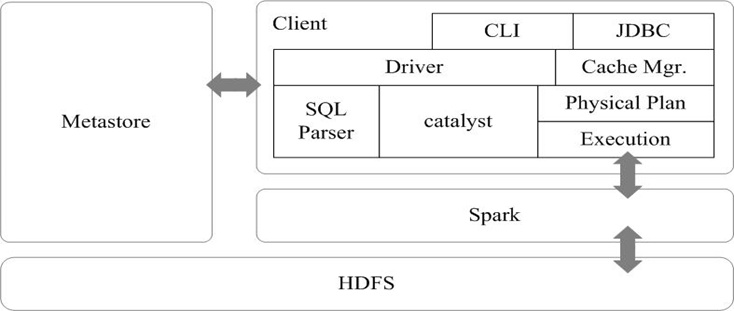
2、Spark SQL增加了Schema RDD
Spark SQL增加了SchemaRDD(即带有Schema信息的RDD),使用户可以在Spark SQL中执行SQL语句,数据既可以来自RDD,也可以来自Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据。SparkSQL目前支持Scala、Java、Python三种语言,支持SQL-92规范。从Spark1.2 升级到Spark1.3以后,Spark SQL中的Schema RDD变为了DataFrame,DataFrame相对于SchemaRDD有了较大改变,同时提供了更多好用且方便的API
Spark SQL可以很好地支持SQL查询,一方面,可以编写Spark应用程序使用SQL语句进行数据查询,另一方面,也可以使用标准的数据库连接器(比如JDBC或ODBC)连接Spark进行SQL查询,这样,一些市场上现有的商业智能工具(比如Tableau)就可以很好地和SparkSQL组合起来使用,从而使得这些外部工具借助于SparkSQL也能获得大规模数据的处理分析能力。

